5 Query Pushdowns for Distributed SQL and How They Differ from a Traditional RDBMS
March 4, 2020
A pushdown is an optimization to improve the performance of a SQL query by moving its processing as close to the data as possible. Pushdowns can drastically reduce SQL statement processing time by filtering data before transferring it over the network, filtering data before loading it into memory, or pruning out entire files or blocks that do not need to be read. PostgreSQL is a highly optimized single-node RDBMS when it comes to pushdowns. Because Yugabyte’s YSQL API reuses the upper half of PostgreSQL, it inherits these optimizations.
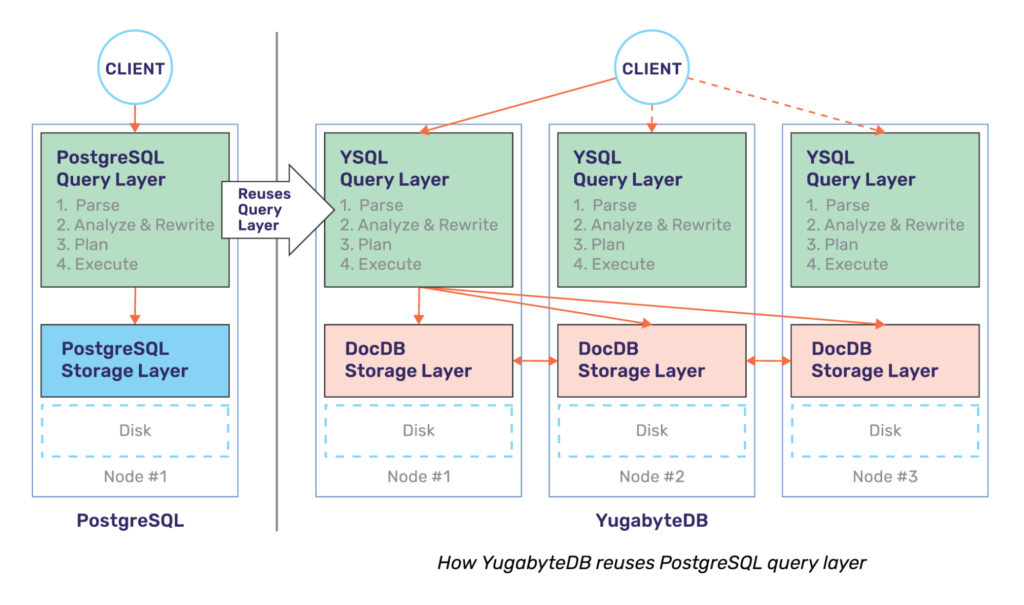
However, the pushdowns required in a distributed SQL database are different from those found in a traditional RDBMS such as PostgreSQL. This post explains the additional pushdown optimizations implemented in YugabyteDB to improve performance.
It’s all about the network
Broadly speaking, in a distributed SQL database like YugabyteDB most of the additional pushdown optimizations required (beyond that of a single-node RDBMS) come down to working around the latency and bandwidth limitations imposed by the network. These primarily include reducing the number of remote calls and the data transferred over the network. Thus, in order to optimize for the network, it is important to identify these scenarios across the various queries and optimize them by pushing down as much of the query processing logic close to the storage layer (called DocDB) as possible.
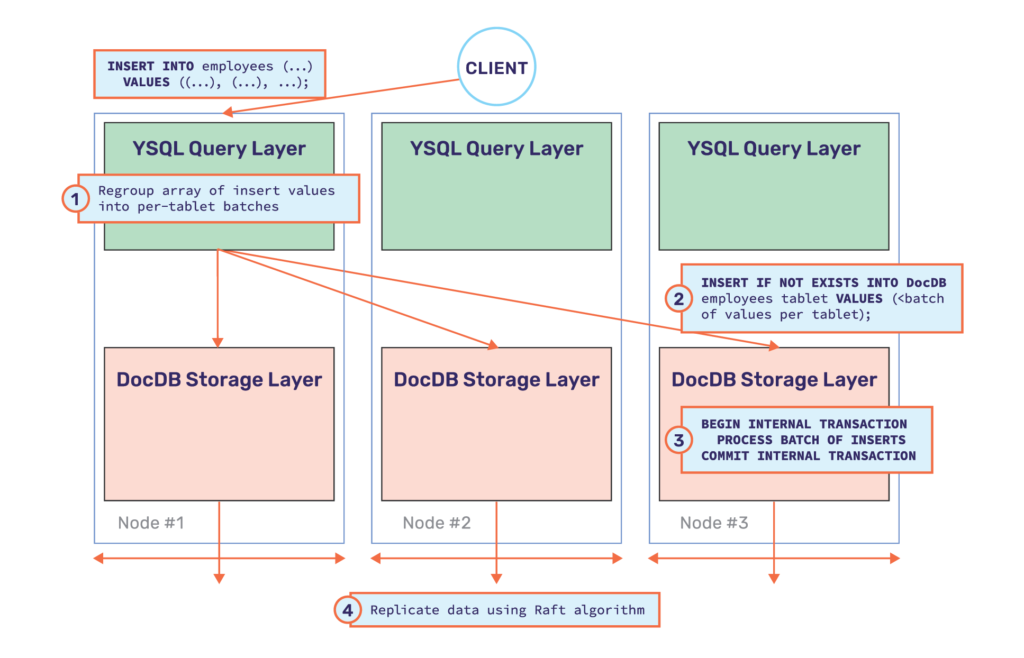
In order to enable more pushdowns, the underlying storage layer needs to be capable of performing as large a fraction of query processing as the query layer itself. YugabyteDB achieves this by reusing the PostgreSQL libraries at both the YSQL query layer as well as at the DocDB distributed storage layer. This is possible because the PostgreSQL libraries are implemented in C and DocDB is implemented in C++. Therefore there is no impedance to cross-language calls. This is shown diagrammatically below.
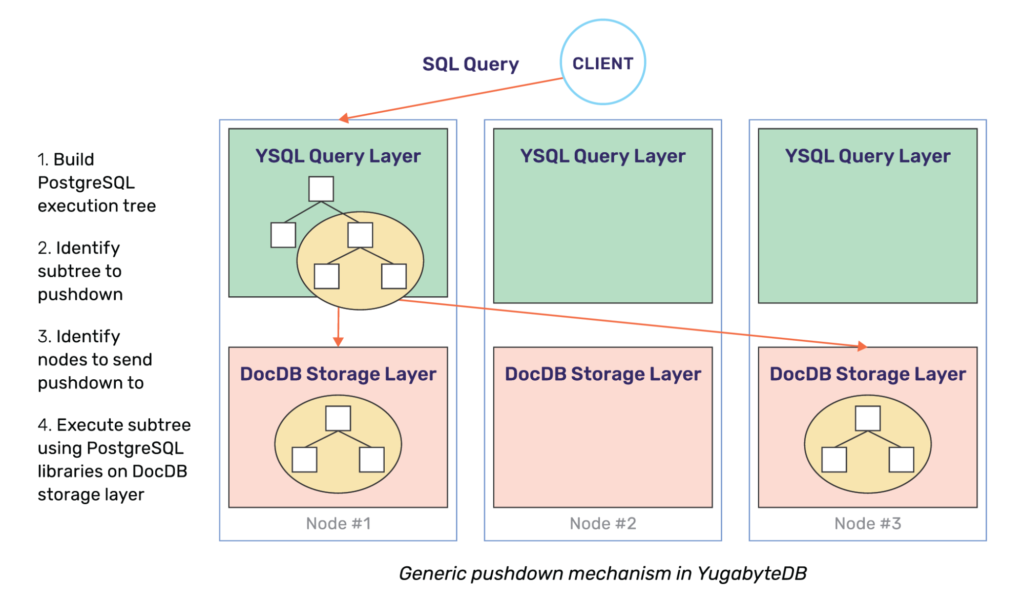
The rest of this post will explore 5 pushdown techniques for optimizing various queries.
- Single row operations
- Batch operations
- Filtering using index predicates
- Expressions
- Index-organized tables
For all the above techniques, we will be using the following table:
CREATE TABLE employees (
id BIGINT PRIMARY KEY,
name TEXT,
email TEXT NOT NULL,
hire_date DATE,
salary INT
);
Pushdown #1: Single row operations
This class of pushdowns deals with operations such as single row inserts and updating or deleting a row using the primary key value. We will take the case of a simple SQL INSERT statement into the user table mentioned above. An example is shown below.
INSERT INTO employees (id, name, email, hire_date, salary)
VALUES (1, 'James Bond', 'bond@yb.com', NOW(), 1000);
PostgreSQL execution plan
If the above insert statement were to be executed by PostgreSQL, then the execution plan would look as follows:
1. BEGIN INTERNAL TRANSACTION
2. LOCK id=1 so no one can update the row with id=1 if present
3. SELECT id=1 FROM employees table
4. If row with id=1 is present:
RAISE unique constraint violation of primary key
If no row exists with id=1:
INSERT row
5. UNLOCK id=1
6. COMMIT INTERNAL TRANSACTION
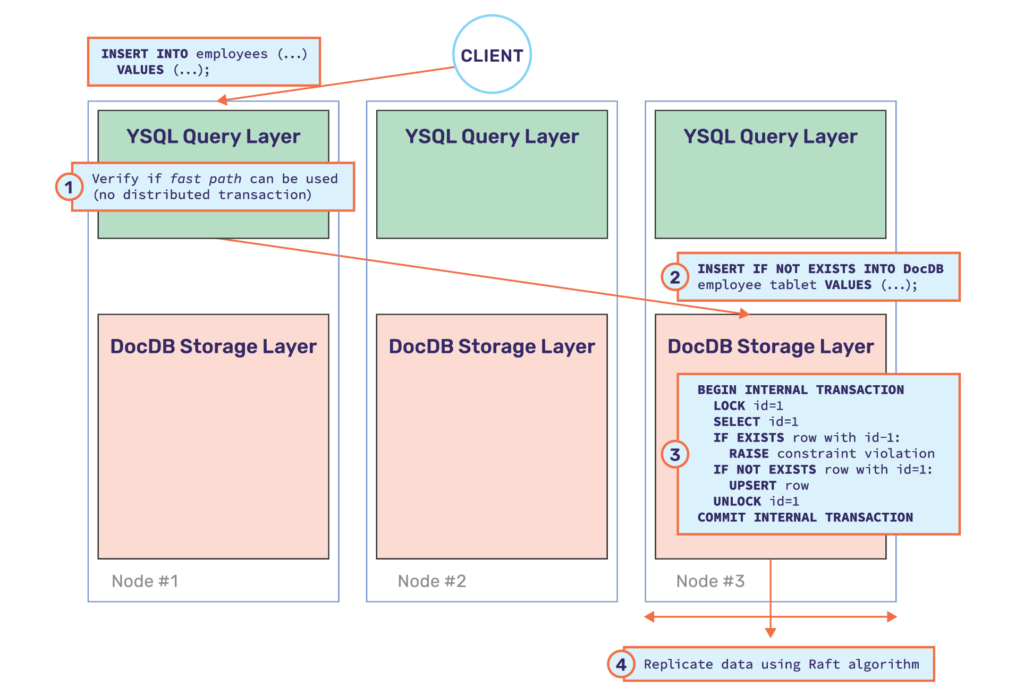
YugabyteDB execution plan – pushdown the whole operation
In the case of PostgreSQL, the above set of steps occurs on a single node with many of the steps performing only in-memory changes. However, if the above steps are executed as is in YugabyteDB, they would each become an RPC call over the network from the query layer to the distributed storage layer (called DocDB). This insert would end up requiring 4-6 remote RPC calls because without a pushdown, we would need to:
- Perform two RPCs – first to select and lock row id=1, followed by inserting the row
- Because the above are two separate steps, it requires the distributed transactions framework which need additional RPCs calls
The above makes the operation extremely slow. In order to improve performance, YugabyteDB pushes this entire transaction down to the DocDB layer which eliminates the first set of RPC calls. But upon doing so, YugabyteDB can now avoid a distributed transaction and opt for the fast path. Hence, this pushdown eliminates both of the above steps and incurs just one RPC call over the network from the query layer to the DocDB layer as shown below.
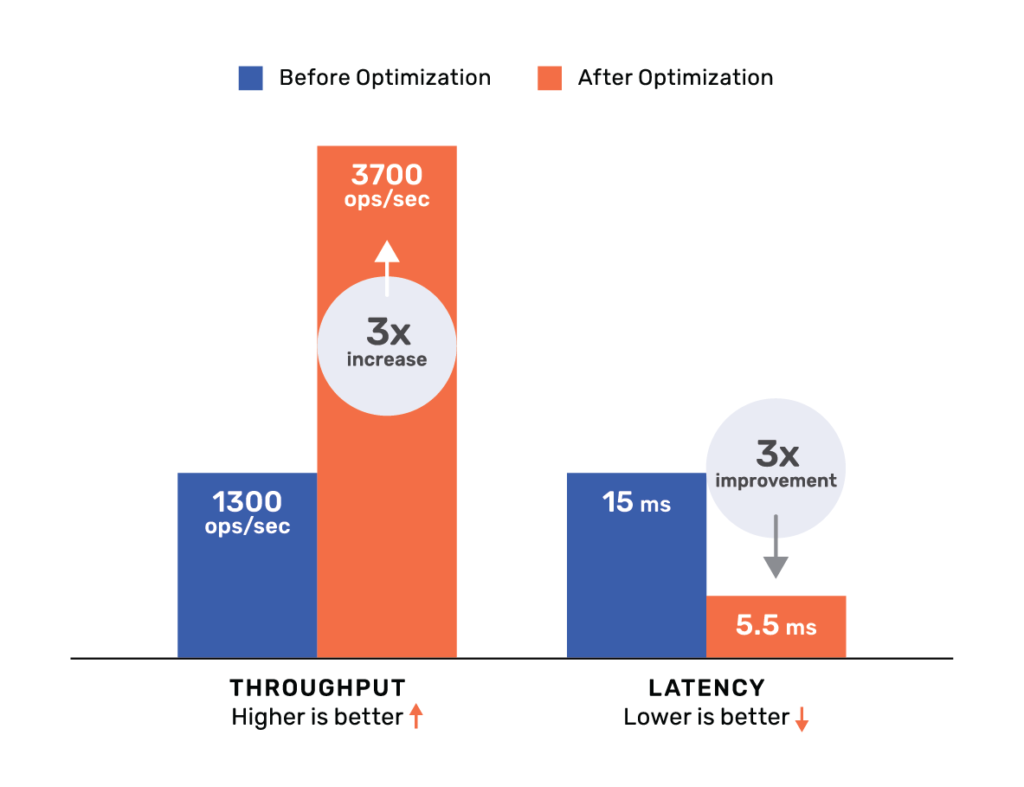
Performance gain – 3x better
This pushdown yielded not only a 3x increase in throughput (~1300 ops/sec before the change to ~3700 ops/sec after the change) but also a 3x improvement in query latency (~15ms per operation before the change to ~5.5ms per operation after the change). Note that for geo-distributed deployments where the replicas are far away from each other, this pushdown could yield an even bigger gain.
Pushdown #2: Batch operations
A distributed SQL database internally shards the rows of a table and distributes it across multiple nodes of a cluster to achieve horizontal scalability. In doing so, there is a real possibility that multi-row operations become punitive if care is not taken to appropriately batch them. Below are some scenarios where batched operations are exercised directly or indirectly.
Scenario A: INSERT with array of values
An INSERT statement with an array of values, all of which is handled as one transaction.
INSERT INTO employees ( id, < columns > )
VALUES ( 100, < values > ),
( 101, < values > ),
( 102, < values > ),
...
( 200, < values > );
Scenario B: COPY FROM command
Very often, data is batch loaded into the database from an external CSV file using the COPY FROM command as shown below.
COPY employees FROM 'data.csv' WITH (FORMAT csv, ESCAPE '\');
Scenario C: SELECT with an IN clause
When multiple rows need to be selected from a table, the IN clause is often used. For example, the query below looks up information about 40 employees whose ids are known ahead of time.
SELECT * FROM employees WHERE id IN (5, 10, 15, … , 200);
Scenario D: Nested queries
There are many use cases for nested queries. As an example, let’s say we want to insert rows from one table into another based on a filter condition. This can be achieved with the INSERT INTO statement, with a nested SELECT statement and a WHERE clause. The example shown below selects those employees that were hired after Jan 01, 2015 from the employees table and inserts them into the recent_employees table.
INSERT INTO recent_employees (
SELECT * FROM employees
WHERE hire_date > to_date('Jan 01, 2015','Mon DD, YYYY')
);
PostgreSQL execution plan
Let us analyze the statement in sub-section A above as an example. In this case, we have an INSERT statement with an array of values.
The PostgreSQL execution plan would simply insert each of the values one at a time – with some parallelism, since all of the resulting inserts would be written to just one node.
YugabyteDB execution plan – reorder into per-tablet batches
The above execution plan on the YSQL layer would also end up inserting one row at a time – perhaps with some parallelism. But the rows of a table in YugabyteDB are often transparently sharded into tablets residing across multiple nodes. This implies that these inserts would need to be sent to the appropriate nodes, making an execution plan that acted on one row at a time prohibitively expensive. While this is a perfectly optimal execution plan for a single node RDBMS, in a distributed SQL database each of these inserts would incur a remote RPC call. The overall operation would slow down significantly because of the network overhead of each RPC call.
In order to optimize batch operations, YugabyteDB implements buffering and regrouping of sub-operations as two key strategies. These are handled in a manner that is transparent to the end user and without sacrificing ACID transactional guarantees.
- Batching sub-operations: In cases when the PostgreSQL execution plan occurs one row (or sub-operation) at a time, it is critical to collect a batch of rows to prevent each row from generating RPC calls. These batches of rows would often need some additional processing, such as constraint checks. These constraint checks can be cached across these batches to make them much more efficient and cut down the number of RPC lookups.
- Regrouping sub-operations: Regrouping the sub-operations (or the collected batches) is done so that the entire group can be handled in one RPC call. The collected batch of rows is regrouped in such a way that all the rows belong to one tablet, which is fully hosted by a single node.
Performance gain – 15x and 35x
As a simple experiment, we tried Inserting 50K rows using the COPY command before and after the change. The results of this experiment are shown below.

Another simple experiment to demonstrate the performance gain due to this pushdown is to insert 100K rows using the following nested query:
INSERT INTO t SELECT generate_series(1, 100000);
The times taken for this command to execute before and after this optimization are shown below.

Pushdown #3: Filtering using index predicates
Queries that return a small set of rows can run much faster if they are able to utilize indexes. Let’s add an index to the table, so that our schema looks as follows.
CREATE TABLE employees (
id BIGINT PRIMARY KEY,
name TEXT,
email TEXT NOT NULL,
hire_date DATE,
salary INT
);
CREATE INDEX idx_emp_salary ON employees (salary);
Now consider the following example to query all employees with a salary of 2000.
SELECT * FROM employees WHERE salary = 2000;
The idx_emp_salary index on the salary column can speed this query up significantly (assuming it returns only a handful of employees). PostgreSQL would opt to use the index in order to satisfy this query, which would be the case with YugabyteDB as well since it reuses the query execution engine. Let us look at what changes had to be made to optimize this query for a distributed SQL database.
PostgreSQL execution plan
The PostgreSQL execution plan for this query is to lookup the row ids (called object identifiers or OIDs for short in PostgreSQL) from the index table idx_emp_salary and fetch all the column values for each of these rows from the primary table. This is shown in a pseudocode notation below.
1. BEGIN INTERNAL TRANSACTION 2. FETCH set of OIDs from idx_emp_salary with salary = 2000 3. FETCH column values for each OID from employees table 4. COMMIT INTERNAL TRANSACTION
YugabyteDB execution plan – pushdown or batch aggressively
Since the query layer of Yugabyte SQL is the same as PostgreSQL, the index scan would be used. This can be verified by running the EXPLAIN command as shown below.
yugabyte=# EXPLAIN SELECT * FROM employees WHERE salary=2000;
QUERY PLAN
---------------------------------------------------------------------------
Index Scan using idx_emp_salary on employees (cost=... rows=... width=...)
Index Cond: (salary = 2000)
(2 rows)
Because both the index and the data are distributed in YugabyteDB, both step 2 (fetching the set of OIDs) and step 3 (fetching column values for each of these OIDs) could incur a lot of remote RPC calls and therefore need to be optimized.
Pushdown where possible
The first optimization is to identify if the table and the index are on the same tablet (each replica for a tablet is always hosted on one node). In this case, the entire operation can be pushed down to the storage layer, where all of the above operations would be executed but incur only one RPC call.
An example of when this would occur is if the tables in a database are colocated. Colocating various SQL tables puts all of their data into a single tablet, called the colocation tablet. Note that all the data in the colocation tablet is still replicated across 3 nodes (or whatever the replication factor is). You can read more about the design of colocated tables here.
Aggressive batching
If the index and the table shards fall on different nodes, the query can be optimized by batching aggressively. Making one RPC call for each of the OIDs in the set returned by step 2 (fetch set of OIDs from the index table) would be slow. These OIDs can be regrouped and batched so that there are much fewer RPC calls made (one per tablet), which would improve the performance dramatically. The new execution plan would look as follows.
1. BEGIN INTERNAL TRANSACTION 2. FETCH set of OIDs from idx_emp_salary with salary = 2000 3. REGROUP OID set into 1 batch per tablet 4. FETCH values for each batch of OIDs from employees tables 5. COMMIT INTERNAL TRANSACTION
The above execution plan would cut one RPC call per row returned into one RPC call per tablet (which can be further optimized into one RPC call per node).
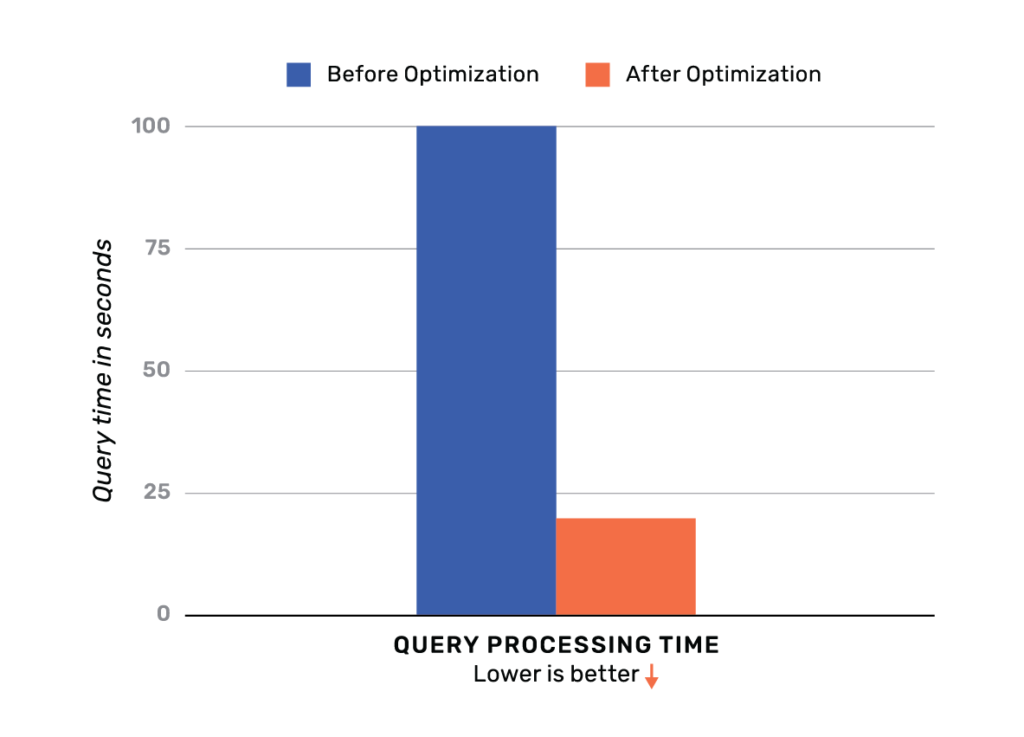
Performance gain – 5x improvement
To test the gain from this optimization, we insert 1000 rows into a table, and write a query that selects 500 rows from an index. This optimization yielded a 5x improvement in latency. The following query was run to fetch data from the standard airports dataset.
SELECT * FROM airports WHERE iso_region = 'US-CA' ORDER BY name DESC;
The time taken to run the above query is shown graphically below.
Pushdown #4: Expressions
PostgreSQL has rich support for expressions. They can be used in a variety of contexts, such as in the target list of the SELECT command, as new column values in INSERT or UPDATE, or in search conditions in a number of commands. The expression syntax allows the calculation of values from primitive parts using arithmetic, logical, set, and other operations [3].
Since YugabyteDB re-uses PostgreSQL, it supports the full range of expressions. Examples of expressions include:
- A constant or literal value
- A column reference
- A positional parameter reference, in the body of a function definition or prepared statement
- A field selection expression
- An operator invocation
- A function call
- An aggregate expression
- A window function call
- A type cast
- A scalar subquery
- An array constructor
- A row constructor
There are a number of other examples in addition to the above list. As an example, let us analyze the following query, which computes the total salary being paid across all employees.
SELECT SUM(salary) FROM employees;
PostgreSQL execution plan
The PostgreSQL execution plan for this query is to simply add the values of the various salaries across all the employees. This is shown in a pseudocode notation below.
1. BEGIN INTERNAL TRANSACTION 2. FETCH salary column from all rows 3. Apply the SUM function on the salary values across the rows 4. COMMIT INTERNAL TRANSACTION
YugabyteDB execution plan – pushdown or batch aggressively
Pulling the rows from the storage layer to the query coordinator in order to compute the sum implies that all the values for the salary column across each row gets sent across the network to the query coordinator. This would result in poor performance both due to a lot of network traffic and the fact that only the query coordinator is computing the sum. YugabyteDB instead pushes down the sum computation using the SUM built-in function to the storage layer on each tablet.
To optimize this query, YugabyteDB pushes the sum computation down to each tablet in DocDB. This requires DocDB to be able to invoke the SUM built-in function. Whilst the SUM function may seem trivial at first glance, note the following:
- The SUM function in DocDB should handle adding various types such as integers, floating points, decimals, etc.
- It should perform appropriate type conversions between the numeric types just like PostgreSQL would.
- There are a number of functions and operators in addition to SUM that need to be handled.
In consideration of all the above points, the DocDB layer could natively link to and run the PostgreSQL libraries to perform these computations. The execution plan now looks as follows. Note that currently this optimization is currently under implementation, and pushdowns are limited to certain scenarios and types. However, there is on-going work to improve this.
1. BEGIN INTERNAL TRANSACTION 2. FETCH a list of SUM(salary) results from all tablets 3. Apply the SUM function on the result list above 4. COMMIT INTERNAL TRANSACTION
Pushdown #5: Index-organized tables
If a primary key is specified at table creation time, YugabyteDB will create an index-organized table. For at-scale usage, index-organized tables are strongly recommended. Creating a table without a primary key and specifying an index after the fact would have the following disadvantages:
- Maintaining the primary table and the index would result in an increase in the overall data set size.
- Many queries would run slower because they would need to access the primary and the index tables thereby increasing the total remote RPC calls and bytes transferred over the network.
Note that the table created in the example below is index-organized because the primary key is specified as a part of the CREATE TABLE statement.
CREATE TABLE employees (
id BIGINT PRIMARY KEY,
name TEXT,
email TEXT NOT NULL,
hire_date DATE,
salary INT
);
CREATE UNIQUE INDEX idx_emp_unique_email ON employees (email);
CREATE INDEX idx_emp_salary ON employees (salary ASC);
Predicate pushdowns
A predicate (in mathematics and functional programming) is a function that returns a boolean (true or false) [4]. In SQL queries predicates are usually encountered in the WHERE clause and are used to filter data. Pushing down a predicate to where the data lives can drastically reduce query/processing time by filtering out data earlier rather than later.
In YugabyteDB, predicate expressions evaluating if primary key and index columns are equal to, greater than, or less than a target value are pushed down to the DocDB layer. Below are some examples of queries that would be pushed down.
# Equality on primary key column. SELECT * FROM employees WHERE id = 1; # Equality on index column. SELECT * FROM employees WHERE email = 'bond@yb.com'; # Less than and greater than on index column. SELECT * FROM employees WHERE salary > 1000 AND salary < 2000;
Sort elimination
If a table is defined with a sort order (ASCENDING or DESCENDING) specified on the primary key and index columns, the data in DocDB is also stored in a corresponding sorted manner on disk. When this table is queried, the YSQL query layer re-uses this natural sort order in DocDB if possible to avoid doing another sort. Note the following about sort elimination using DocDB:
- Sort elimination pushdown can be performed in the case of multi-column primary keys or indexes also. However, this depends on the exact query being processed.
- Data in DocDB can be stored in an ASCENDING or DESCENDING sorted order.
- If a table in DocDB is sorted one way (let’s say ASCENDING), it can return data sorted in either ASCENDING order (the natural sort order) or DESCENDING order (by iterating through the data in the reverse direction).
LIMITs and OFFSETs
Pushing down LIMIT and OFFSET statements can greatly improve performance by both reducing the size of data read from disk as well as transferred over the network. Since DocDB has support for LIMIT and OFFSET in a number of queries, these are pushed down. Below are some example queries where this is done.
# Return employees #50 to #60 (from a fixed, unsorted list). SELECT * FROM employees LIMIT 10 OFFSET 50; # Return 10 employees whose salary is greater than 1000. SELECT * FROM employees WHERE salary > 1000 LIMIT 10;
Future work
Though a number of pushdown optimizations have gone into YugabyteDB to improve performance over a cluster of nodes, the work is far from complete. We’re looking at even more enhancements, below are a few examples.
- Pushing down an entire execution subtree. For example, pushing down the entire set of predicates and multi-column expressions.
- Optimize GROUP BY queries with pushdowns.
- Another area of ongoing work is to improve parallel queries to the DocDB storage layer.
- Cost-based optimization of queries is also in progress. Given YugabyteDB is a geo-distributed database, the idea is to enhance the PostgreSQL cost optimizer (which is available in its entirety) to not just be aware of table sizes but also geo-location of tablets.
References
[1] Internals of PostgreSQL – process and memory architecture
[2] Internals of PostgreSQL – buffer manager
[3] PostgreSQL expressions
[4] What is a predicate pushdown


