Stateful Applications: Design Considerations for Data in Edge Environments
July 18, 2022
If you are designing your architecture for stateful edge applications, here are some key principles and design patterns you should be aware of.
The following text is an excerpt from the white paper, Stateful Applications at the Edge.
Data Lifecycle
Firstly, consider where your data is produced, what you need to do with it (analyze, store and forward, long-term storage, etc.), and where it is consumed. Moving data across regions incurs high latency. So, placing data close to where the data is produced and consumed ensures lower latency and higher throughput access to the data.
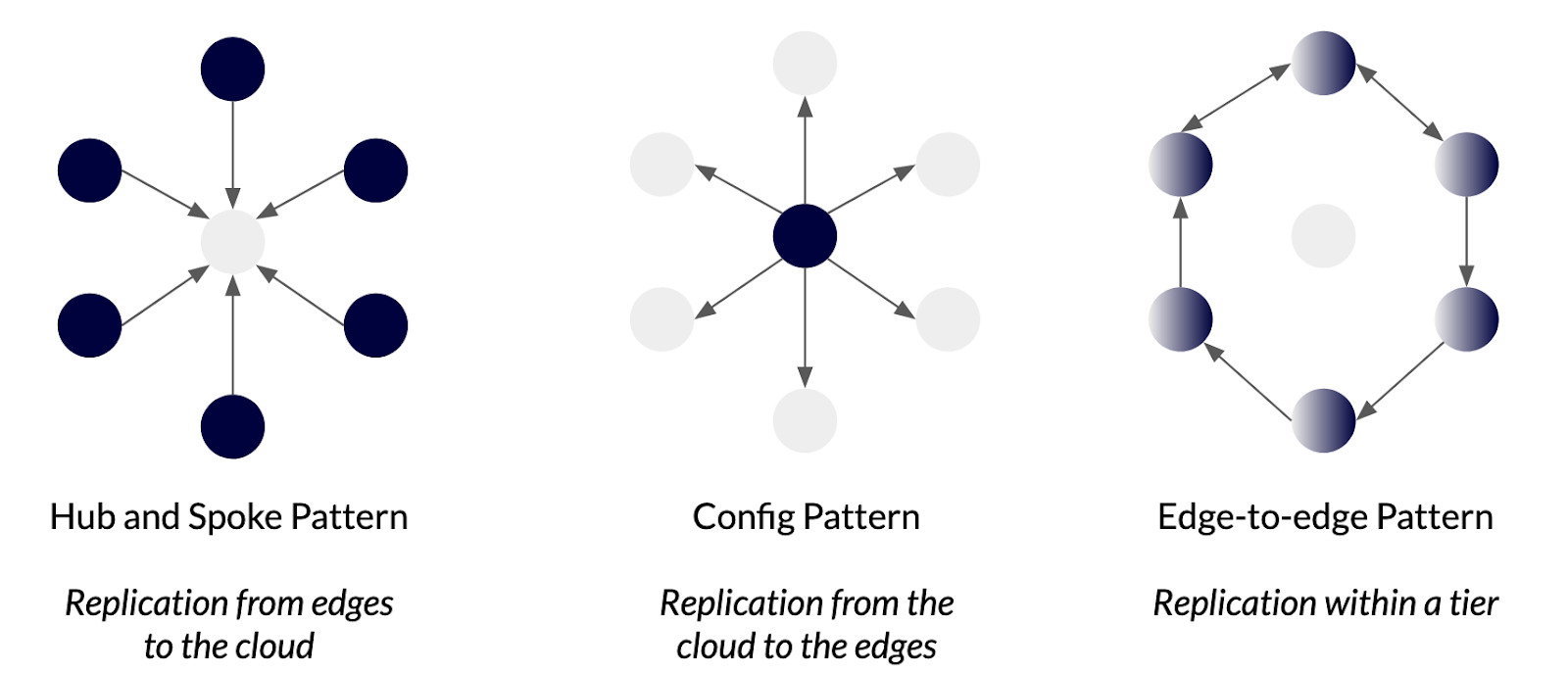
Data is typically replicated between the cloud and edge locations or within a tier. Some common deployment patterns include:
- Hub and spoke pattern – In this pattern, data is generated and stored in the edges. The central cluster in the cloud aggregates data from edges. This is a common pattern in IoT use cases and retail, where devices or store locations generate data which is then aggregated in the cloud for analysis.
- Configuration pattern – Data is stored in the cloud with read replicas at one or more edge locations. A good example of this is configuration settings for devices.
- Edge-to-edge pattern – This is a common pattern when data needs to be synchronously or asynchronously replicated or partitioned within a tier. The applications that use this pattern include vehicles that travel across different edge locations, mobile users in roaming mode, or users traveling between countries, making financial transactions.
Application Workload Types
Stateful edge applications typically combine the following workload types:
- Streaming Data – Streaming data comes from devices, users, and “things,” like vehicle telemetry, location data, etc. This data may need sanitizing before use. Streaming data requires high write throughput and fast querying.
- Analytics Over Streaming Data – Real time analytics applied to streaming data to generate alerts. This should be supported natively by the database, or by using Spark or Presto in conjunction with the database.
- Event Data – Events computed on raw streams that are then stored back in the database with ACID guarantees.
- Smaller Data Sets with Heavy Read-only Queries – This includes configuration and metadata workloads.
- Transactional, Relational Workloads – Examples include identity, access control, security, and privacy, where transactional semantics are important.
- Full-fledged Analytics of Data – Some applications need to analyze data in aggregate across different locations.
- Workloads Needing Long Term Data Retention – In some cases, organizations want to store data in a warehouse or data lake to analyze trends and events over longer periods. They may also need to store it for audit and compliance purposes.
A combination of the above workloads can run in different locations – the near/far edge or cloud. However, certain workloads work better in certain locations based on scale. Workloads 1-4 typically occur on the edge while 5-7 occur on the cloud.
Scaling Needs
How fast is your data growing? This means how many users, devices, etc., are generating data? And how much compute power is needed to process the data? For example, edge locations do not typically have the compute and storage resources required to run deep analytics on vast amounts of data. As a result, OLTP databases at the edge may need to scale throughput to handle massive write volumes.
Latency and Throughput Needs
How much data do you need to write and read? Will the data come in bursts or as individual data points? How quickly should it be available to users and applications? For example, with real-time applications like connected vehicles and credit card fraud detection, it is impractical to send telemetry or transaction data back to a cloud application to determine next steps. In these cases, real-time analytics is applied to raw data in edge locations to generate alerts.
Network Partitions
Poor network connectivity is a reality for many near and far edge locations. Consequently, applications should consider how to deal with network partitions. Different operating modes are possible depending on the network quality between the edge and the cloud:
- Mostly connected: This means applications can connect to a remote location to perform an API call (i.e., to lookup data) most of the time. A small fraction of these API calls may fail because of network partitions (i.e., a few seconds of partitions over several hours).
- Semi-connected: In this scenario, there could be an extended network partition – lasting several hours. Applications need to be able to identify changes that occurred during the partition window and synchronize their state with the remote applications once the partition heals.
- Disconnected: This is the predominant operating pattern. In this case, applications run independently of any external site. There may be occasional connectivity, but that is the exception rather than the norm.
Applications and databases that run in the far edge should be designed for disconnected or semi-connected operations. Near edge applications should assume semi-connected or mostly connected operation. The cloud operates in the mostly connected mode. So, when a public cloud service experiences an outage, the impact is severe and can last many hours.
Other Failures
In addition to network partitions, infrastructure outages can also occur in other locations. Everything from node/pod failures to a complete regional outage can happen at the far edge. Although node or pod outages are common at the near edge and in the cloud, applications can use racks and zones for higher resilience. Even with this fault isolation in place, region-level outages can occur.
Not all failures are outages; they can also include resource contention and resource exhaustion.
Software Stack Considerations
It is important you consider agility and ease of use when picking components for your software stack. Business services involve a suite of applications, so engineering teams must design for rapid application iteration. You can achieve this by using well-known frameworks that enable instant developer productivity (Spring, GraphQL, etc.) You should also adopt a well-known and feature-rich open source database to help developer productivity. Open source software offers deployment flexibility. Examples include PostgreSQL and YugabyteDB.
Security
Security is paramount whether your application runs in the cloud or at the edge. Especially as there is a large surface area of attack given the inherently distributed nature of the architecture. As a result, it is essential to consider least privilege everywhere, zero trust, and zero touch provisioning for all services and components.
Other security aspects to address include:
- Encryption in transit
- Encryption at rest
- Multi-tenancy support at the database layer and per-tenant encryption
- Regional locality of data to ensure compliance and achieve any geographic access controls that go with it
Explore the issues, challenges, and opportunities you create when building your stateful applications. Read our latest white paper, Stateful Applications at the Edge, for free. Download your copy today!

")
