What is Database Sharding?
Prevent unplanned database outages while ensuring high availability at a low cost
Database sharding is the process of breaking up large database tables into smaller chunks called shards. A logical shard is a horizontal data partition that contains a subset of the total data set. It is responsible for serving a portion of the overall workload.
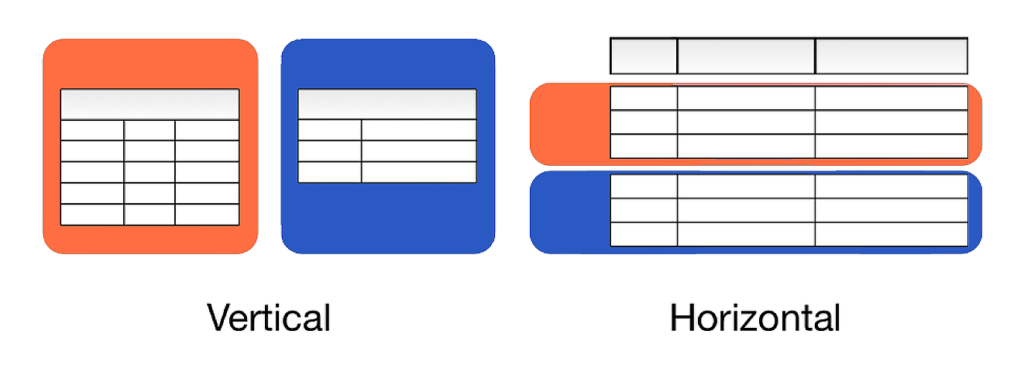
Database sharding is also referred to as horizontal partitioning. The distinction between horizontal and vertical partitioning comes from the traditional tabular view of a database.
Why Database Sharding?
Monolithic databases have limitations processing complex application workloads as they scale. With limited CPU, storage capacity, and memory, query throughput and response times suffer.
More specifically, database sharding enables application workloads to scale by:
- Freeing up compute capacity to serve incoming queries — End up with faster query response times and index builds
- Doing away with unplanned database outages — Ensure high availability, so if one or two database nodes go down, the rest of the database is still available
- Saving on server costs — A network of smaller, cheaper servers are more cost effective than maintaining a single server
The Perils of Manual Sharding
Disproportionate Data Distribution
One of the most significant challenges with manual sharding is uneven shard allocation. Disproportionate distribution of data can cause multiple shards to become unbalanced, with some overloaded while others remain relatively empty. It’s best to avoid accruing too much data on a shard because a hotspot can lead to slowdowns and database server crashes.
Complication Of Operational Processes
Finally, manual sharding can complicate operational processes. Backups will now have to perform for multiple servers. Data migration and schema changes must be carefully coordinated to ensure a database shard has the same schema copy. Without sufficient optimization, database joins across multiple servers can be highly inefficient and difficult to perform.
Common Database Sharding Architectures
Monolithic databases—such as Oracle Db2 and MySQL—do not support auto-sharding. This means applications need additional sharding logic to know exactly how data is distributed—and how it should be fetched. The net result is a massive decrease in developer productivity.
Over the years, different auto-sharding architectures and implementations have been used to build large-scale systems. These architectures include things like hash sharding, directory based sharding, range sharding and geo-partitioning. Let’s take a deeper look at three of the most common architectures for a sharded database:
Hash Sharding
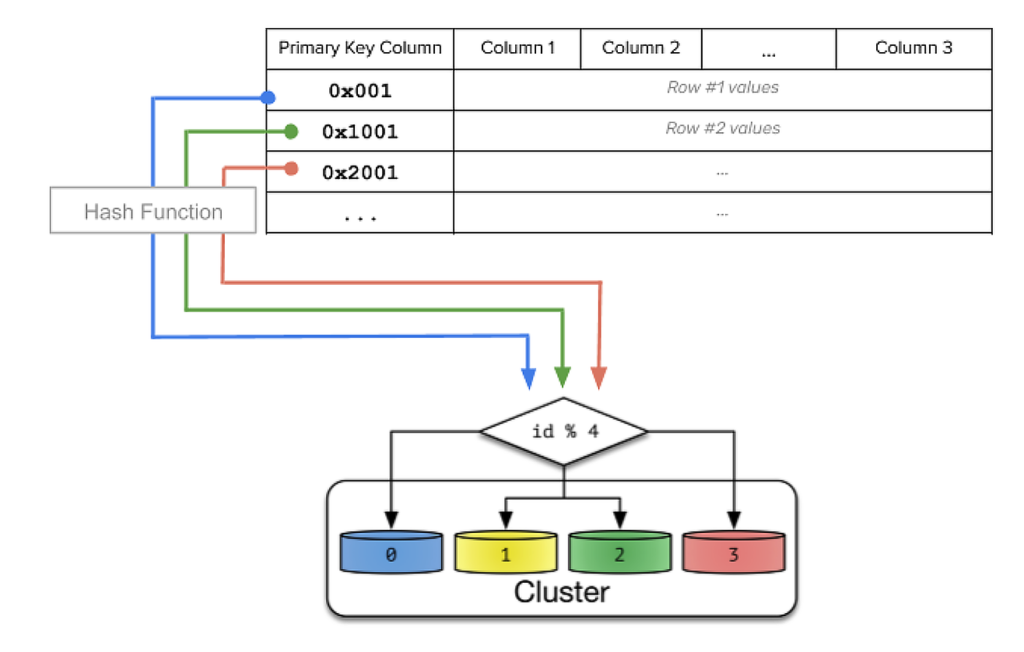
Hash sharding takes a shard key’s value and generates a hash value from it. The hash value then determines in which database shard the data should reside.
Range Sharding
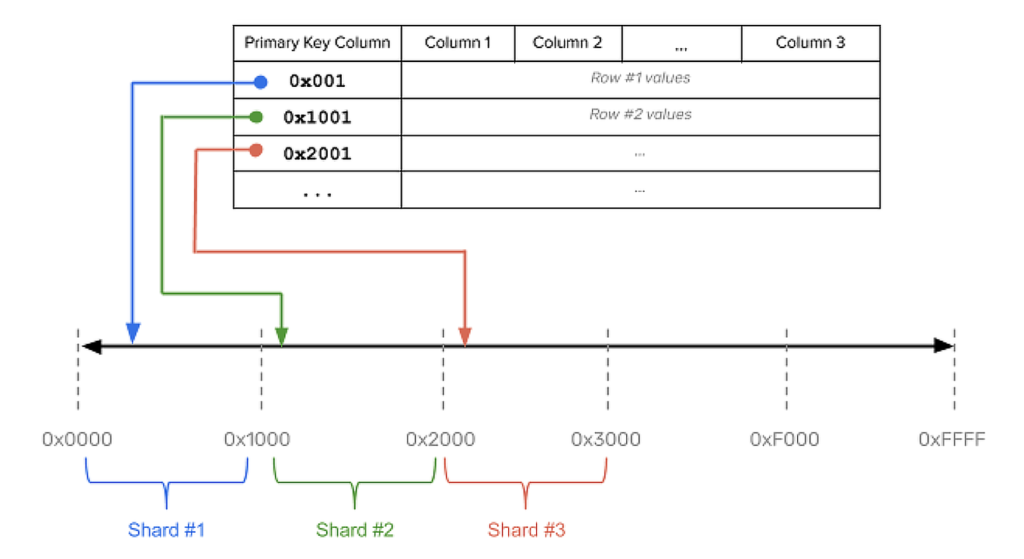
Range based sharding divides data based on ranges of the data value (i.e., the keyspace). Shard keys with nearby values are more likely to fall into the same range and onto the same shards.
Geo-Partitioning
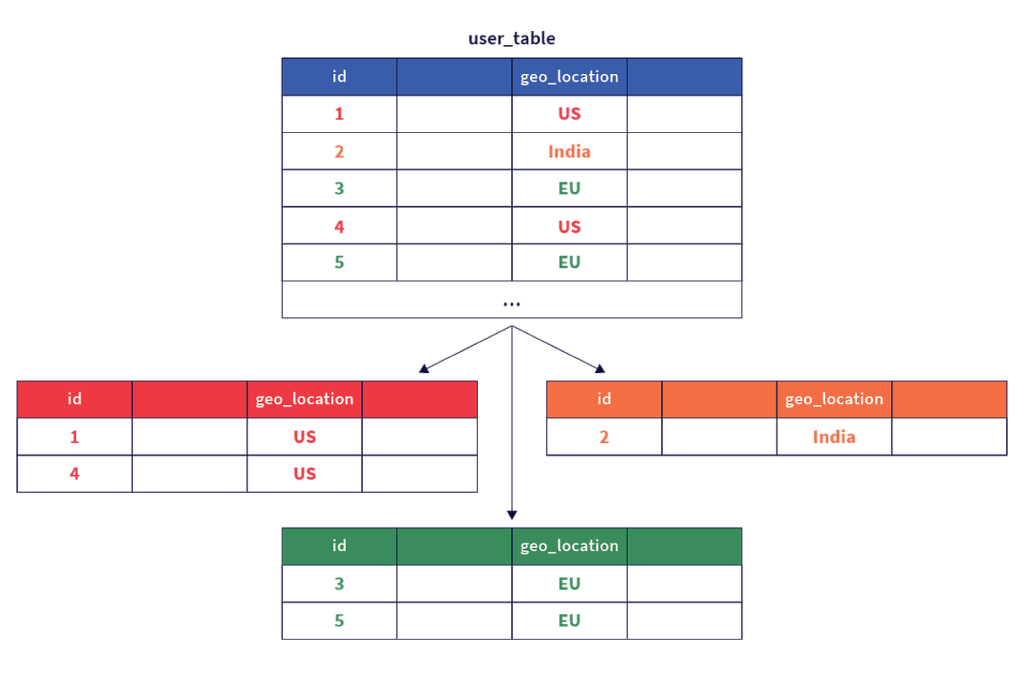
With geo-partitioning, data is first partitioned according to a user-specified column that maps range shards to specific regions and to nodes in those regions. Inside a given region, data then shards using either hash or range sharding.
Take the Pain Out of Database Sharding
Database sharding is a solution for applications with large data sets and scalability requirements. However, you need to map out the needs and workload requirements of your application first before settling on the right database architecture pattern.
Finally, YugabyteDB is an auto-sharded, high-performance, geo-distributed SQL database built for scale and resiliency. Learn more about this powerful, open source database today through our free, self-paced courses: Introduction to Distributed SQL and Introduction to YugabyteDB. And join the YugabyteDB community to answer any and all of your database sharding questions.