YugaByte Announces Kubernetes StatefulSets Support to Enable Scale-Out PostgreSQL Deployments
December 10, 2018
YugaByte is excited to be at KubeCon today to announce Kubernetes StatefulSets support for our distributed SQL API which complements the transactional NoSQL APIs already generally available. YSQL is YugabyteDB’s PostgreSQL-compatible Distributed SQL API (currently in Beta). This new feature, available in YugabyteDB 1.1.7, cloud-native applications and microservices can rely on SQL and NoSQL to take full advantage of Kubernetes StatefulSets to power horizontally scalable, highly fault-tolerant data services, all without complicated, manually managed sharding and replication architectures.
What is YugabyteDB? YugabyteDB is an open source, transactional scale-out database that supports Kubernetes StatefulSets along with SQL, NoSQL and Key-Value compatible APIs.
Scale-out PostgreSQL with Kubernetes StatefulSets
When it comes to PostgreSQL, this game-changing capability mean clusters can now scale-out horizontally thereby avoiding the painful status-quo of monolithic PostgreSQL installations that need application-level sharding and complex replication architectures for large data workloads. In conjunction with scale-out capabilities, users of PostgreSQL also gain high performance NoSQL features, such as transactional key-value and flexible-schema data modeling plus MongoDB-like JSON support.
For those unfamiliar with Kubernetes StatefulSets, they are a critical feature for applications and databases because they enable the following capabilities:
- Stable, unique network identifiers
- Persistent storage across Pods
- Ordered, graceful deployment and scaling
- Ordered, automated rolling updates
Prior to StatefulSets, it wasn’t possible to shard PostgreSQL automatically on Kubernetes in order to achieve write scalability, while at the same time expecting your data to persist if the underlying pods went away.
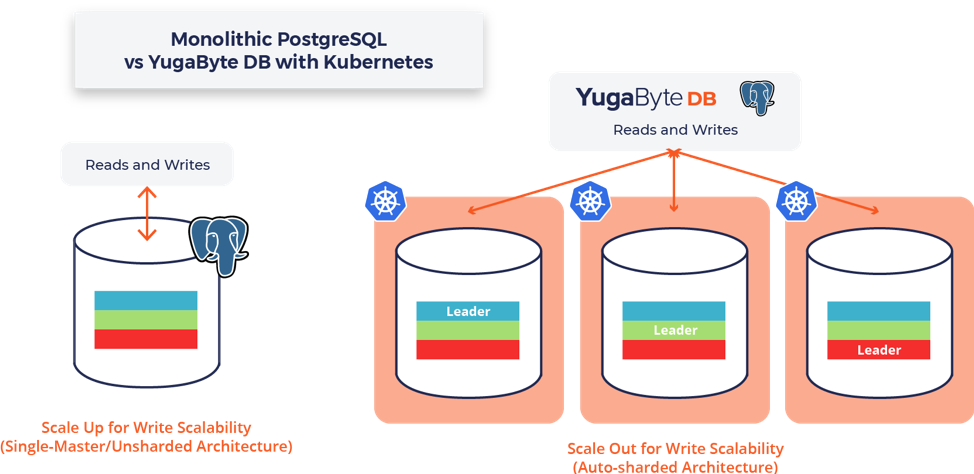
With YSQL’s support for Kubernetes StatefulSets, organizations who currently employ monolithic installations of PostgreSQL can now take advantage of the following benefits by making their data infrastructure truly “cloud native”:
- Linear write scalability on Kubernetes
- Transparently managed data distribution across pods with auto sharding and re-balancing
- Scale up or down without downtime or bottlenecks
- Distributed ACID transactions across multiple shards
- Low latency, tunably consistent reads
- Compatibility with PostgreSQL operations including DML and DDL commands, plus common features like; filters, JOINs, aggregations, functions, expressions and primitive user-defined datatypes.
- Support for additional NoSQL data models such as Cassandra-like flexible schema with JSON and Redis-like key-value.
While Hasura is a highly-available and scalable real-time GraphQL engine for PostgreSQL, the same cannot be said for PostgreSQL out-of-the-box. In fact, it is no secret that making PostgreSQL highly available AND scalable can be very challenging for developers. This is why we are excited about the combination of Hasura and YugabyteDB’s PostgreSQL compatible API. With this API, developers will get everything they love about PostgreSQL, but with high-availability, automatic data sharding, and failover built-in.
— Tanmai Gopal, Co-Founder Hasura
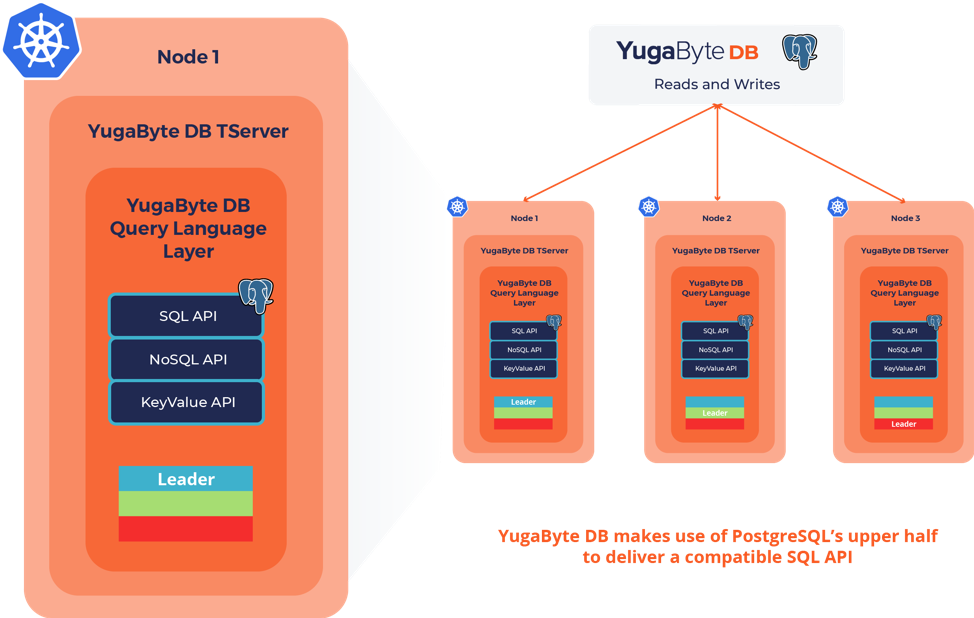
Reusing PostgreSQL Code vs Re-implementing
YugabyteDB has accomplished near perfect wire-compatibility with PostgreSQL by reusing much of the original C codebase vs re-implementing in another language. This ensures that many existing PostgreSQL apps will work with minimal modification, right out-of-the-box.
We made the strategic decision to reuse the upper half of PostgreSQL instead of re-implementing it in another language because it meant we could deliver wire compatibility much faster AND support new PostgreSQL features (like those coming in version 12) very easily, versus having to re-implement them.
“At Lead.com, our use case requires data distribution across availability zones and regions while simultaneously demanding strong consistency and support for ACID transactions. Because of these requirements, we’re excited to partner with YugaByte in the development of their distributed SQL API. Their reuse of the existing PostgreSQL code base, versus a re-implementation of it in another language, gives us the confidence that they’ll be able to deliver robust SQL functionality on the day we launch.”
— Tate Blahnik, CTO/Co-Founder at Robly/Lead.com
PostgreSQL Community Feedback
We are excited to be collaborating with various members of the PostgreSQL community on our SQL API and look forward to meeting many of you at Meetups and conferences in 2019!
“I’m excited to welcome YugabyteDB to the PostgreSQL community! YugabyteDB brings net new value to existing apps using PostgreSQL by offering scale-out SQL. And because YugabyteDB chose to reuse and not reimplement PostgreSQL, these apps can get immediate benefits. I am looking forward to YugaByte working closely with the PostgreSQL community to make PostgreSQL even better.”
— Mehboob Alam, PostgreSQL Evangelist
What’s Next?
- Deploy YugabyteDB on Kubernetes
- Read the “Understanding How YugabyteDB Runs on Kubernetes” blog post
- Explore YugabyteDB’s PostgreSQL compatible features
- Contact us to get your technical questions answered or to start an YugabyteDB Enterprise Edition trial

 in YSQL")
