Spanning the Globe without Google Spanner
Open Source Geo-Distributed Relational Database on Multi-Cluster Kubernetes
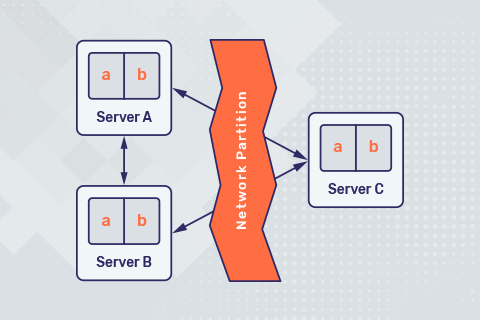
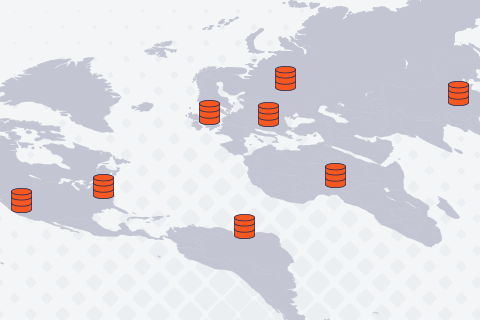
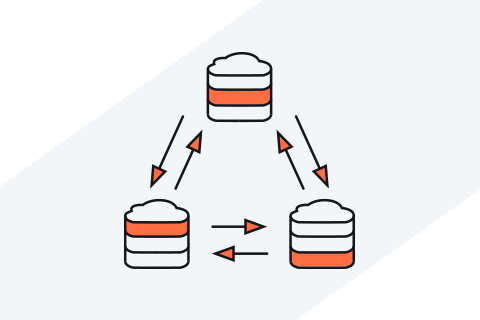
Google Spanner, conceived in 2007 for internal use in Google AdWords, has been rightly considered a marvel of modern software engineering. This is because it is the world’s first horizontally-scalable relational database that can be stretched not only across multiple nodes in a single data center but also across multiple geo-distributed data centers, without compromising ACID transactional guarantees. In 2012,
…