Fine-Grained Control for High Availability: Increasing Node Failure Threshold
May 27, 2021
The purpose of this blog post is to show how you can increase the failure threshold when a node goes down, which happens for a variety of reasons including hardware or network issues and most commonly maintenance. The failure threshold is the amount of time YugabyteDB would wait, after a node goes down, for it to potentially come back up. After reaching this threshold the physical data will begin to move from the dead node to other nodes in the cluster. Before this time the node is considered down but not yet considered a dead node.
By default the threshold in YugabyteDB is set to 15 minutes, which is normally plenty of time for transient errors and planned maintenance. However, depending on your situation/environment, it might be suitable to increase this. One such situation is if there is a large data density per node. Once a node is down beyond the threshold limit then you will have to wait for the cluster to rebalance before being able to add the node back in. In large data density environments this can take several hours on both the rebalance and node addition. In order to workaround this, you could increase the threshold and allow more time to get the node back up and running, saving you time in the long run.
Increasing Threshold
Let’s say we wanted to increase the threshold from the default of 15 minutes to 3 hours. To do this, there are two settings that will need to be changed. The first is follower_unavailable_considered_failed_sec, which controls when Raft consensus would kick a dead node out of its quorum. The second, is log_min_seconds_to_retain, which controls how long write ahead log (WAL) segments are kept. This is important, as for transient failures, we use these WAL segments to catch up nodes, if they do come back, before the time window expires. When adjusting these two values it’s important to make sure that both are set to the exact same value. To increase the threshold to 3 hours, we will need to set these two values to 10800 seconds or 3 hours. In this post, we show you how to set the gflags in Yugabyte Platform in a rolling restart fashion to avoid any downtime.
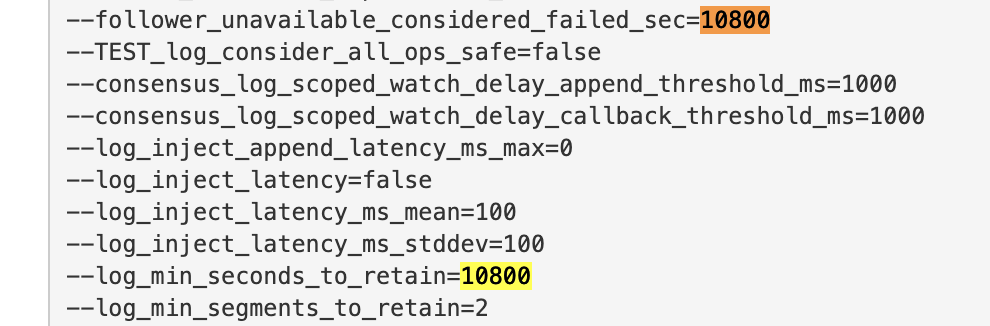
Once the rolling restart is finished, we can double check these values are set by going to the tserver UI and checking the gflags set by navigating to https://<tserver>:9000/varz or by running curl <ip>:7000/varz | grep <flag> directly on the YugabyteDB node.
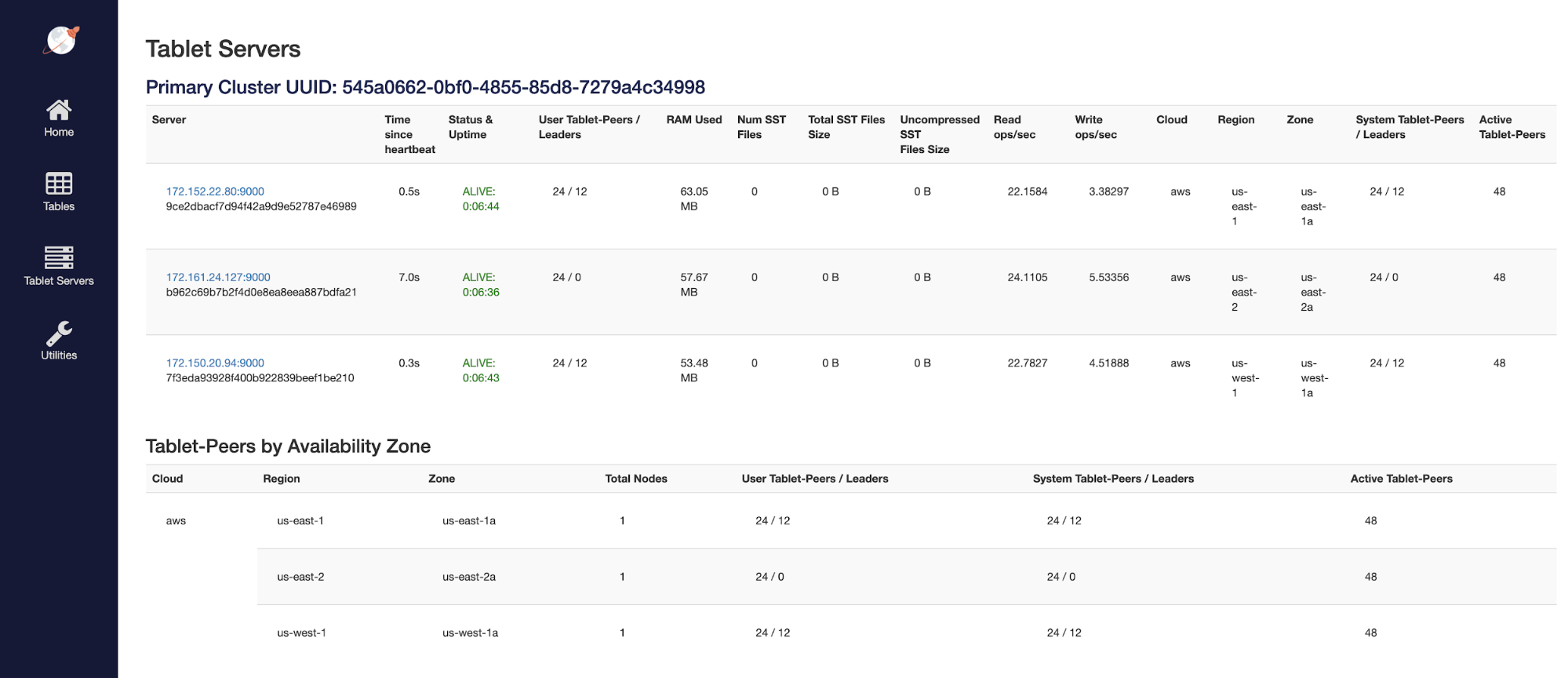
After the gflags are updated we will take down a node and verify the data does not move until after 3 hours. Once the node is down we will first see that the tablet leaders move. This is to be expected as tablet leadership will always move when a node is down so that there is no impact to the reads and writes for the application.
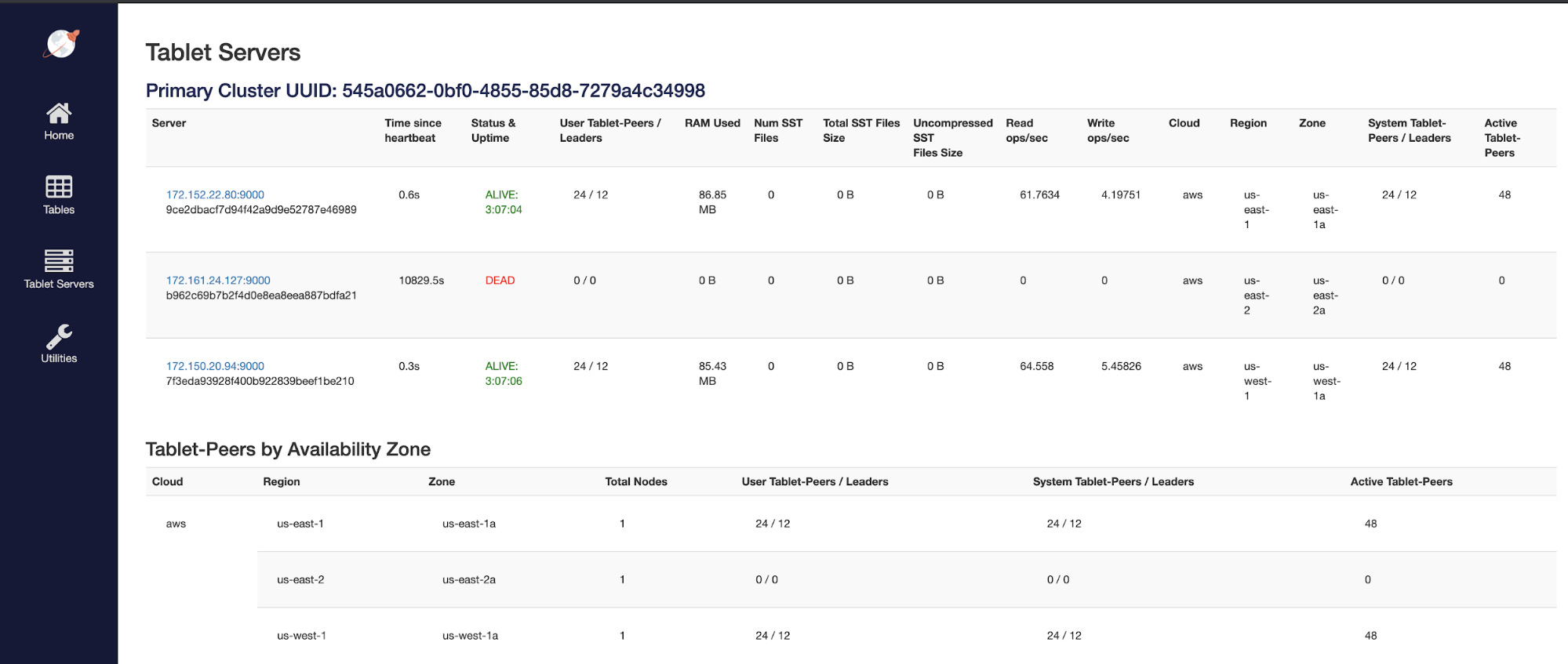
However, looking at the actual physical tablets we see that there is no movement until after 3 hours.
One important thing to note is that during all of this work being done removing nodes and adjusting these gflags there has been no impact on the application. Because of the high availability and resilience automatically built into YugabyteDB, having a node down for over 3 hours has no effect on the application traffic.
Things to Keep in Mind
There are a few things to keep in mind when increasing the node failure threshold. First, when one node is down that does leave you in a vulnerability window for the period before the threshold is hit. This is because before the threshold is met YugabyteDB will not automatically heal and try to replicate the tablets on the downed nodes to other nodes in the cluster. This leads to under replicated tablets and if more nodes are lost can lead to application failures.
Another thing to keep in mind is the disk utilization on the nodes that are storing the write ahead logs for the time when the node is down. You will see an increase in utilization as the logs which are normally purged on a regular basis are no longer deleted for the period of time before the threshold is hit. So when increasing these settings it’s important to keep an eye on the disk space utilization.
Conclusion
There are times when a node is down longer than 15 minutes but you may not want to have to re-bootstrap the node to add it back in. In these cases it would be good to change the threshold to a larger value than the default in order to give you more time. If this scenario comes up in your environment, we invite you to reach out to your Yugabyte support team or contact us on the YugabyteDB community Slack so we can help you navigate through the process.

")
