Indexing JSON in PostgreSQL
May 30, 2023
Indexing JSON documents in PostgreSQL is similar to indexing relational table columns. Although the structure is not enforced at write time like normalized tables, we can still add indexes for our access patterns. In SQL, we index the values we select, filter, or sort on, whether they are columns or expressions based on any row’s columns, including JSON attributes.
Demonstrate JSON Indexing in PostgreSQL: A Pokémon GO Pokédex Example
In this example, we’ll index the JSON in PostgreSQL using the Pokémon GO Pokédex as our dataset. Each Pokémon is stored as a row in a table, identified by a UUID and containing relevant information in a JSONB column. We’ll use YugabyteDB, a distributed SQL database compatible with PostgreSQL. If you’re using PostgreSQL, you can replicate the same. NOTE: The data is sourced from Gianluca Bonifazi’s Pokémon GO Pokédex, and the code assumes the ‘jq’ tool is installed to retrieve one row per Pokémon using ‘psql’.
create extension pgcrypto;
create table dex (
id uuid default gen_random_uuid() primary key,
data jsonb
);
-- \! jq --version || dnf install -y jq
\copy dex(data) from program 'curl -s https://raw.githubusercontent.com/Biuni/PokemonGO-Pokedex/master/pokedex.json | jq -r ".pokemon[] | tostring"' ;This loads 151 rows:
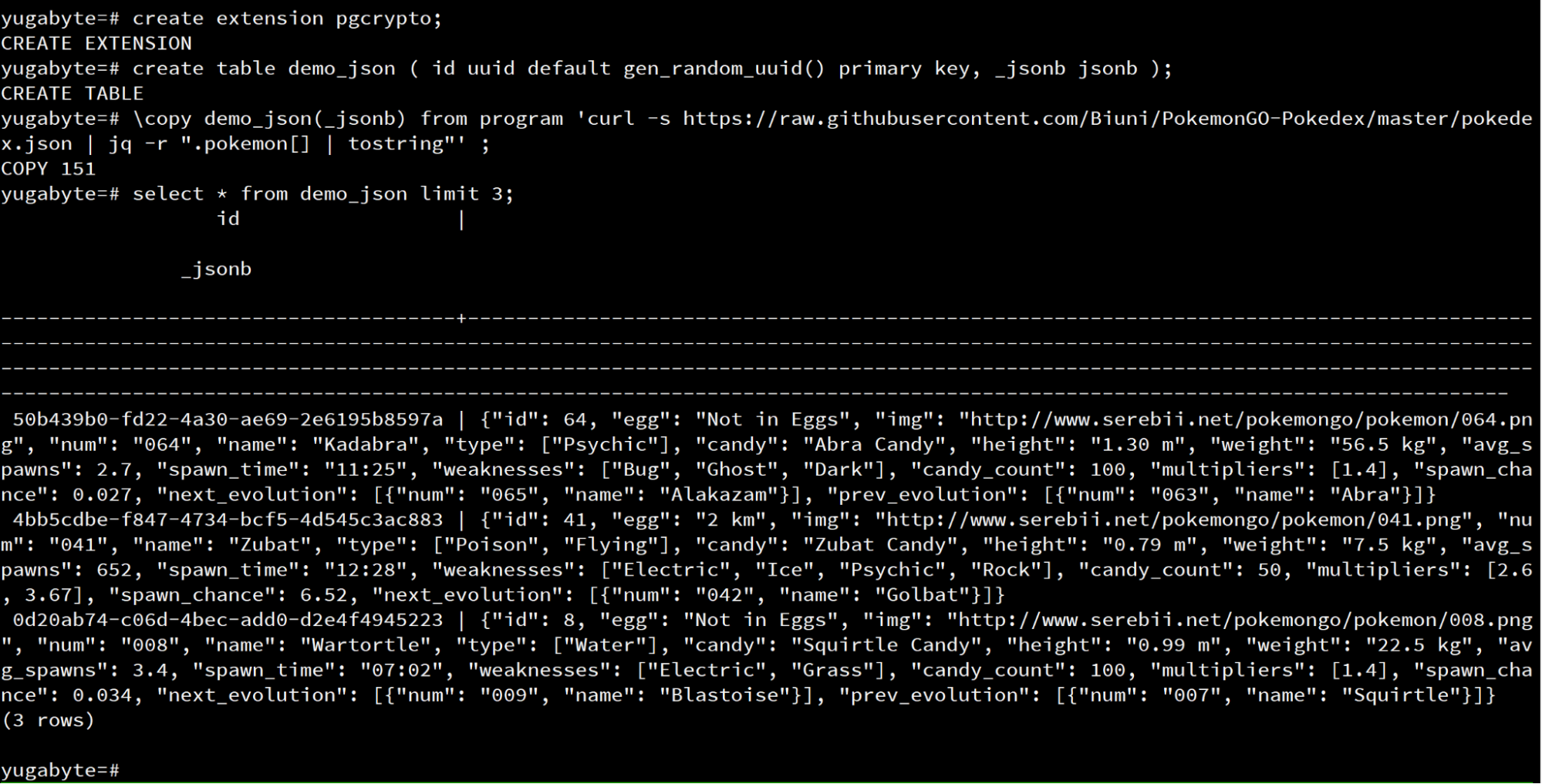
Please note that in this model, accessing a single object by its primary key (UUID) is fast. However, for any other query, the entire table needs to be scanned.
Here is an example:
explain (costs off, analyze, dist, summary off)
/*+ Set ( yb_enable_expression_pushdown false ) */
select format('%-20s %10s',data->>'name',data->>'weight')
from dex where data->>'name'='Pikachu';
;
QUERY PLAN
-----------------------------------------------------------------
Seq Scan on dex (actual time=1.001..1.523 rows=1 loops=1)
Filter: ((data ->> 'name'::text) = 'Pikachu'::text)
Rows Removed by Filter: 150
Storage Table Read Requests: 3
(5 rows)If using YugabyteDB:
In YugabyteDB, additional optimizations for filtering during the scan are incorporated. In this code example, I have disabled the expression pushdown to showcase the ‘Rows Removed by Filter’ statistics. All 151 rows are read and later filtered to retain only one row. Due to YugabyteDB’s distributed nature, the table is distributed across three nodes, resulting in three read requests. On PostgreSQL, which is not distributed and reads from the local shared buffer, this pushdown is not necessary. —to see the execution statistics, do not add ‘dist’ but ‘buffers’ to ‘explain analyze’. However, even with remote filter pushdown, the Seq Scan still reads more rows than necessary.
Fast and scalable access to one or a few rows should utilize an indexed condition—in both PostgreSQL and YugabyteDB. There are two kinds of indexes available:
- Regular indexes ( B-Tree in PostgreSQL and LSM-Tree in YugabyteDB) that index values with one value per row, like a single column or attribute
- Inverted indexes (GIN in both PostgreSQL and YugabyteDB) that handle cases where each row has multiple values to index, such as an array of values
Now, let’s explore some examples of indexes and the access patterns they optimize.
Examples of Indexes and the Access Patterns Optimized
- Indexing a single value per row from a top-level JSON attribute
Each document includes the Pokemon name as a top-level attribute. To efficiently query by name, we can create an index specifically designed for this purpose.yugabyte=# create index dex_name on dex ( (data->>'name') ); CREATE INDEXTwo things to remember are:
- In addition to the parenthesis for the list of index columns, PostgreSQL requires additional ones when the value-to-index is not a column but an expression
- It’s possible to index (data->’name’) rather than (data->>’name’) as long as the same is used in queries. The former indexes the value as a JSONB datatype; the latter as a TEXT datatype. Because the value looked up, which is the name of a Pokemon, is a text value, it makes more sense to query on a text value and index on it.
yugabyte=# select format( '%-20s %10s', data->>'name', data->>'weight' ) from dex where data->>'name'='Pikachu'; format --------------------------------- Pikachu 6.0 kg (1 row) yugabyte=# explain (costs off, analyze, dist) select format( '%-20s %10s', data->>'name', data->>'weight' ) from dex where data->>'name'='Pikachu'; QUERY PLAN ---------------------------------------------------------------------------------------- Index Scan using dex_name on dex (actual time=0.937..0.939 rows=1 loops=1) Index Cond: ((data ->> 'name'::text) = 'Pikachu'::text) Storage Index Read Requests: 1 Storage Table Read Requests: 1 (6 rows)In this example,the attribute value is the top level document. I can do the same for a nested level, using ‘->’ to navigate into the hierarchy, as long as I finally get to a single child because regular indexes are on scalar values.
- Indexing a single value per row from a nested JSON attribute
To search by Pokemon’s next evolution, create an index on (data->’next_evolution’->0->>’name’). However, this next evolution is an array, and this indexes only the first one. Knowing that there are at most three evolutions in this Pokedex, you can create three indexes:create index dex_next_evolution_0 on dex ( (data->'next_evolution'->0->>'name') ); create index dex_next_evolution_1 on dex ( (data->'next_evolution'->1->>'name') ); create index dex_next_evolution_2 on dex ( (data->'next_evolution'->2->>'name') );
But then you have to use a UNION ALL in the query:
select * from dex where data->'next_evolution'->0->>'name'='Golem' union all select * from dex where data->'next_evolution'->1->>'name'='Golem' union all select * from dex where data->'next_evolution'->2->>'name'='Golem';
Navigating through the document hierarchy with ‘->’ works for keys but not for arrays. This is where you can use some of the more advanced PostgreSQL operators— @>, @? or @@ on JSONB (as documented in JSON Functions and Operators).
- Indexing through arrays (multiple values per row)
In the previous example the Pokemon “next evolution” nested level is an array with many values. Create a GIN index for it:yugabyte=# create index dex_next_evolution on dex using gin ( (data->'next_evolution') jsonb_path_ops ); CREATE INDEXTwo things to remember are:
- This indexes all values in the subdocument. There’s no ‘->>’ because the value read by the index is a JSON sub-document. I will not query it with an ‘=’ operator, to compare a scalar value, but a ‘@>’, the ‘contains’ operator.
- The default GIN operator on JSONB indexes not only the values but also the key. As I know the structure and will query on values only, I’m using a jsonb_path_ops operator which will make the index more efficient for @>, @? or @@.
The following query can use this index to search which Pokemon has Golem as one of its next evolution:
yugabyte=# select format( '%-20s %10s', data->>'name',data->'next_evolution' ) from dex where data->'next_evolution' @> '[{"name": "Golem"}]' ; format -------------------------------------------------------------------------------------------- Geodude [{"num": "075", "name": "Graveler"}, {"num": "076", "name": "Golem"}] Graveler [{"num": "076", "name": "Golem"}] (2 rows) yugabyte=# explain (costs off) select format( '%-20s %10s', data->>'name',data->'next_evolution' ) from dex where data->'next_evolution' @> '[{"name": "Golem"}]' ; QUERY PLAN ------------------------------------------------------------------------------------ Index Scan using dex_next_evolution on dex Index Cond: ((data -> 'next_evolution'::text) @> '[{"name": "Golem"}]'::jsonb) (2 rows)If using YugabyteDB:
In PostgreSQL you will see a Bitmap Index Scan and a Recheck Cond because the implementation is different (B-Tree indexes, heap tables, and shared buffers). YugabyteDB stores tables and indexes in sharded and distributed LSM-Trees; bitmaps and rechecks would not be efficient. Those are storage implementation details, but the idea is the same: read only the rows that match ‘Index Cond’.The ‘@>’ operator is used for many PostgreSQL datatypes to check if a value is contained by an array or document, or even a word or trigram contained in the text. You can also use a JSON path with the ‘@@’ operator. The following query performs similarly and gives the same result:
yugabyte=# select format( '%-20s %10s', data->>'name',data->'next_evolution' ) from dex where data->'next_evolution' @@ '$[*]."name"=="Golem"' ; - Indexing for range scan and top-n queries
Index the scalar attributes with ‘->>’ to get them as text, but they can be casted to other scalar datatypes. This indexes the Pokemon’s spawn probability, which is a float datatype even if everything is represented as text in JSON.yugabyte=# create index dex_spawn_chance on dex ( ((data->>'spawn_chance')::float) asc ); CREATE INDEXTwo things to remember are:
- There is one additional pair of parentheses needed to cast the text from (data->>’spawn_chance’) to a float. Without that pair, the cast would be applied to the filed name ‘spawn_chance’ and would raise an ‘invalid input syntax for type double precision’ error.
- You could index data->’spawn_chance’ rather than data->>’spawn_chance’ but the value would implicitly be converted to text before float, because all JSON values are strings. Try to avoid implicit conversions; but you need to be consistent because the query must use the same as the index definition
This index will be used by the following query displaying the top-5 Pokemons with the lowest chance to spawn:
yugabyte=# select format( '%-20s %10s', data->>'name',data->'spawn_chance' ) from dex where (data->>'spawn_chance')::float > 0 order by (data->>'spawn_chance')::float asc limit 5 ; format --------------------------------- Dragonite 0.0011 Charizard 0.0031 Muk 0.0031 Mr. Mime 0.0031 Kabutops 0.0032 (5 rows) yugabyte=# explain (costs off) select format( '%-20s %10s', data->>'name',data->'spawn_chance' ) from dex where (data->>'spawn_chance')::float > 0 order by (data->>'spawn_chance')::float asc limit 5 ; QUERY PLAN ----------------------------------------------------------------------------------------------------- Limit -> Index Scan using dex_spawn_chance on dex Index Cond: (((data ->> 'spawn_chance'::text))::double precision > '0'::double precision) (3 rows)
Last Tip: Create Views with the Indexed Expression
To ensure consistency between the indexed expression and the one used, I prefer adding them as virtual columns through a view. Here are the definitions of the indexes to use:
yugabyte=# \d dex;
Table "public.dex"
Column | Type | Collation | Nullable | Default
--------+-------+-----------+----------+-------------------
id | uuid | | not null | gen_random_uuid()
data | jsonb | | |
Indexes:
"dex_pkey" PRIMARY KEY, lsm (id HASH)
"dex_name" lsm ((data ->> 'name'::text) HASH)
"dex_next_evolution" ybgin ((data -> 'next_evolution'::text) jsonb_path_ops)
"dex_spawn_chance" lsm (((data ->> 'spawn_chance'::text)::double precision) ASC)Don’t be fooled by the ‘::text’ cast as this applies only to the field name, which is a text string literal anyway. To match the definition, keep it in the view definition
yugabyte=# create or replace view dex_view as
select *
, (data ->> 'name'::text) as name
, (data -> 'next_evolution'::text) as next_evolution
, ((data ->> 'spawn_chance'::text)::double precision) as spawn_chance
from dex;
Now you can safely query the view without having to know the JSON path, with optimal access paths thanks to the indexes:
select format(
'%-20s %10s', name, data->>'weight'
) from dex_view where name='Pikachu';
select format(
'%-20s %10s', name,data->'next_evolution'
) from dex_view
where next_evolution @> '[{"name": "Golem"}]'
;
select format(
'%-20s %10s', name,data->'next_evolution'
) from dex_view
where next_evolution @@ '$[*]."name"=="Golem"'
;
select format(
'%-20s %10s', name, spawn_chance
) from dex_view
where spawn_chance > 0
order by spawn_chance asc
limit 5
;All those queries use an Index Scan and the response time will be the same with billions of rows in the table.
Final remarks on documents in SQL databases
Indexing all JSON keys and attributes with a generic index (‘using gin ( data )’) would not be optimal for the same reason that we do not create indexes on all tables and columns in a relational model. In this case, the data is not an unstructured collection of values; it’s simply a different way of storing semi-structured data in a single table with a JSON column. The data access process remains the same: identify access patterns, create specific indexes for them, and encapsulate the logic in views. This approach resembles NoSQL but with strongly consistent indexes that are seamlessly utilized when querying the view. SQL provides the flexibility to optimize for new read patterns without requiring changes to the application code.
The JSON-Relational duality is not an all-or-nothing decision. This example was extreme with all attributes in JSON but some of them could be changed to a table column format. This is another advantage of the view created: you can reorganize the table without changing the application queries on the view. If some attributes are frequently updated, or could benefit from an Index Only Scan, it’s better move them into their own column. You may also prefer multiple small JSON columns rather than one—the main data as structured relational columns and additional attributes in semi-structured documents. In conclusion, you have full flexibility when storing objects in the SQL database, and if you choose to store all or part of it as JSON document, index them for your access patterns with regular indexes on scalar values and GIN indexes on arrays.


