US-Based Bank Scales Data Platform for Billions of Real-Time Customer Interactions
October 24, 2023
A leading US-based bank, one of the nation’s largest financial institutions with assets exceeding $550 billion (as of 2021), sought to revamp its data platform architecture to become more customer-focused in today’s world of digital banking and real-time customer digital interactions.
It was essential that they improve access to real-time data and better supported many data-driven use cases to serve billions of customer interactions.
The Impact of the Move to Digital Banking
This bank operates across four lines of business:
- Consumer and business banking (i.e. retail banking)
- Payment services
- Corporate and commercial banking
- Wealth management and investment services
Over 40% is focused on retail banking.
The bank has seen a significant increase in digitally active customers—those who interact with the bank through web applications. As of May 2021, almost 8 out of 10 customers were classified as digitally active.
As you may expect, this increase in the number of customers actively interacting with them through digital channels has led to a rise in the number of digital transactions,* plus more traffic on their backend systems.
*NOTE: “Transactions” includes things such as money transfers, change of address, and card activations—across all four lines of business.
Rising to the Challenge of Non-Traditional Competition
The ongoing shift to digital is a significant macro trend reshaping how banks do business. It’s driven by evolving customer demands for new capabilities, features, and services. Therefore, the bank is continuously innovating.
But the competition does not sit idle. The bank competes against non-traditional players, including fintech and technology companies like Apple, Aliplay, and Square.
These companies pose a real threat to traditional banks. For example, a true tech company like Apple (with its Apple Pay) can scale its systems well beyond the capabilities of most traditional banks in the United States. The same is true of fintech firms Aliplay and Square.
This level of competition impacts how the bank approaches its technology landscape. They had to get more productive and get to market faster. They needed to migrate from monolithic to microservices and ensure their platform offered more self-service options.
They are also focused on building their capabilities efficiently. They recognized that:
- Duplication of effort is a common problem in large companies
- Building for scale and availability are challenging problems to solve
The bank wanted to implement a model where they solved problems once and then reused the frameworks across the company. Additionally, they wanted to create reusable self-service tools to streamline processes and eliminate bottlenecks.
Data Platform Requirements
The bank chose to have one unified data platform to serve three different use cases:
- Provide data (as-a-service) to other bank applications
- Keep data in-sync across the many different platforms
- Provide data to dashboards used by internal analyst teams, report builders, and data scientists.
Let’s focus on the cornerstone of their data platform—data-as-a-service—which powers digital interactions that improve customers’ experiences.
To fully support data-as-a-service, the data platform must be able to scale to trillions of reads and writes— to support customers’ interactions/transactions now and in the future.
This future-proofing is critical, plus the platform must also be highly available because customers expect 24/7/365 online access. The bank must be operational whenever the customer is ready.
Low latency is also crucial for that all-important digital experience. Because so many different bank applications are built on top of the data platform, it needs to serve data quickly—in less than 100 milliseconds. Customers who have to wait are customers who leave.
Finally, the bank wanted to support all types of query patterns so that data could be served in whatever way it was needed.
High-Level Data Platform Architecture
The bank’s data platform is shown in blue below. It comprises data APIs and the database layer, supporting multi-cloud, multiple data models, and complex queries.
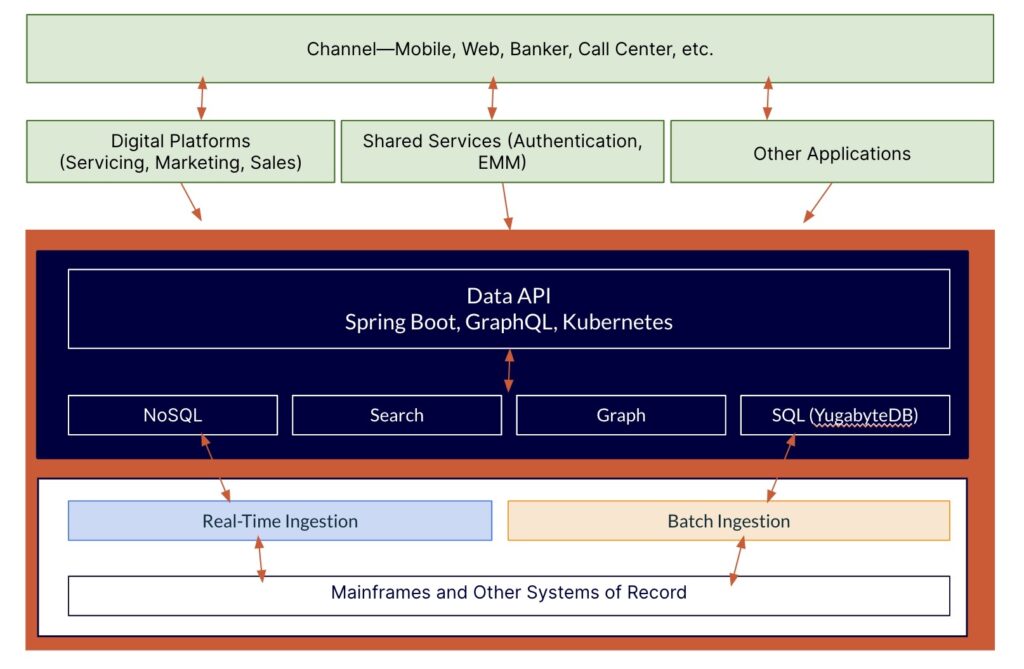 Data enters the platform in different ways. Customers interact with the bank using various channels —mobile, web, etc. These are powered by “domain APIs,” which service the digital platforms used by servicing, marketing, and sales.
Data enters the platform in different ways. Customers interact with the bank using various channels —mobile, web, etc. These are powered by “domain APIs,” which service the digital platforms used by servicing, marketing, and sales.
Data can also be ingested into the platform through real-time and batch engines and can also come into the platforms from the backend—from the bank’s mainframes and other systems of record.
Domain APIs interact with data APIs, which provide data-as-a-service capabilities. The data APIs are designed for scale and to span multiple clouds. They are built on open-source technologies, including SpringBoot, GraphQL, and Kubernetes.
The database layer comprises a mix of technologies. These include Cassandra—a NoSQL database that supports several types of customer transactions, such as address changes. Solr is used for search—to index all customer attributes (phone number, name, address, etc.) so that if (for example) bankers search on those attributes, they can quickly pull up a customer’s full 360-degree profile. For unique use cases where there’s a need to search on customer relationships, GraphQL is used. Finally, YugabyteDB is used for all SQL use cases.
Explore How Banking on Yugabyte Delivers Business Value >>>
Results: Achieving Data Platform Milestones
The bank has made significant strides in its multi-year journey, successfully meeting its database platform requirements.
The platform achieved impressive scalability of up to 100 billion reads and writes. For context—100 billion encompasses every one of the 50+ billion credit card transactions in the United States last year. The bank’s data platform can support twice that number.
The response time for most transactions comes under the goal of 100 milliseconds; the average is 60 milliseconds. The bank can also handle peak demand of up to 10,000 transactions per second (TPS) and is currently working to increase that number.
Regarding availability, the platform is built for redundancy and uses distributed technologies that provide the high availability levels they need. There have been no P1 outages in over 18 months.
To further improve productivity and eliminate development bottlenecks, teams can automatically generate code for APIs once schemas have been uploaded.
Additional Resources:
 Download The Database Architect’s Guide to Distributed SQL for Financial Services to explore why firms in the financial services sector (regardless of size) use YugabyteDB. It’s ideal for high-volume, geographically distributed transactional applications, offering low latency, high availability, compliance, and scalability.
Download The Database Architect’s Guide to Distributed SQL for Financial Services to explore why firms in the financial services sector (regardless of size) use YugabyteDB. It’s ideal for high-volume, geographically distributed transactional applications, offering low latency, high availability, compliance, and scalability.


