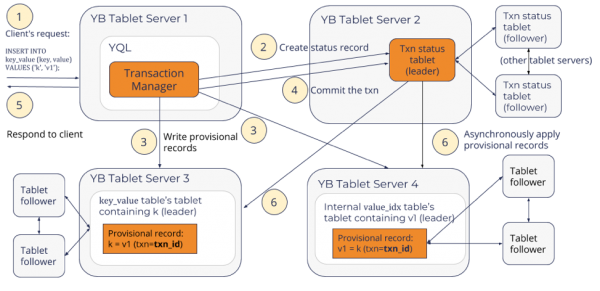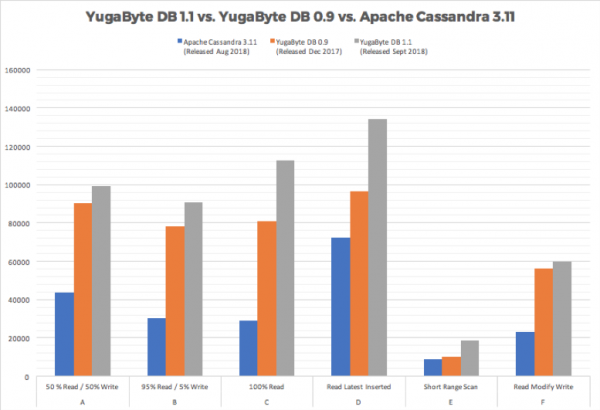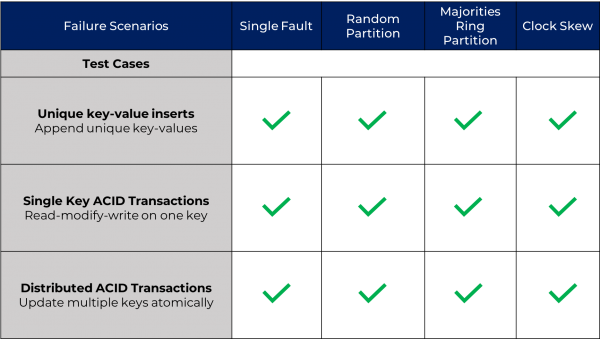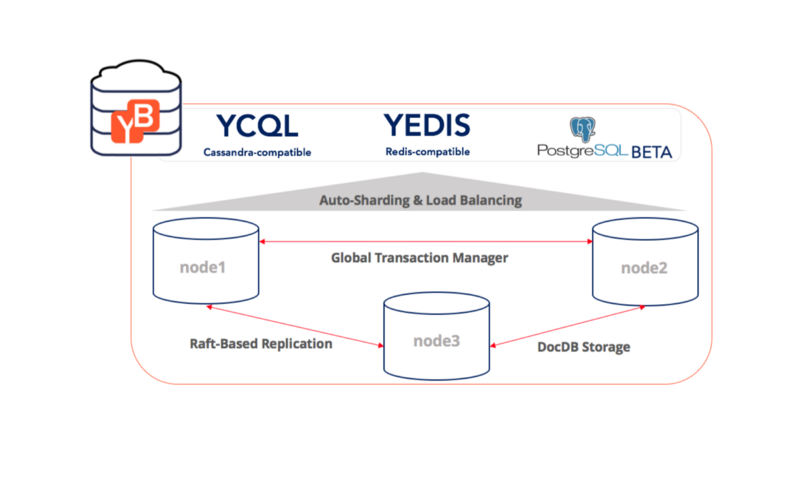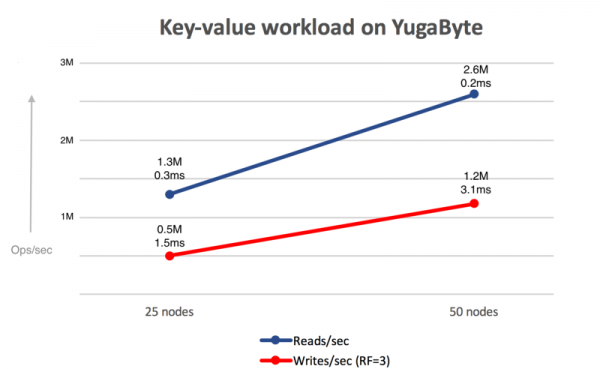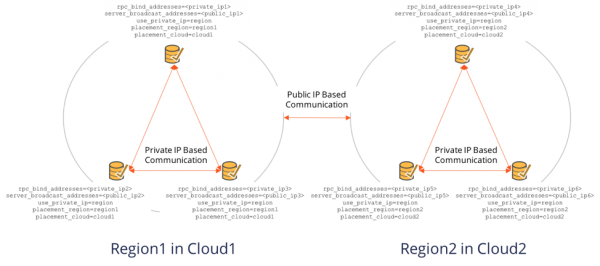
YugabyteDB 1.1 New Feature: Public IPs to Simplify Multi or Hybrid Cloud Database Deployments
Welcome to another post in our ongoing series that highlights new features from the latest 1.1 release announced last week. Today we are going to look at the importance of public IP addresses and hostnames in simplifying multi-cloud and hybrid cloud deployments.
In modern cloud deployments, servers often have a combination of private IP addresses (used in the private LAN and often the IP address of the network interface on the server),
…