Geo-Distribution in YugabyteDB: Engineering Around the Physics of Latency
May 10, 2023
Customers expect always-on and highly responsive access to services, regardless of their geographical location. To meet these expectations and provide superior customer experiences, businesses are building and deploying globally-distributed applications.

A fundamental component of this strategy is the transition to a geo-distributed database. By placing data in close proximity to end-users, businesses can deliver better customer experiences thanks to low-latency data access. Additionally, geo-distribution makes data access resilient to zone and regional cloud failures. Yearly occurrences of severe weather and data center incidents has made this approach necessary.
Database architects and operators can choose from a rich set of deployment and replication options in YugabyteDB to build the optimal geo-distributed environment. While there is no getting around the physics of network latency, Yugabyte customers such as Admiral, Kroger, and Narvar have achieved their resilience, performance, and compliance objectives using the wide array of built-in synchronous and asynchronous data replication and granular geo-partitioning capabilities.
In this blog post, we look at geo-distributed deployment topologies offered with YugabyteDB that can future-proof your data infrastructure and support your app’s needs. We also offer a video version of this blog that you can access at the end of this blog. Before we dive into the details, here is a summary of six geo-distributed database deployment options that YugabyteDB offers.
Let’s look at each one in detail.
1. Single Region Multi-Zone Cluster
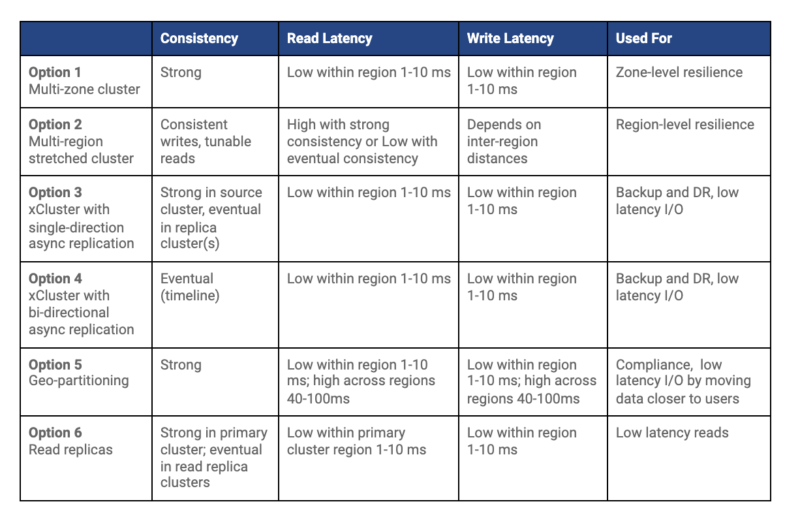
A YugabyteDB cluster consists of three or more nodes that communicate with each other and distribute data across them. It is possible to allocate the nodes of a YugabyteDB cluster in different availability zones within the same region. This topology delivers several benefits.
Resilience: Cloud providers like AWS and Google Cloud design zones to minimize the possibility of correlated failures caused by physical infrastructure outages such as power, cooling, or networking issues. In other words, in the event of a single failure, only one zone is typically affected. By deploying nodes across multiple zones within a region, you gain both resilience to zone failure and high availability.
Consistency: YugabyteDB automatically shards the tables of the database, which means it seamlessly distributes data across the nodes and replicates all writes synchronously. As a result, the cluster guarantees strong consistency of all I/O with distributed ACID transactions.
Latency: Due to the close proximity of the zones to each other, clients situated in the same region as the cluster enjoy low read and write latencies. Typically, simple row access results in a latency of 1 – 10ms.
Use this deployment mode if you:
- Need strong consistency for your applications
- Need resiliency and high availability (HA)—zero RPO and near-zero RTO
- Have clients in the same region so they can benefit from low read and write latencies.
Tradeoffs with multi-zone deployments include:
- Higher read/write latencies for applications accessing data from remote regions
- Lack of resilience in the case of region-level outages, such as those caused by natural disasters like floods or ice storms.
2. Multi-Region “Stretched” Clusters With Synchronous Replication
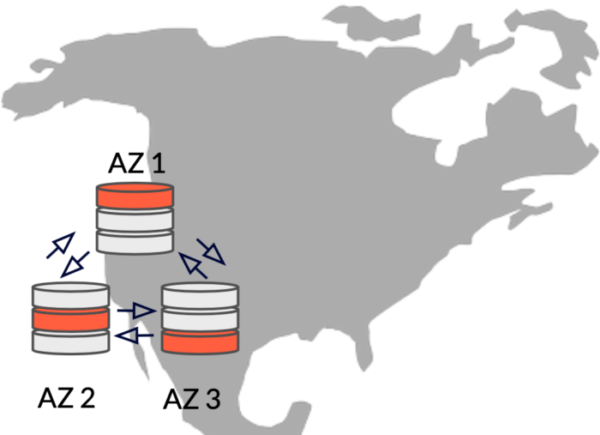
The second option is similar to the first one except that the nodes of the cluster are deployed in different regions rather than in different zones of the same region.
Resilience: Placing cluster nodes in different regions offers an even greater level of failure independence than when placed in different zones. In the event of a failure, the database cluster continues to serve data requests from the remaining regions, while automatically replicating data in the background to maintain the desired level of resilience.
Consistency: As with a zone deployment, all writes are synchronously replicated. Transactions in these two configurations are also globally consistent.
Latency: In a multi-region cluster, latency is largely dependent on the network packet transfer times between the nodes of the cluster and the client. To mitigate this issue, YugabyteDB offers tunable global reads that allow read requests to prioritize stronger consistency over lower read latency. By default, read requests in a YugabyteDB cluster are handled by the leader of the Raft group associated with the target tablet to ensure strong consistency. However, in scenarios where lower consistency is acceptable in favor of lower read latencies, you can choose to read from a tablet follower that is closer to the client than from the leader. With YugabyteDB, you can specify the maximum staleness of data when reading from tablet followers.
With this deployment mode, write latencies can be high due to the tablet leader replicating write operations across a majority of tablet peers before responding to the client. All writes involve cross-zone communication between tablet peers.
This deployment mode offers:
- Resilience and HA – zero RPO and near-zero RTO
- Strong consistency of writes, tunable consistency of reads
Tradeoffs with multi-region deployments:
- Write latency can be high (depending on the distance//network packet transfer times)
- Follower reads trade off consistency for latency
3. Multi-Region Clusters With UniDirectional Asynchronous Replication
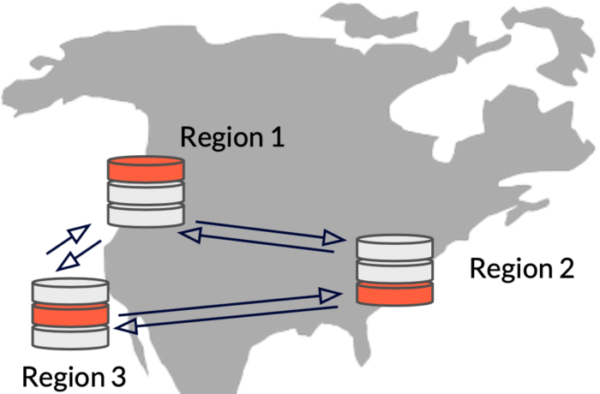
The first two options offered ways to deploy a single YugabyteDB cluster across zones or regions. If your applications need to store data in multiple clouds or in remote regions, YugabyteDB offers xCluster asynchronous replication across two data centers or cloud regions.
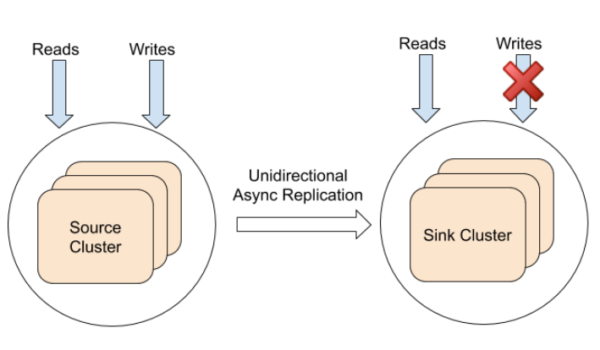
Here’s how it works:
1.Deploy two YugabyteDB clusters (typically) in different regions. Each cluster will automatically replicate data within that cluster synchronously to ensure strong consistency.
2. Set up xCluster asynchronous replication from one cluster to another. This can be either bi-directional, in an active-active configuration, or unidirectional (also referred to as single-directional) in an active-passive configuration. NOTE: We discuss the active-passive configuration here, while the active-active configuration is covered in Option 4.
Sink clusters can serve low-latency reads—which are timeline consistent—to nearby clients. They can also be used for disaster recovery. In the case the source cluster fails, the clients can simply connect to the replicated sink cluster.
xCluster asynchronous replication is ideal for use cases such as disaster recovery, compliance, and auditing. You can also use it to migrate data from a data center to the cloud or from one cloud to another. In situations that tolerate eventual consistency, clients in the same region as the sink clusters benefit from low latency reads.
Resilience: Deploying the nodes of each cluster across zones provides zone-level resilience and enables disaster recovery in case the source cluster fails.
Consistency: Reads and writes performed within the source cluster are strongly consistent. However, because replication across clusters occurs asynchronously, I/O will be timeline consistent.
Latency: With xCluster, replication to the remote cluster takes place outside the critical path of a write operation. This means that replication does not significantly impact latency of reads and writes. Essentially you are making a tradeoff between consistency and latency. In regions where the cluster is located, reads can be performed with low latency.
In summary, this deployment mode offers:
- Disaster recovery with non-zero RPO and RTO
- Eventual (timeline consistency) in the sink cluster and strong consistency in the source cluster
- Low latency reads and writes within the source cluster region
Tradeoffs with unidirectional async replication:
- The sink cluster does not handle writes, resulting in high latency for clients outside source cluster region
- Since xCluster replication bypasses the query layer for replicated records, database triggers won’t fire, which can lead to unexpected behavior
4. Multi-Region Clusters With Bi-directional Asynchronous Replication
As we saw in option 3, YugabyteDB offers xCluster asynchronous replication between clusters across data centers or cloud regions. In addition to the active-passive configuration with unidirectional replication, YugabyteDB also has an active-active configuration in which both clusters can handle writes to potentially the same data. Writes to either cluster are asynchronously replicated to the other cluster with a timestamp for the update. xCluster with bi-directional replication is typically used for disaster recovery.
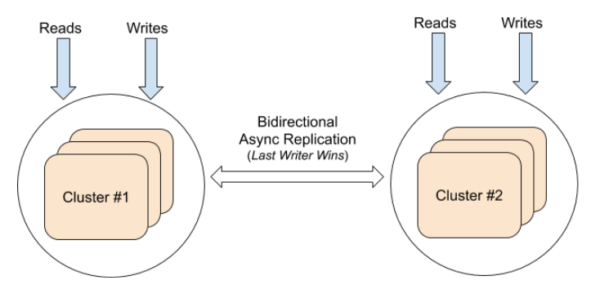
Resilience: Deploying the nodes of each cluster across zones provides zone-level resilience and enables disaster recovery in case the source cluster fails.
Consistency: If a cluster handles a write request, reads and writes within that cluster are strongly consistent. However, because replication across clusters is asynchronous, data replication to the remote cluster will be timeline consistent. If the same key is updated in both clusters at a similar time window, the write with the higher timestamp will become the latest write (last-writer-wins semantics).
Latency: With xCluster, replication to the remote cluster happens outside the write option’s critical path. As a result, the latency of reads and writes is not significantly impacted by replication. Essentially you are making a tradeoff between consistency and latency.
This deployment mode offers:
- Disaster recovery with non-zero RPO and RTO
- Strong consistency within the cluster that handles a write request and eventual (timeline) consistency in the remote cluster
- Low latency reads and writes within either cluster
Tradeoffs with bidirectional async replication:
- Since xCluster replication bypasses the query layer for replicated records, database triggers won’t fire, which can lead to unexpected behavior
- xCluster replication is done at the write-ahead log (WAL) level, so there is no way to check for unique constraints. Two conflicting writes in separate universes can violate the unique constraints, causing the main table to contain both rows but the index to contain only one row. This results in an inconsistent state.
- Active-active configurations don’t support auto-increment IDs since both universes will generate the same sequence numbers. This can result in conflicting rows, so it’s better to use UUIDs instead.
5. Geo-Partitioning With Data Pinning
With the growth in global apps, organizations often need to keep user data in a particular geographic region to comply with data sovereignty regulations. Or they may want to pin data to the specific region where it’ll most likely be accessed for lower read and write latencies. To address these growing needs, YugabyteDB offers row-level partitioning. With this feature, you have fine-grained control to pin rows in a user table to specific geographic locations.
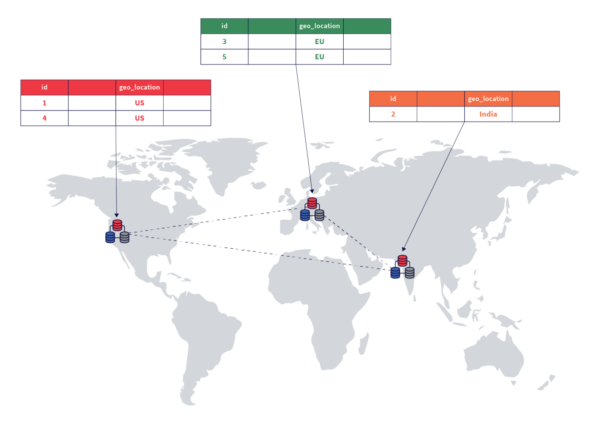
To implement row-level geo-partitioning:
1. Choose a column from the table that will serve as the partition column. This column could contain geographic information such as country or location name for each row in a user table.
2. Create partition tables based on the partition column of the original table. You will need to create a partition table for each region where you want to store data.
3. Pin each partition table to a different zone within the target region. This ensures that data is stored in specific geographic locations based on the partitioning of the original table.
By utilizing this deployment mode, the cluster will automatically maintain designated rows and all of the table shards, or “tablets,” within the specified region. Not only does this approach ensure adherence to data sovereignty regulations, but it also allows for low latency access to data from users in the region, while preserving transactional consistency semantics. For further elaboration on the functionality of row-level geo-partitioning, please refer to Geo-Partitioning of Data in YugabyteDB.
Resilience: Clusters with geo-partitioned tables are resilient to zone-level failures when the nodes in each region are deployed in different zones of the region.
Consistency: Because this deployment model employs a single cluster that spans multiple geographies, all writes are synchronously replicated to nodes in different zones of the same region, thus maintaining strong consistency.
Latency: Because all the shard replicas are pinned to zones in a single region, read and write overhead is minimal and latency is low. To insert rows or make updates to rows pinned to a particular region, the cluster needs to touch only shard replicas in the same region.
Row-level geo-partitioning is recommended for:
- Tables that require data to be pinned to specific geographic regions to comply with data sovereignty requirements
- Low latency reads and writes within the same region where the data is located
- Maintaining strongly consistent reads and writes
Tradeoffs with geo-partitioning:
- It is best suited for specific use cases where the dataset and access to the data can be logically partitioned. Examples include users in different countries accessing their accounts or localized products (or product inventory) in a product catalog.
- When users travel outside their pinned region, accessing their data will incur cross-region latency.
6. Read Replicas
If your application requires writes to occur from a single zone or region, but you want to serve read requests from multiple remote regions, you can utilize read replicas. The primary cluster’s data is automatically replicated asynchronously to one or more read replica clusters located within the same universe. While the primary cluster handles all write requests, read requests can be directed to either the primary cluster or the read replica clusters, depending on proximity.
Resilience: Deploying primary cluster nodes across multiple zones provides zone-level resilience. Read replicas do not participate in the Raft consistency protocol, meaning that they do not impact resilience.
Consistency: The data in the replica clusters is timeline consistent, which is better than eventual consistency.
Latency: Reads from both the primary cluster and read replicas can be quick with single digit millisecond latency, because read replicas can serve timeline-consistent reads without needing to involve the shard leader in the primary cluster. The read replica clusters do not handle write requests; they are redirected to the primary cluster. So the write latency is dependent on the distance between the client and the primary cluster.
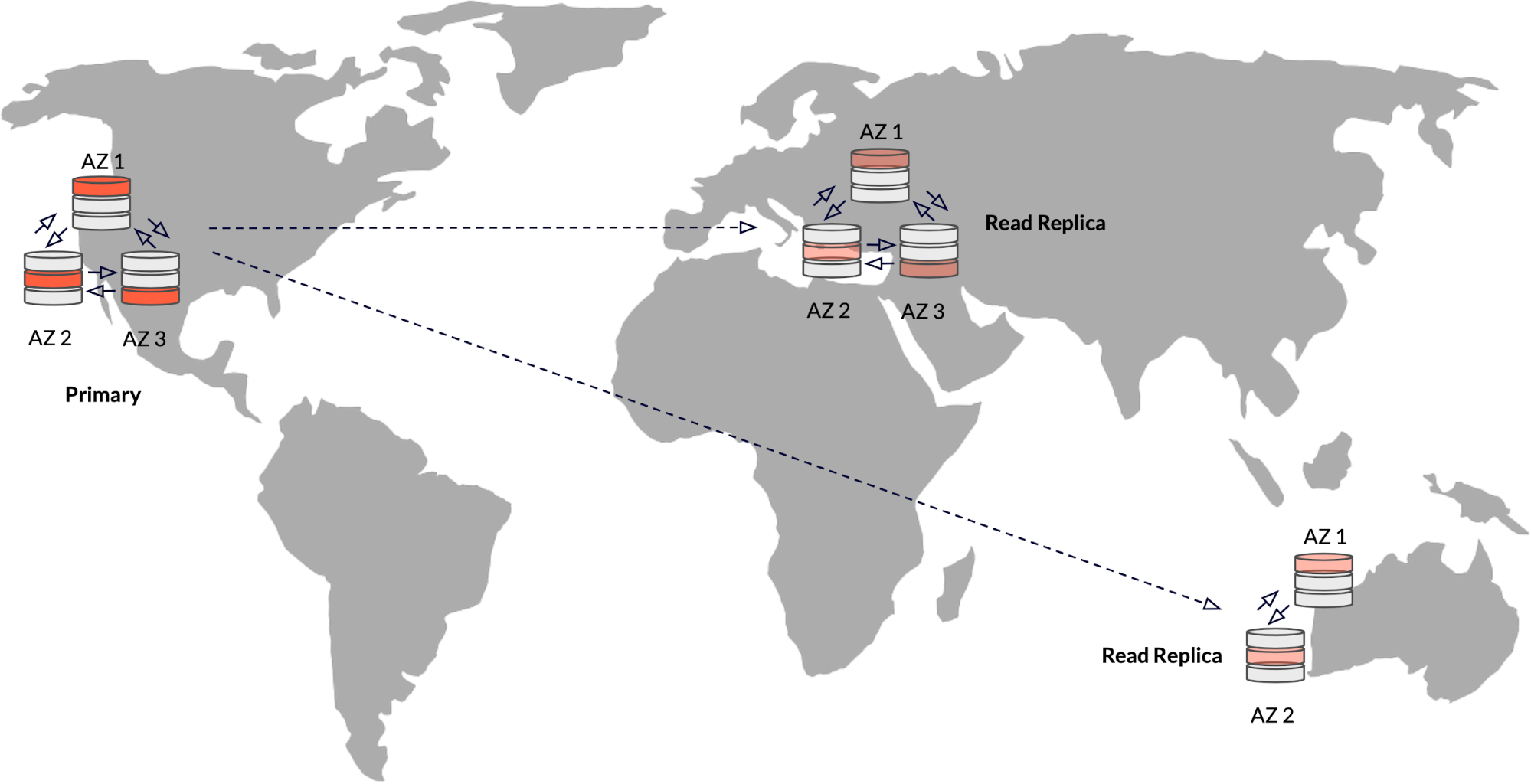
Read replicas are recommended for:
- Blazingly fast, timeline-consistent reads from replicas, and strongly consistent reads and writes to the primary cluster
- Low latency writes within the region
Tradeoffs with read replicas:
- The primary cluster and the read replicas are correlated (not independent) clusters. So adding read replicas does not enhance resilience.
- Read replicas cannot accept writes, which can result in high write latency from remote regions even if there is a read replica near the client.
Summary
YugabyteDB offers the most comprehensive and flexible array of deployment and replication options in geo-distributed environments. Whether you are deploying a globally distributed application to serve customers around the world and need a best-of-breed cross-region solution like xCluster or are looking for strong resilience and consistency within a region through synchronous replication, YugabyteDB delivers the right mix of deployment options to best fit your application’s needs. No other database offers the flexibility and freedom to meet different in-region and cross-region requirements while delivering strong consistency and cloud freedom.
If you are interested in learning more about geo-distribution in YugabyteDB, here are some additional resources:


