How To Achieve Region-Level Fault Tolerance While Using Row-Level Geo-Partitioning?
This edition of the Distributed SQL Tips and Tricks blog looks at how to achieve region-level fault tolerance with row-level geo-partitioning.

This edition of the Distributed SQL Tips and Tricks blog looks at how to achieve region-level fault tolerance with row-level geo-partitioning.

This blog examines the geo-distributed deployment topologies offered with YugabyteDB that can future-proof your data infrastructure and support your app’s needs.

To illustrate how to build a geo-distributed application, we will use as an example a Slack-like messaging app. This step-by-step guide starts with the distributed application and API layers, continues on to the distributed SQL database, and finishes with the need/purpose of the global cloud load balancer.

In an earlier blog, we broke down the definition of geo-distributed apps. So now let’s compare and contrast geo-distributed apps those apps that are deployed within a single data center or availability zone. A good way to make this comparison to understand the differences and find the similarities is to drill down into the architecture.

So what is a geo-distributed app? It is generally defined as an app that spans multiple geographic locations for high availability and resiliency. However, Iet’s expand (and then break down) that definition for a better understanding.

I’ve been working with distributed systems, platforms, and databases for the last seven years. Back in 2015, many architects began using distributed databases to scale beyond the boundaries of a single machine or server. They selected such a database for its horizontal scalability, even if its performance remained comparable to a conventional single-server database.
Now, with the rise of cloud native applications and serverless architecture, distributed databases need to do more than provide horizontal scalability.
…
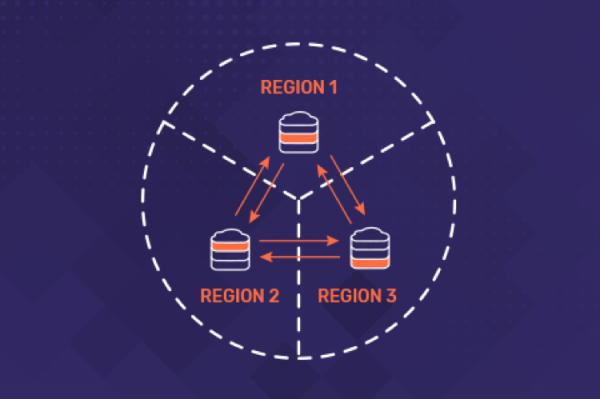
This post is an in-depth look at the various techniques that applications needing low latency and high availability can leverage while using a geo-distributed SQL database like YugabyteDB so that the negative impacts of a high-latency, unreliable Wide Area Network (WAN) are minimized.