9 Techniques to Build Cloud-Native, Geo-Distributed SQL Apps with Low Latency
October 17, 2019
This post is an in-depth look at the various techniques that applications needing low latency and high availability can leverage while using a geo-distributed SQL database like YugabyteDB so that the negative impacts of a high-latency, unreliable Wide Area Network (WAN) are minimized.
YugabyteDB also uses one process per connection, mirroring PostgreSQL’s protocol and query layer. This isn’t typically a scalability problem as connections can be spread across nodes. With YugabyteDB, all nodes are equal, accepting connections with read and write transactions. Ongoing work to add a database resident connection pool—based on Odyssey—aims to address applications without client-side connection pools and microservices with too many connection pools.
Distributed SQL is the Future of RDBMS
Enterprises are increasingly moving to cloud native applications powered by microservices architecture. These applications run on elastic cloud infrastructure such as serverless frameworks and containers. There are three common geographic distribution approaches to deploying such applications.
- Multi-zone – application is distributed across multiple availability zones in a single region for automatic tolerance to zone failures. Region-level fault tolerance requires a two-region deployment with a separate follower cluster in a second region.
- Multi-region – application is distributed across multiple regions of a single cloud for automatic tolerance to region failures, low latency reads for local users and compliance with data governance regulations such as GDPR.
- Multi-cloud – application is distributed across multiple clouds for automatic tolerance to cloud failures as well as to support hybrid cloud deployments (involving on-premises datacenters). For many cases, multi-cloud can be thought of as a special case of multi-region deployments.
Monolithic relational databases are losing their lustre when developing and operating applications described above. Non-scalable architecture, bolted-on failover/repair (with inherent data loss) and lack of native multi-zone/multi-region/multi-cloud replication are the top three fundamental limitations of such legacy databases. Geo-distributed SQL databases pioneered by Google Spanner and its open source derivatives such as YugabyteDB have emerged as credible alternatives.
Architecturally, geo-distributed SQL databases bring the same horizontal scalability and extreme resilience capabilities to the operational database tier that are now taken for granted in the microservices and cloud infrastructure tiers. They do so without compromising on SQL as a flexible data modeling and query language while also supporting fully-distributed ACID-compliant transactions. In addition to these basics, they add the critical layer of globally-consistent replication that is emerging as a key need for consumer-facing applications in multiple industries including retail and ecommerce, SaaS, gaming and financial services which have users located all around the globe. Since the database tier no longer acts as a bottleneck, the entire application stack comprised of microservices, databases, and cloud infrastructure moves from one maturity level to another in cadence.
Why Wide Area Network Latency is a Concern?
Any engineer who understands the basics of geo-distributed SQL immediately infers that database queries that were previously served by the single node of a monolithic RDBMS can now require data stored in multiple nodes of a distributed SQL database. For single-cloud, single-region clusters with nodes in multiple availability zones interconnected through a high-speed network (as in the deployment scenario #1 of the figure below), query latency is not a big concern. However, latency becomes the top concern in multi-region and/or multi-cloud clusters because a high-latency WAN now comes into the picture. When the WAN is essentially the public Internet, the high latency issue is magnified further by the unreliability of the network.
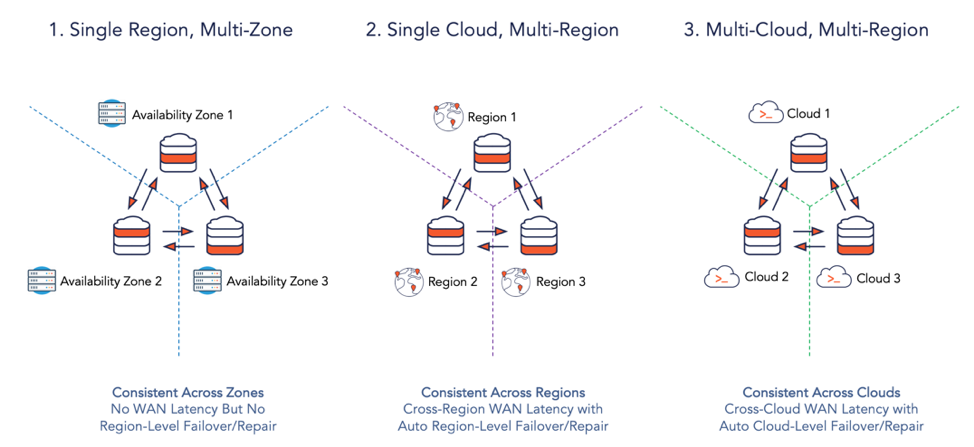
Figure 1: Most Common Deployment Scenarios for a Single Geo-Distributed SQL Cluster
Given the above deployment scenarios, an assumption takes shape that geo-distributed SQL is always slower than monolithic RDBMS and hence should be avoided as much as possible. However, thanks to design techniques available from academia as well as web-scale giants such as Google and Facebook, such an assumption is incorrect. This is especially true when we compare a distributed SQL cluster against a monolithic RDBMS instance that is already fully saturated with respect to write throughput and risks outages/slowdowns under additional load. This post highlights nine techniques that cloud-native applications can leverage in geo-distributed SQL databases to reduce inter-node as well as client-node communication. The end result is a reduction in inter-zone latency for multi-zone clusters and WAN latency for multi-region/multi-cloud clusters. These techniques are certainly hard to implement from a distributed systems engineering standpoint but nevertheless are necessary for geo-distributed SQL to power highly-scalable, latency-sensitive relational apps.
Low Latency in Single-Row Transactions
In the world of SQL, even single-row operations are implicitly treated as transactions. When this concept is applied to distributed databases, the result is the notion of linearizability (aka strong consistency). This is the same linearizability that the C in the CAP theorem refers to. Here’s a formal definition.
Linearizability:
Every read receives either the most recent write or an error. In other words, all members of the distributed system have a shared understanding of the value of a data element from a read standpoint.
Following are four techniques for reducing network traffic over WAN in a geo-distributed SQL cluster.
1. Linearizable Reads without Quorum
As ”Low Latency Reads in Geo-Distributed SQL with Raft Leader Leases” highlights, Raft distributed consensus when applied as-is to the world of geo-distributed clusters can lead to the Raft leader requiring a quorum with its followers before serving a linearizable read. For read-heavy geo-distributed applications such as a Retail Product Catalog or a Gaming Leaderboard, such a quorum essentially means WAN latency. The correct approach here is to enhance the basic Raft implementation with a comprehensive time-based leader lease mechanism that guarantees that there can be only one leader for a Raft group at any point of time. This leader can now serve linearizable reads from its local store and does not have to consult any follower replicas for quorum. Since replicas can be potentially in different regions, there is no impact of WAN latency for such read operations.
2. Follower Reads with Timeline Consistency
Not every read pattern in a geo-distributed application is created equal. For an e-commerce application, linearizable reads are a must-have for checking the password of a user logging into the application (since the user may have changed the password immediately before the login). However, for a logged-in user, personalized recommendations and product reviews do not require the most up-to-date information. Timeline-consistent data present in the follower replicas of the nearest region are a perfectly safe compromise since the slightly stale data present in these followers does not degrade user experience in any way. This notion is known as follower reads in a geo-distributed SQL database. Follower reads ensure that single-row read operations can be served from the nearest follower without incurring any additional cross-region latency.
3. Topology-Aware Client Drivers
SQL was invented in the monolithic era when a client application had to connect to only a single RDBMS node. Geo-distributed SQL could not be more different. Firstly, it involves a cluster of database nodes each with its own share of the overall data. Secondly each of these nodes can be in a different geographic region. How should a client application decide which database node to connect to? As shown in the figure below (using the PostgreSQL-compatible YugabyteDB database as an example), the traditional answer is to use a load balancer to hide the fact there are multiple geo-distributed nodes behind a single service and let the load balancer direct traffic to the nodes using a simple heuristic like round robin.
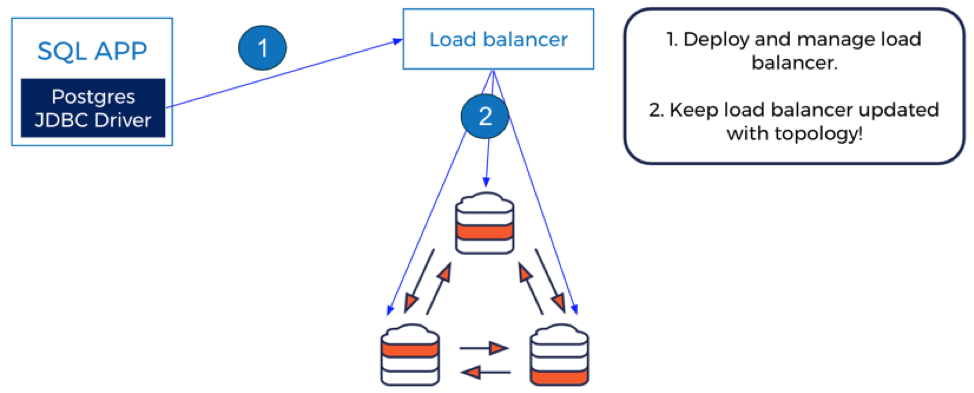
Figure 2: Postgres JDBC Driver used with YugabyteDB Cluster using a Load Balancer
Since load balancers were created in the stateless application era they do not solve the problem of correctly routing requests to the node holding the data. If the data is not present in the node serving the traffic from the load balancer, the database cluster will have no choice but to add a mandatory extra hop to the correct node, albeit transparently to the application logic and load balancer. The net result is high latency.
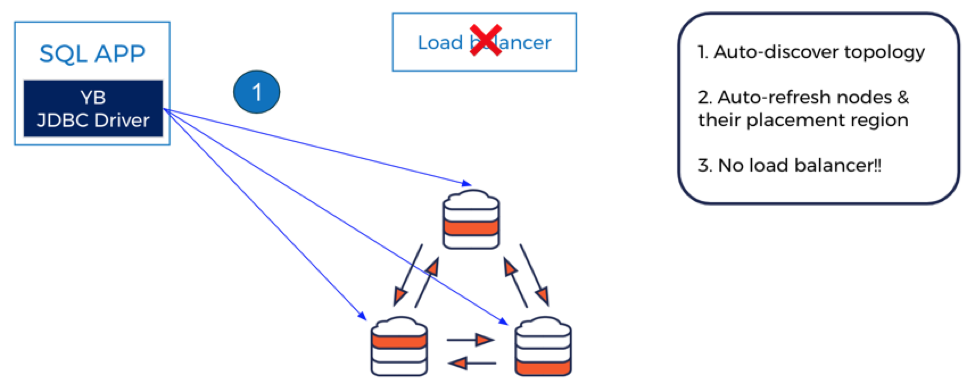
Figure 3: YugabyteDB JDBC Driver used with YugabyteDB Cluster without a Load Balancer
The ideal solution should be such that client applications are no longer responsible for knowing the location of the data. Additionally, operations engineers should not be required to create load balancers simply because there are multiple nodes. Enter smart client drivers. As shown in the figure above (using YugabyteDB as an example), the database client driver should have the smartness to connect to the right nodes. In a single-region cluster this would imply partition awareness and cluster awareness, leading to direct connection with the node hosting the desired partition. In a multi-region cluster, this would imply additional topology awareness, thus ensuring clients are able to access nodes in the nearest region first. Clients should rely on other distant regions only if the nearest region is experiencing an outage or slowdown.
4. Geo-Partitioning
Making the nodes of a multi-region database cluster aware of the location characteristics of the data they store is arguably the most intuitive way to handle the WAN latency problem. Linearizable reads now become entirely local to the nearest region while writes continue to incur cross-region latency (in return for auto region failover). Enter geo-partitioning where shards are partitioned according to a user-specified column that maps ranges to nodes in specific regions.
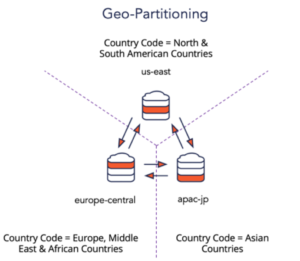
Figure 4: Geo-Partitioning in Distributed SQL Databases
As shown in the above example, a cluster that runs across 3 regions in the US, EU and Asia Pacific can rely on the Country_Code column of the User table to map a given user’s row to the nodes in the nearest region that is in conformance with GDPR rules. Follower replicas would then be placed in the regions nearest to the local region thus ensuring automatic failover when the local region fails.
Low Latency in Multi-Row Transactions
Even though NoSQL databases such as Amazon DynamoDB and FoundationDB are starting to make single-row operations transactional, application developers continue to gravitate towards geo-distributed SQL databases. There are two reasons for this natural affinity. First is the support for distributed ACID transactions through coordination of transactions across multiple rows/shards (that also involves tracking clock skews across multiple regions). Second is the inherent power of SQL as a data modeling language that effortlessly models multi-row operations. For example, SQL supports both explicit (e.g. BEGIN and END TRANSACTION syntax) and implicit (e.g. secondary indexes, foreign keys and JOIN queries) distributed transactions. The following techniques help geo-distributed SQL databases avoid WAN latency in the context of multi-row transactions.
5. Preferred Region for Shard Leaders
If application reads including multi-row JOINs are known to be originating dominantly from a single region, then a three-region distributed SQL cluster can be configured to have the shard leaders pinned to that single region. For example, us-east is the preferred region for the multi-region cluster shown below.
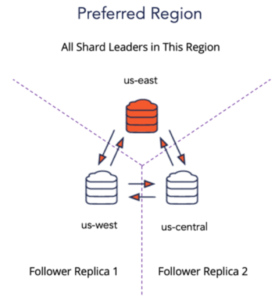
Figure 5: Preferred Region Configuration for a Multi-Region Cluster
Assigning a second region as an additional preferred region would still be better than having the shard leaders evenly distributed across all three regions for this specific case. The non-preferred regions will be used only for hosting shard follower replicas. Note that cross-region latencies are unavoidable in the write path given the need to ensure region-level automatic failover and repair.
6. JOINs Powered By Follower Reads
Similar to single-row reads powered by follower replicas, even multi-row JOINs can also be powered entirely by follower replicas in the nearest region. Since the data will be timeline-consistent, the application semantics have to allow for reads with slightly stale data. The benefit is that such multi-row JOINs will not incur any WAN latency.
7. Read-only Replicas
Read-only replicas can be thought of as observer replicas in the same cluster that neither vote for shard leaders nor are used for committing writes. A cluster can use such replicas to scale its read capacity without increasing the quorum size needed for writes. They are usually instantiated as a set of nodes located in one or more remote regions. They hold a full copy of the data that is asynchronously copied from the leader and follower replicas.
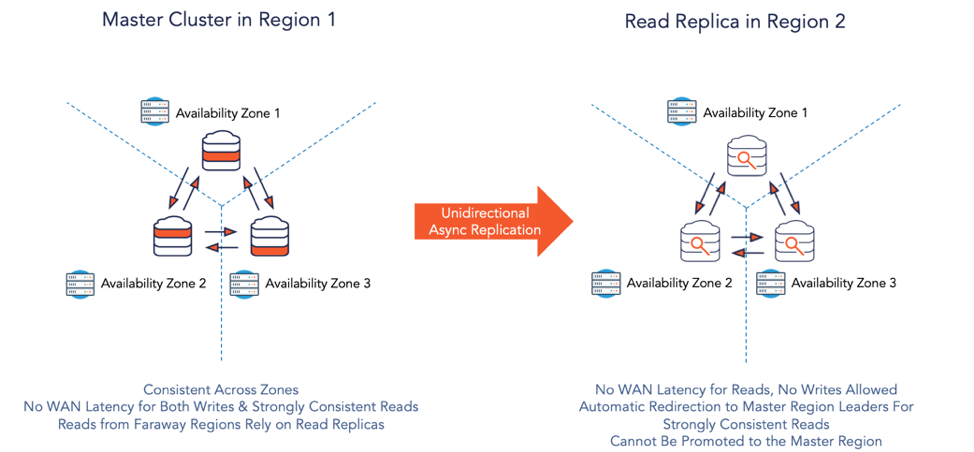
Figure 6: Read Replica in a Remote Region
Read-only replicas reduce WAN latency for reads because they serve timeline-consistent reads without needing a round-trip to the default leader region, assuming a configurable bounded staleness. If the data is older than this bound, then the replica automatically forwards the request to the leader thereby serving a strong read instead of a timeline-consistent read.
8. Colocated/Co-partitioned/Interleaved Tables
The traditional RDBMS approach of modeling parent-child relationships as foreign key constraints can lead to high-latency JOIN queries in a geo-distributed SQL database. This is because the shards containing the child rows may be hosted in nodes/zones/regions different than the shards containing the parent rows. There are three ways to make sure that the leaders of these shards are located on the same node, thereby the same zone and region).
- Colocated tables – These tables share the same shard and hence managed by the same Raft group. Colocation can also be at the overall database level where all tables of a single database are located in the same shard and managed by the same Raft group.
- Co-partitioned tables – These tables share one or more common partition key columns and are partitioned/sharded on the same boundary. The related rows from the parent and child tables are guaranteed to be on the same shard and hence managed by the same Raft group. On disk however, the parent and child rows are stored separately.
- Interleaved tables – Child rows are physically located inside the parent row. For example, let’s say we have a hierarchy of three tables, namely Singers, Albums and Songs. The figure from Google Cloud Spanner below shows the interleaving of the child rows inside the parent row.
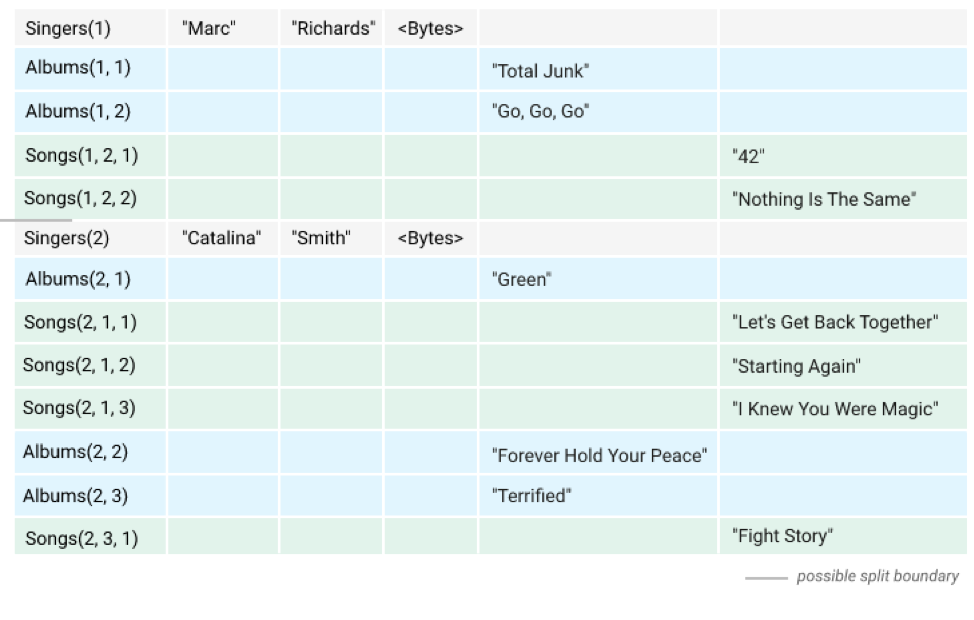
Figure 7: Example of interleaved tables (Source – Google Cloud Spanner Docs)
9. Two-Region Deployments
What if we want horizontal write scalability, native zone failover and repair, plus high performance, all within a single master region? What if we also want to have a secondary region acting as a failover/follower region for disaster recovery (as shown in Figure 8 below)? And want the secondary region to act as another master for the same data (as shown in Figure 9 below)? The prerequisite here is that the application has to be architected to handle the downsides of unavailability of recently committed data in the master-follower configuration as well as account for potentially conflicting writes in the master-master configuration.

Figure 8: Master-Follower Two-Region Deployment
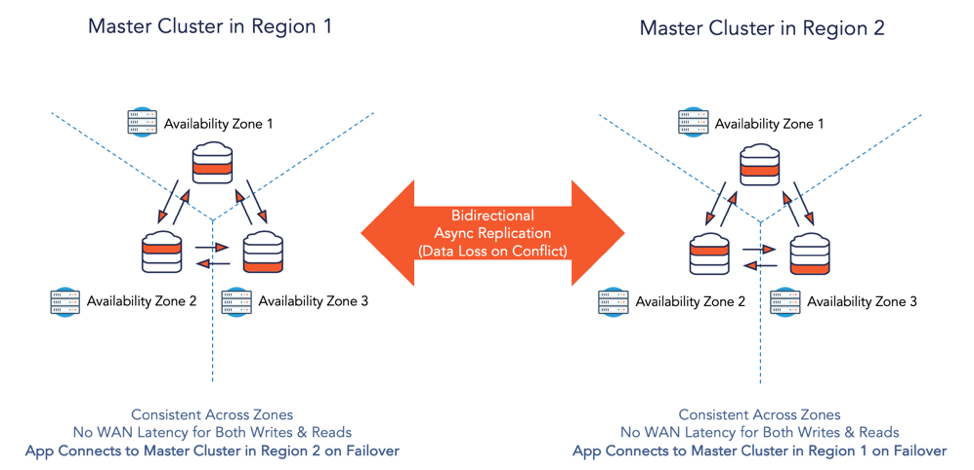
Figure 9: Multi-Master Two-Region Deployment
Note that the mandatory “three or more regions” requirement inherent to Spanner-inspired databases has meant that the above-mentioned two-region deployments are considered impossible. YugabyteDB is the first geo-distributed SQL database to make this impossible feat now possible with its recent 2.0 release. Both multi-master and master-follower configurations are now supported. While the nodes inside the “master” clusters use Raft-based synchronous replication, the cross-region configurations use asynchronous replication that builds on top of Change Data Capture (CDC) streams.
Summary
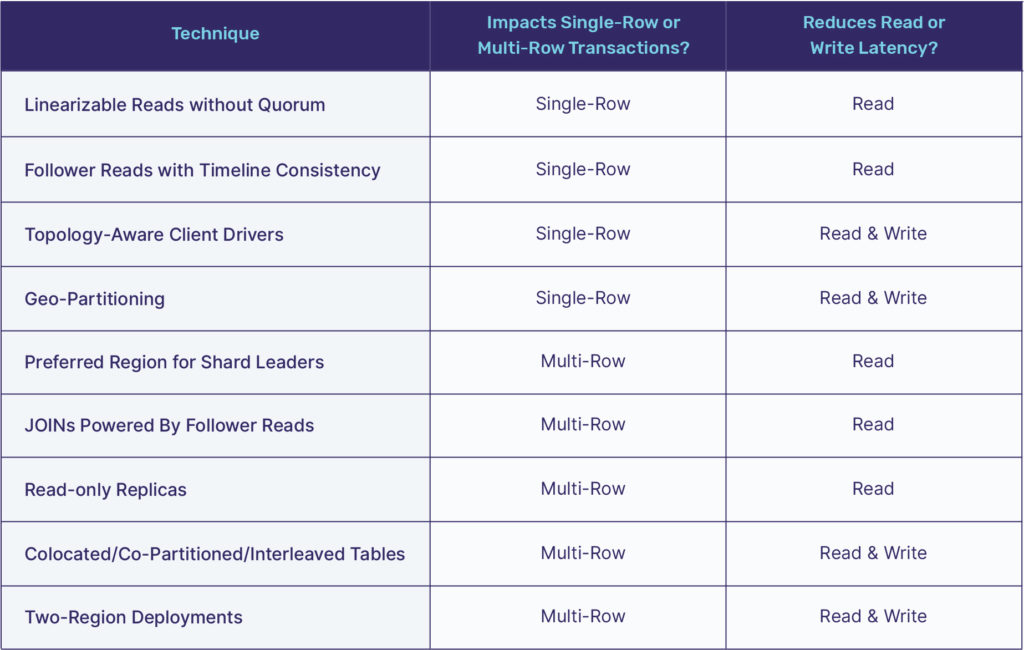
The nine techniques we reviewed for reducing multi-region WAN latency in cloud-native, geo-distributed SQL applications can be summarized as shown in the table below. All these techniques reduce read latency while majority of them also help in reducing write latency. And in most real-world deployments, multiple of these techniques would be used simultaneously. One such example would be to use topology-aware drivers and geo-partitioning along with colocated/co-partitioned/interleaved tables. This would ensure that a single multi-region cluster can serve fully-relational applications with the lowest latency possible.
While it may be easy to believe the simplistic theory that geo-distributed SQL databases are slow, careful analysis demonstrates that geo-distributed SQL offers developers multiple techniques to take control of the WAN latency problem. We are in the golden age of transactional databases where small and large enterprises alike can engineer applications to benefit from the scalability of the database layer without compromising on the high performance that is usually demanded from such a layer.
What’s Next?
- Compare Yugabyte DB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with Yugabyte DB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


