What is Database Geo-Distribution?
Enable low latency with data resiliency from zone and region failures
Database geo-distribution is when a database spreads across two or more geographically distinct locations and runs without degraded transaction performance. It is impossible to predict the data needs of future applications. However, with database geo-distribution, data infrastructure is future proof. Therefore, it frees developers to pick a deployment option best suited to meet an application’s needs.
More specifically, there are three common database geo-distribution approaches to deploying applications:
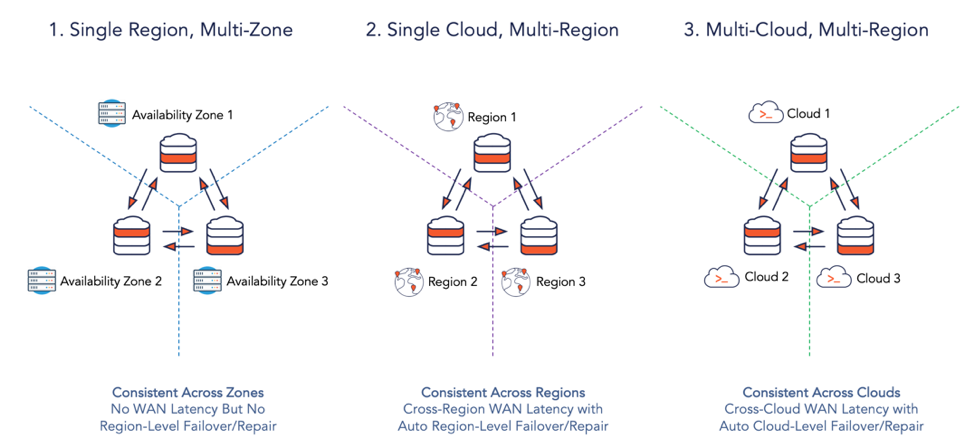
- Single Region, Multi-Zone: An application distributed across multiple availability zones in a single region for automatic tolerance to zone failures.
- Single Cloud, Multi-Region: An application distributed across multiple regions of a single cloud. This allows for automatic tolerance to region failures, low latency reads for local users, and compliance with data governance regulations (e.g., GDPR).
- Multi-Cloud, Multi-Region: An application distributed across multiple clouds for automatic tolerance to cloud failures. It also supports hybrid cloud deployments (involving on-premise data centers).
Why Database Geo-Distribution?
Customers today expect always-on, highly responsive access to services wherever they are in the world. As a result, this is driving businesses to deploy globally distributed applications that deliver better customer experiences.
Moving data closer to where end-users are enables lower latency access. Even better, database geo-distribution makes the data service resilient to zone and region failures in the cloud. Recent adverse weather conditions and data center accidents have underscored this need.
But database geo-distribution adds a critical layer of globally-consistent replication. This is a key need for consumer-facing applications in multiple verticals including Retail, Gaming, and Financial Services where users are located all around the world. Since the database tier no longer acts as a bottleneck, the entire application stack can now move from one maturity level to another in lock step.
Additional Geo-Distributed Deployment Options
Below are some important deployment options development teams can use to get the most out of database geo-distribution.
Multi-Region “Stretched” Clusters with Synchronous Replication
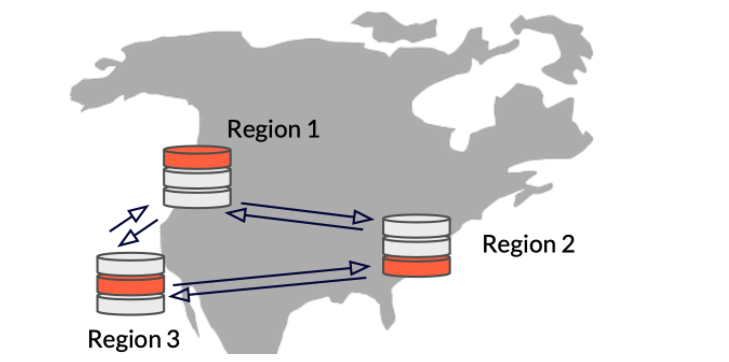
This option is similar to Single Region, Multi-Zone except that the nodes of the cluster are deployed in different regions rather than in different zones of the same region.
Multi-Region Clusters with Single-Direction Asynchronous Replication
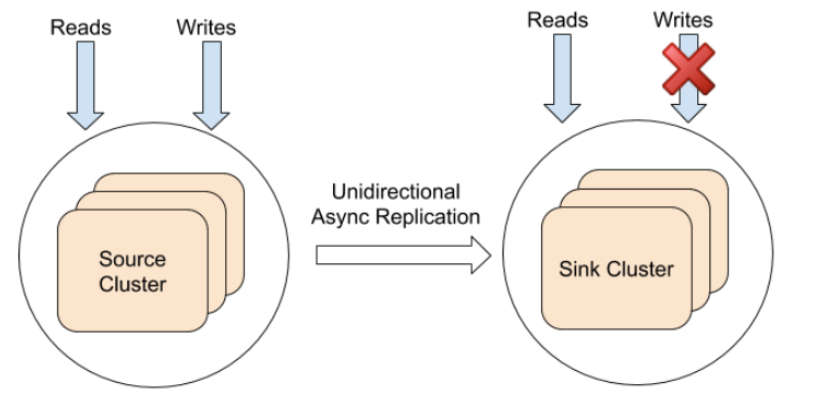
The previous option offered ways to deploy a single distributed database cluster across zones or regions. A geo-distributed database offers asynchronous replication across two data centers or cloud regions. This allows for situations where applications want to keep data in multiple clouds or in remote regions.
Multi-Region Clusters with Bi-Directional Asynchronous Replication
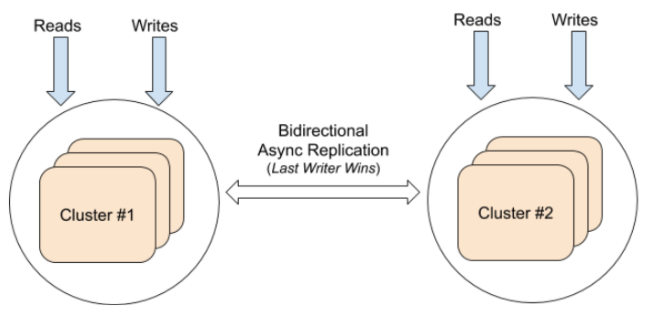
In addition to the active-passive configuration with one-directional replication, database geo-distribution provides an active-active configuration. This means both clusters can handle writes to potentially the same data. Writes to either cluster are asynchronously replicated to the other cluster with a timestamp for the update.
Geo-Partitioning with Data Pinning
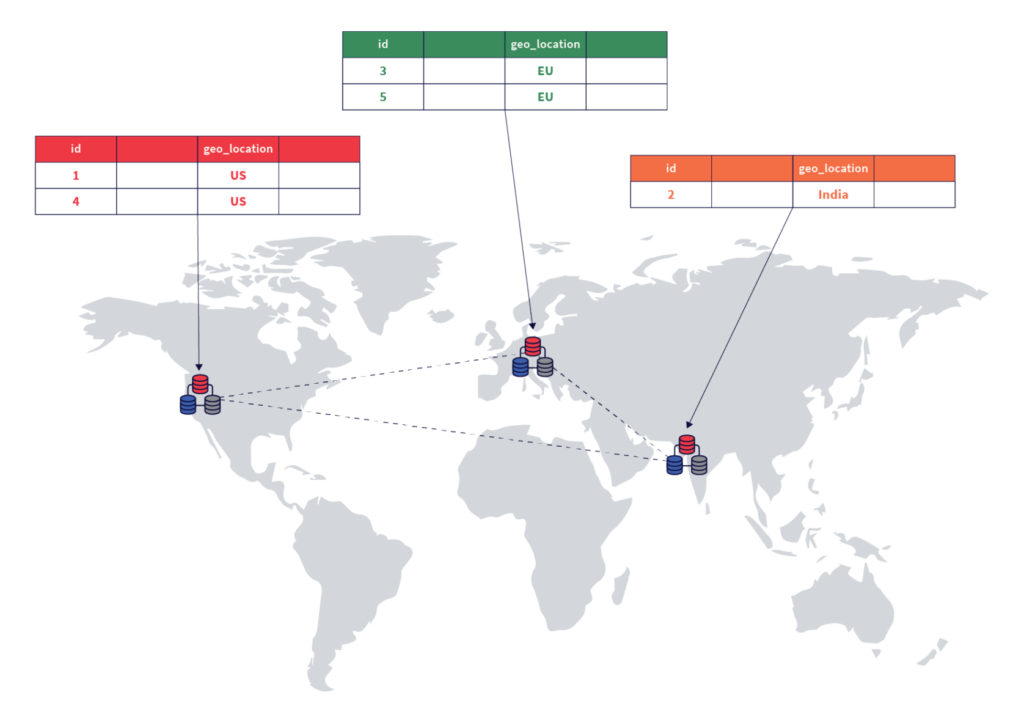
Applications that need to keep user data in a particular geographic region to comply with data sovereignty regulations can use row-level geo-partitioning. This allows fine-grained control over pinning rows in a user table to specific geographic locations.
Read Replicas
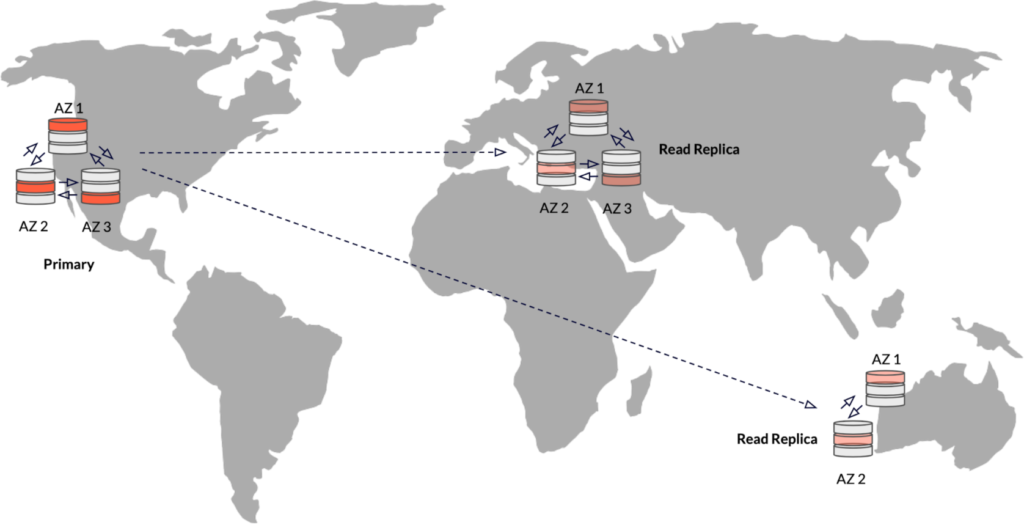
For applications that have writes happening from a single zone or region but want to serve read requests from multiple remote regions, you can use read replicas. Data from the primary cluster is automatically replicated asynchronously to one or more read replica clusters in the same universe.
Deploy Globally Distributed Applications Faster
Whether you are deploying a globally distributed application to serve customers around the world or looking for greater resilience, database geo-distribution offers a variety of deployment options that work for your application’s needs.
YugabyteDB offers the most comprehensive and flexible array of deployment and replication options in geo-distributed environments. Learn more about this powerful, open source database today through our free, self-paced courses: Introduction to Distributed SQL and Introduction to YugabyteDB. And join the YugabyteDB community to answer any and all of your distributed SQL questions.