Maximizing Database Performance: The Benefits of Full Compactions and Automated Scheduling
April 17, 2023
As discussed in our previous post on background compactions, YugabyteDB relies on RocksDB compaction algorithms for internal data management. The background compactions described in that post are well-optimized for new incoming writes. However, there are some scenarios where they fall short, and background algorithms may not compact some data often enough.Some scenarios include: workloads with a large number of updates or deletes, workloads with TTL enabled, and situations where data must be fully deleted by a specific date for compliance reasons. For those situations, full tablet compactions can fill those gaps.
In this blog, we will explore the advantages of performing full compactions and examine some scenarios in which they are commonly utilized. Additionally, we will provide instructions on how to set up automatic scheduling of full compactions in YugabyteDB. It is worth noting that while TTL (which is an exclusive feature of YCQL) is an exception, compactions are essentially the same in both YSQL and YCQL.
Benefits of Full Compactions
Background compactions contain a subset of files selected by one of two algorithms. These files are typically small and composed of newer data, and the compaction serves to organize that data into a larger file for the longer-term. This is done to maximize compaction effectiveness while minimizing their overhead. For many workloads (e.g. read- and insert-heavy workloads), background compactions are sufficient.
In contrast, full compactions involve combining all files within a single tablet into one large file. When performed on a table or TServer, full compactions are broken down into full compaction tasks for each of that table or TServer’s tablets. While the benefits of full compactions are similar to those of background compactions, they are executed on a larger scale to minimize overhead and prevent disruption of ongoing work.

Reduce Read Amplification
When a key is updated in YugabyteDB, it may have version updates stored in multiple files. During full compaction, only the necessary previous key/value (K/V) versions need to be retained for history retention. If older versions are not required for history retention, then each data item will be consolidated to a single (most recent) version—now all in a single file.
Garbage Collection
In addition to consolidating versions, full compactions can also remove deleted tuples from file storage in YugabyteDB. When a user deletes data, it is not immediately removed from DocDB. Instead, a “tombstone” value is inserted for that key to indicate that it should no longer be accessed by queries. Because tuples in YugabyteDB are tombstoned at deletion time, they can persist in older uncompacted SST files for quite some time. Full compactions can include these older SSTs that may not be picked up by background compactions for a long period of time, freeing up space in the process. As a result, any deleted or obsolete versions of tuples (outside of history retention range, which is 15 minutes by default) will be removed.
Resources Required for Full Compactions (Don’t Call It a Vacuum!)
After reading the benefits section above, you may feel that full compactions may sound like the infamous Postgres VACUUM command, especially since it pertains to its ability to reclaim space occupied by deleted tuples. While the end result is similar, compactions have two very significant advantages:
- Normal Postgres
VACUUMcommands (that do not require locks) do not reclaim space on disk. By contrast, YugabyteDB full compactions do reclaim space on disk. - Full Postgres
VACUUMcommands will reclaim space but require an exclusive lock on the table or partition while they execute. On the other hand, full compactions in YugabyteDB do not require any locks on the tablet or its data. Because SST files are immutable once written, there is no need to create a lock during full compactions.
A full tablet compaction should not be noticeable to the user and can be safely run alongside active workloads. In rough terms, they require:
- CPU—Iterating over all data in a tablet will require more CPU cycles than a typical automatic compaction which only touches a fraction of the data. Full compactions use the same dedicated TServer priority thread pool used for background compactions and will run alongside live workloads.
- Disk space and IO operations—During the compaction, data is copied from existing SSTs to a new one, leading to a doubling (temporarily) of the required space for the table (10GB at most if automatic tablet splitting is enabled). Once the compaction is complete, the old SSTs are deleted. If the TServer crashes during compaction, the incomplete new SST is deleted instead. On most nodes, this temporary space amplification of a single tablet is not noticeable. However, in some edge cases (e.g. one enormous tablet without splitting enabled), it may be. Additionally, the data copying will require disk IO to complete.
Compactions are a typical part of RocksDB data management, and run alongside active workloads all the time by necessity. As such, RocksDB is optimized such that compactions have minimal runtime performance impact.
Workloads that Benefit from Regular Full Compactions
As previously mentioned, full tablet compactions are relatively computationally inexpensive and can be scheduled to run regularly. Workloads that involve frequent updates and deletions can experience significant improvements in read performance and space usage reduction. Additionally, YCQL tables with a default TTL (i.e. all tuples have a time to live) can also greatly benefit. Here are three examples that illustrate this point.
Delete-Heavy Example
Let’s say 1,000,000 rows are inserted into the following table (for simplicity’s sake, let’s assume only one tablet).
CREATE TABLE Example ( id bigint NOT NULL, c2 varchar(255), c3 varchar(255), c4 varchar(255), c5 varchar(255), PRIMARY KEY (id) );
Once all the dust has settled and the automatic compactions are done, the resulting SSTs may look something like this (simplified to 5 SSTs):

Example of SST files in a tablet before full compaction Note that the majority of the data is stored in SST1, while SSTs 2 through 5 have smaller quantities of the data, with the size tending to decrease with newness.
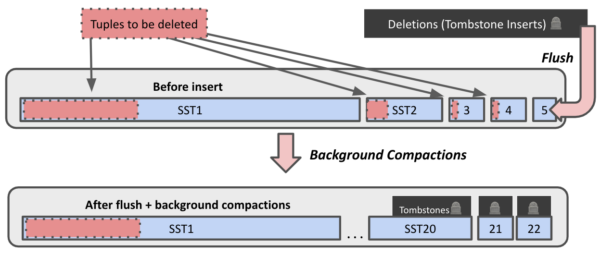
Now let’s say that the user deletes 100,000 of those tuples. Each delete requires a tombstone to be added. After a number of flushes and background compactions take place, the results may look like this.
Tuple Deletions with Background Compactions Only As you can see, some of the tombstones get compacted into the same files as the tuples/values that they delete. In this case, both can be removed in the resulting file. However, a large chunk of the tuples remain in SST1, which was not involved in any background compactions due to its size. Consequently, the original data and the tombstones that remove it still persist. Interestingly, deletions can actually increase the database’s actual size rather than decrease it!
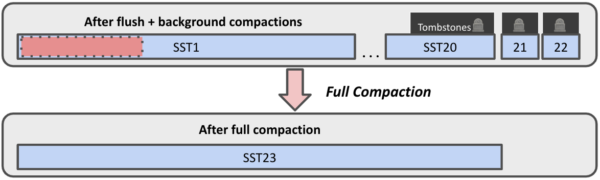
Tuple Deletions after Full Compaction A full compaction, on the other hand, would combine everything into one file, garbage collecting in the process (provided the deletes are not still within the history retention window). Tombstones and deleted tuples can both be removed, giving the expected result: data remaining only for the 900,000 non-deleted tuples. Of course, the cost of this is that the full compaction must iterate through all SSTs to create the new one.
Update-Heavy Example
Full compactions operate similarly in an update-heavy workload. In the 1,000,000 tuple example above, assume instead a 100,000 tuples were updated. A full compaction would consolidate everything into a single file, performing garbage collection of the old versions in the process (assuming the original data versions are not within the history retention period). Both tombstones and previous tuple versions can be eliminated, resulting in only the latest version of all 1,000,000 tuples remaining. Again, the full compaction will need to iterate through all SSTs to generate the new one.
In both the delete-heavy and update-heavy examples, the issue of read amplification is exacerbated by queries that require data scans rather than seeks, or queries that look for certain aggregates (e.g. ORDER BY… LIMIT).
TTL Example
Tables with default TTL (time-to-live) regularly expire tuples as they age past their time-to-live. Unlike the delete example above, tombstones are not used in this case; the tuples are simply recognized as expired.
Let’s look at the same table as the examples above but add a default TTL of 10 days. Let’s say that every day, 100,000 tuples are added to the table. After 20 days, the data might look like this.
Tuple Expirations from TTL after Full Compaction

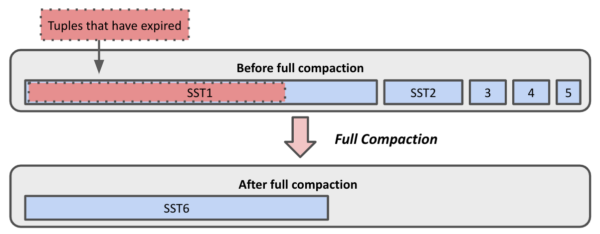
All the expired data is now stuck in the largest file, since it is the oldest data. Eventually that file will be included in a background compaction, freeing up that space. However, it is difficult to predict when this will happen, and the table size will continue to increase until then. A full compaction, however, will capture that file as well and free up this space.
NOTE: Full compactions should NOT be used with tables that make use of the TTL file expiration feature. The file expiration feature requires separate SST files for proper functioning, and combining all tablet data into one SST will force expired data to be stuck in the largest file for far longer.
Scheduling Full Compactions on a Regular Basis
Regularly running full compactions can offer significant benefits, as explained earlier. To supplement background compactions, you can use the scheduled full compactions feature.
With the scheduled full compactions feature, you can set the frequency at which you want the tables to be compacted. The system will automatically stagger the compactions so they are not all triggered at once.
The feature is controlled by the following TServer flags:
- scheduled_full_compaction_frequency_hours*** —The frequency with which full compactions should be scheduled on tablets. The default value is 0, meaning the feature is disabled by default. Simply increase this value to schedule full compactions. A recommended value would be 720 hours (i.e. 30 days). If more frequent full compactions are required, 168 hours (i.e. 7 days) is a good minimum value to consider.***NOTE: This feature is currently in beta as of April 2023.
- scheduled_full_compaction_jitter_factor_percentage—Controls the amount of staggering between tablet full compactions. By default, it is set to 33, which will ensure that most full tablet compactions are not scheduled simultaneously. If the desired effect is to compact tablets as close to a predictable schedule as possible, this feature can be set to 0. Similarly, if you want to spread out full compactions as much as possible (without worrying about compacting too much), the value can be set to 100.
Both these flags are runtime flags that do not require a cluster restart. The feature can be safely enabled or disabled at any time. Full compactions use the same general compaction tuning flags as background compactions.
Some current caveats:
- Scheduled full compactions must be either enabled or disabled for all tables in a universe. Currently there is no ability to specify a schedule per table.
- The feature is disabled for TTL tables when the TTL file expiration feature is activated. The two features are currently incompatible.
- It is good to not “overschedule” full compactions for the sake of cluster performance. A good rule of thumb may be to schedule them every 168 hours (1 week) at most frequent, though your mileage may vary.
Admin-Triggered Full Compactions
In addition to scheduling full compactions, an admin can trigger full compactions directly on an entire table or a single tablet peer.
To trigger a full compaction on all tablets in a table, use the yb-admin tool. Note that secondary indexes must be compacted separately:
yb-admin \ -master_addresses <master-addresses> \ compact_table <keyspace/database> <table_name> \ [timeout_in_seconds]
- master-addresses: Comma-separated list of YB-Master hosts and ports. Default value is localhost:7100.
- keyspace: Specifies the database ysql.db-name or keyspace ycql.keyspace-name.
- table_name: Specifies the table name. If multiple schemas have the same
table_name, thentable_idwill need to be used instead. - timeout_in_seconds: Specifies duration, in seconds when the cli timeouts waiting for compaction to end. Default value is 20.
When performing full table compactions, it’s possible that a client command may time out before the compaction on a larger table completes. However, even if this occurs, the compaction request has still been received by TServers, which will finish the tablet compactions asynchronously. As long as the TServers containing the tablets continue running, the full compactions will eventually complete.
To trigger a compaction on a single tablet, use the yb-ts-cli tool:
yb-ts-cli [ --server_address=<host>:<port> ] compact_tablet <tablet_id>
Similarly, you can trigger compactions on all tablets of a given TServer using yb-ts-cli. Be careful when using this option, however, as it can require a large amount of resources for an extended period of time for a dataset with a large number of tables or a lot of data:
yb-ts-cli [ --server_address=<host>:<port> ] compact_all_tablets
It is also worth noting that full compactions occur on each child tablet every time a tablet split completes. This removes any unnecessary duplicate data from the newly-created tablets.
Conclusion
Full compactions can provide significant advantages for YugabyteDB universes, especially for workloads with high rates of updates or deletions or with default TTL. Full compactions can greatly improve disk space usage and performance. Fortunately, the resources required for full compactions should not have a substantial impact on running workloads. You can set up full compactions to automatically run on a weekly or monthly basis to complement normal background compactions and enhance universe performance. Additionally, you can trigger them manually using YB admin tools.


