Export and Import Data with Azure Databricks and YugabyteDB
September 26, 2022
Azure Databricks is a cloud analytics platform that can meet the needs of both export and import data from a YugabyteDB database to supported file formats —Avro and Parquet. This helps developers and data engineers, and also allows data scientists to build a full end-to-end data analytics workload.
In this blog, we will explore how to import and export Avro (a row-based storage format file) and Parquet (a columnar storage format file) and how to process the data with YugabyteDB (YBDB) using the Azure Databricks.
The Main Components Needed to Export and Import Data
YugabyteDB: The cloud native distributed SQL database for mission-critical applications.
Azure Databricks: An Apache Spark-based big data analytics service for data science and engineering.
Azure Databricks File System (DBFS): A distributed file system mounted into an Azure Databricks workspace and available on Azure Databricks clusters.
Azure Data Lake Storage (ADLS): A scalable data storage and analytics service hosted in Azure—Microsoft’s public cloud.
Architecture Diagram:
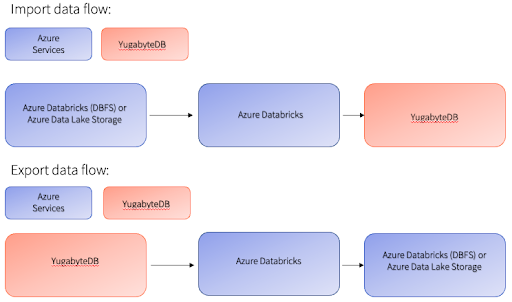
The import data flow (see above) uses Azure Databricks, which leverages either an existing Spark Cluster or a new one based on your data requirements.
The Spark Cluster can be auto-scaled based on your needs, automatically paused, and detached from Databricks when not in use. The Azure Databrick File System’s (DBFS) storage layer or Azure Data Lake Storage (ADLS) can store the Parquet or Avro data. Using the Pyspark/SparkSQL or Scala interface, the data can be easily imported directly into YugabyteDB tables without needing transformation or conversion.
The export data flow (see above) uses a similar framework and components to Azure Databricks. It can be used to export data from YugabyteDB to the Azure DBFS storage layer or to ADLS.
Import Data Loading. Steps For Parquet Files.
Step 1: Ensure that the Parquet files are available in the Databricks folder or the Azure Data Lake folder.
Example: /tmp/salesprofit
Step 2: Read the Parquet files from DBFS or ADLS through the Spark Cluster and store them in the data frame.
df = spark.read.format("parquet").load("/tmp/salesprofit")
Here df is the data frame.
Step 3: Import the data into a new or existing YugabyteDB table, as shown below.
df.write.format("jdbc")\
.option("url", "jdbc:postgresql://10.14.16.7:5433/yugabyte") \
.option("dbtable", "public.salesprofit_details") \
.option("user", "yugabyte") \
.option("driver", "org.postgresql.Driver") \
.option("password", "xxxxxx") \
.option("useSSL", "true") \
.option("ssl", "true") \
.option("sslmode", "require") \
.mode("overwrite").save()Here we used salesprofile_details as the table name, yugabyte as the user id, and enabled the SSL configuration to keep the data encrypted during transit.
The mode (“overwrite”) helps to overwrite the data if the table already exists.
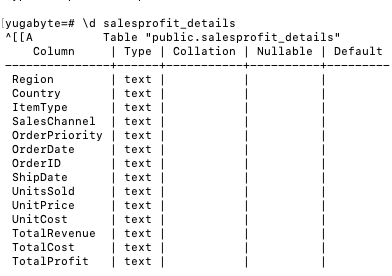
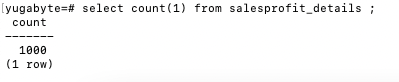
Step 4: Query the table in YugabyteDB and confirm whether the data has been imported.
Import Data Loading – Steps for Avro Files
The steps importing Avro files into YugabyteDB are the same as for the Parquet format, except for Step 2. You will need to read the Avro files from DBFS or ADLS through Spark and store them in a data frame.
#2. Read avro file and load into YugabyteDB
dfavro = spark.read.format("avro").load("/tmp/salesprofit_avro_export")
Export Parquet Data files from YugabyteDB
Step 1: Ensure that a table has been created in YugabyteDB and is loaded with the necessary data.
Example: product_master is the table that needs to be exported into Parquet format.

Step 2: Load the required table from YugabyteDB at Azure Databricks into a dataframe using PySpark or Scala.
df= spark.read \
.format("jdbc") \
.option("url", "jdbc:postgresql://10.14.16.7:5433/yugabyte") \
.option("dbtable", "public.product_master") \
.option("user", "yugabyte") \
.option("driver", "org.postgresql.Driver") \
.option("password", "xxxxxx") \
.option("useSSL", "true") \
.option("ssl", "true") \
.option("sslmode", "require") \
.load()
Step 3: Export the dataframe into the Parquet format and save it into the Azure Databricks DBFS folder or the ADLS folder, as shown below.
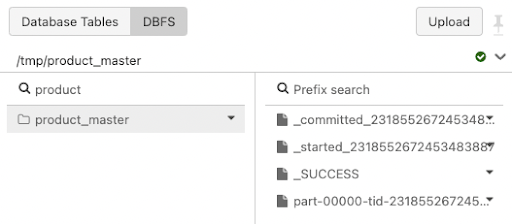
df.write.mode("overwrite").parquet("/tmp/product_master")Step 4: Verify that DBFS exported the Parquet files correctly.
Export Avro Data files from YugabyteDB
As mentioned in the above paragraph (Export Parquet Data files from YugabyteDB), the steps for exporting data into Avro format are similar from YugabyteDB to Azure Databricks File System or Azure Data Lake.
df.write.format('avro').mode('overwrite').save("/tmp/product_master_avro")
Note: The Azure Data Bricks File System-based steps for export and import data from (to) are similar to Azure Data Lake Storage (ADLS), except for the file location. For Azure Data Lake Storage, we need to configure the file location as below:
Example:
file_location = “abfss://containername or folder name @adls.dfs.core.windows.net/subfolder”
Pre-requisites
Create a Spark Cluster in Azure Data bricks and configure it with necessary PostgreSQL or Yugabyte Cassandra Driver through Maven or other repositories. Keep the YugabyteDB database nodes up and running. Refer to the Spark Cluster libraries configuration documentation from Microsoft Azure Databricks.
Azure Databricks Cluster Configuration
The cluster sizing and configuration are to be done based on the data export/import workload type (e.g. Parallelism, Number of Batch Jobs or Micro batches). The detailed cluster configuration parameters and best practices are documented on the Microsoft Azure Databricks page.
Configurations to Check Performance
- Batch size:
Spark dataframe supports a parameter “batchsize” while writing data into YugabyteDB (YSQL or YCQL) using jdbc. The default value is 1000, which should be good enough for a decent ingestion rate. Otherwise, you may want to adjust it to gain better performance.
Example:df.write.format("jdbc")\ .option("url", "jdbc:postgresql://10.14.16.7:5433/yugabyte") \ .option("dbtable", "public.salesprofit_details") \ .option("user", "yugabyte") \ .option("driver", "org.postgresql.Driver") \ .option("password", "xxxxxx") \ .option("useSSL", "true") \ .option("ssl", "true") \ .option("sslmode", "require") \ .option("batchsize","200000") \ .mode("overwrite").save() - Number of Partitions:
The primary effect would be by specifying partition size. spark.default.parallelism is the default number of partitions set by spark which is by default 200. Note: With too few partitions, we will not utilize all of the cores available in the cluster. With too many partitions, there will be excessive overhead in managing many small tasks. Between the two, the first one is far more impactful on performance. Scheduling too many small tasks is a relatively small impact on partition counts below 1000.
Sample Code
Visit GitHub for the code artifacts that you can download and test with your own YugabyteDB/Azure Databricks environment or any other notebook editor which runs with Spark Clusters.
Interested in finding out more? Join our active Slack community of users, experts, and enthusiasts for live and interactive YugabyteDB and distributed SQL discussions.


