Distributed PostgreSQL on a Google Spanner Architecture – Query Layer
March 18, 2019
Our previous post dived into the details of the storage layer of YugabyteDB called DocDB, a distributed document store inspired by Google Spanner. This post focuses on Yugabyte SQL (YSQL), a distributed, highly resilient, PostgreSQL-compatible SQL API layer powered by DocDB. A follow-up post will highlight the challenges faced and lessons learned when engineering such a database.
YSQL, Distributed PostgreSQL Made Real
Yugabyte SQL (YSQL) is a distributed and highly resilient SQL layer, running across multiple nodes. It is compatible with the SQL dialect and wire protocol of PostgreSQL. This means that developers familiar with PostgreSQL can fully reuse their knowledge (and the standard PostgreSQL client drivers) to build an application powered by YSQL.
YSQL essentially transforms the monolithic PostgreSQL database into a DocDB-powered distributed database. To accomplish this, it reuses open source PostgreSQL’s query layer (written in C) as much as possible.
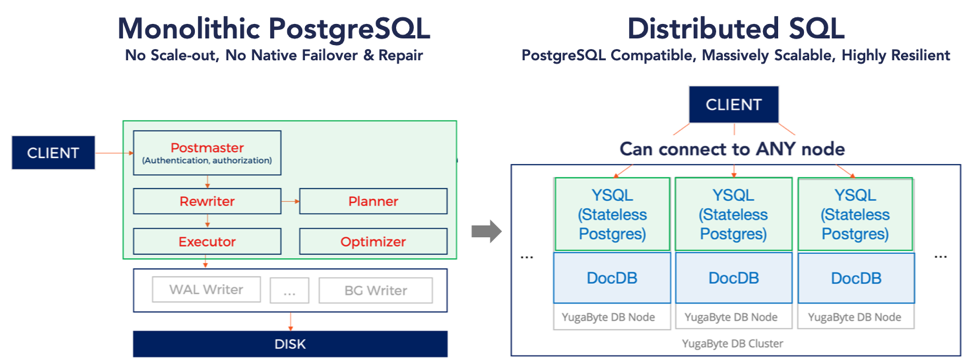
Following were the design goals we set for YSQL early on.
- Reuse the open source, mature and feature-rich PostgreSQL query layer
- Preserve existing PostgreSQL functionality and extend as necessary
- Enable migrations to newer versions of PostgreSQL by implementing features in a modular approach
Relentless execution towards the above goals has paid rich dividends. YSQL now supports a wider range of existing PostgreSQL functionality than we had originally expected. This is evident from the v1.2 feature matrix, examples being:
- DDL statements:
CREATE, DROPandTRUNCATEtables - Data types: All primitive types including numeric types (integers and floats), text data types, byte arrays, date-time types,
UUID, SERIAL, as well asJSONB - DML statements: Most statements such as
INSERT, UPDATE, SELECTandDELETE. Bulk of core SQL functionality now supported includesJOINs, WHEREclauses,GROUP BY, ORDER BY, LIMIT, OFFSETandSEQUENCES - Transactions:
ABORT, ROLLBACK, BEGIN, END, andCOMMIT - Expressions: Rich set of PostgreSQL built-in functions and operators
- Other Features:
VIEWs, EXPLAIN, PREPARE-BIND-EXECUTE, and JDBC support
As for the design goal of migrating to newer versions, YSQL started with the PostgreSQL v10.4 and recently rebased to PostgreSQL v11.2 in a matter of weeks!
How YSQL Works?
YSQL internals can be categorized into four distinct areas:
- System catalog management
- User table management
- The read and write IO Path
- Mapping SQL tables to a document store
The next sections detail each of the above areas. Before diving into the details, here’s a quick recap of DocDB from the first post of this series.
- Every table in DocDB has the same schema: one key maps to one document.
- As a distributed database, it replicates data on each write.
- Offers single-key linearizability and multi-key snapshot isolation (serializable isolation is in the works).
- Native support for secondary indexes on any document attribute.
- Efficient querying and updating a subset of attributes of any document.
System Catalog Management
The PostgreSQL documentation on system catalogs says that the system catalogs are regular tables where schema metadata is stored, such as information about tables and columns, and internal bookkeeping information. The initdb code path in PostgreSQL, which is completely different from the code path the deals with user tables, creates and initializes system catalog tables. So, in order to make a distributed SQL database with no single points of failure, it is essential to replicate these system catalogs.
1. Initialize system catalog through initdb

When YSQL starts up for the first time, a modified initdb executes and creates the system catalog a replicated, single-tablet system catalog table in DocDB. This is shown in the figure above.
The system catalog tablet in DocDB forms a Raft group, which replicates data onto a set of nodes and can tolerate failures. In the figure above, the system catalog tablet leader is shown with a solid border while the followers are shown with a dotted border. This ensures that PostgreSQL can still rely on the familiar system catalog in order to function.
2. Ready to serve apps
Once the system catalogs are created, YSQL can be used by applications. Since the data is replicated across nodes and persisted on disk, initdb is not needed on subsequent restarts of the cluster.
User Table Management
Now that the YSQL cluster is up and running, let us consider the scenario when a user creates a table. This happens in the following four steps.
1. Parse and analyze the query
Just as with PostgreSQL, the query is received by PostgreSQL server process – which parses, analyzes and executes the query.
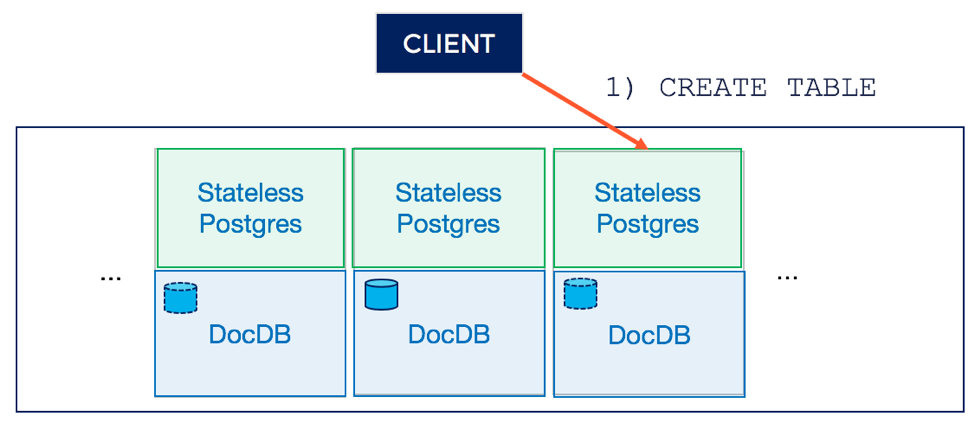
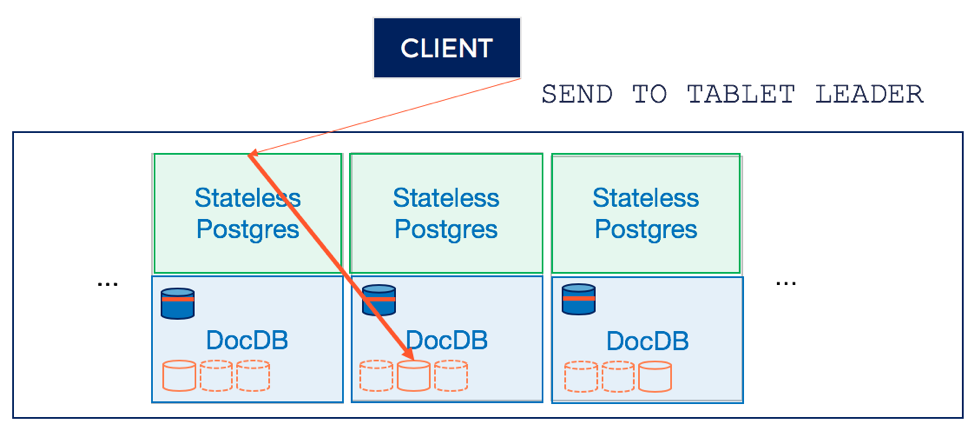
2. Route query to tablet leader of DocDB system catalog
In the case of a regular PostgreSQL, the execution phase would add entries to the system catalog tables and create some directories and files on the local filesystem. In the case of YSQL, this update to the system catalog is sent to the tablet leader of the distributed system catalog table in DocDB.
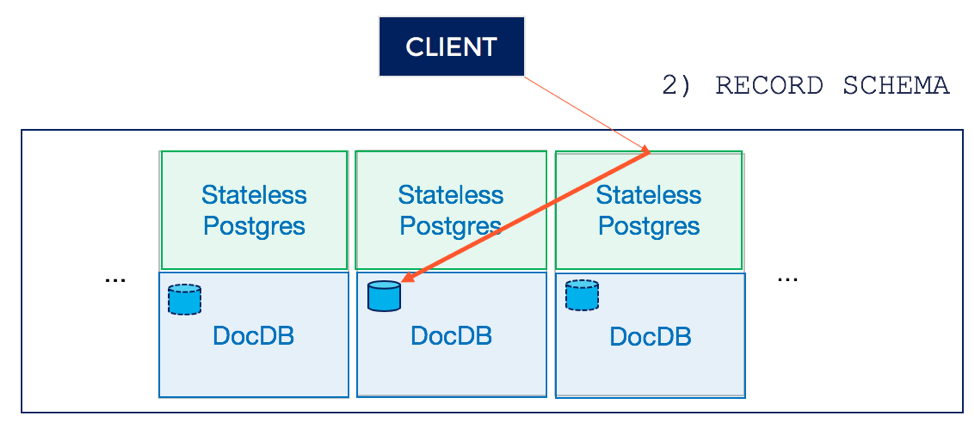
3. Replicate system catalog entry across nodes in DocDB
The tablet leader of the distributed system catalog table in DocDB is responsible replicating the update to the followers. This is done using Raft consensus, which ensures that the update is linearizable even in the presence of faults.
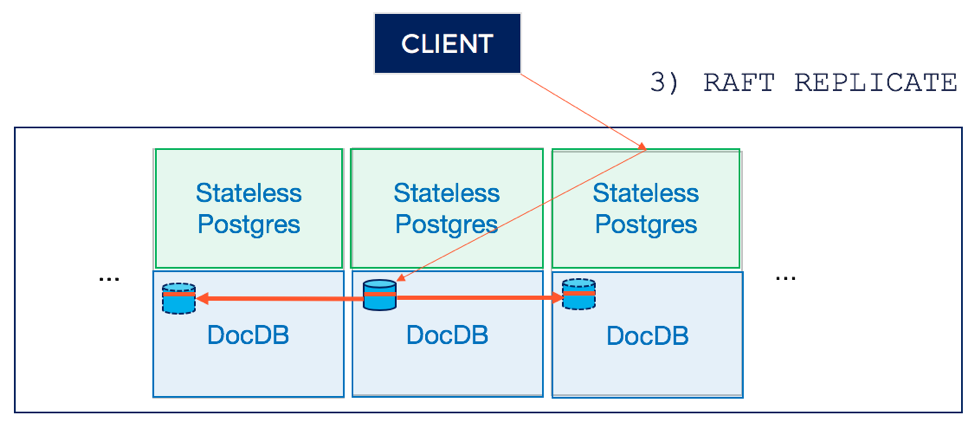
4. Create user table in DocDB
Now that the entry has been persisted in the system catalog, the next step of the execution phase is to create a distributed DocDB table. This involves creating a number of tablets (which have replicas) across a set of nodes. This is shown in the diagram below.
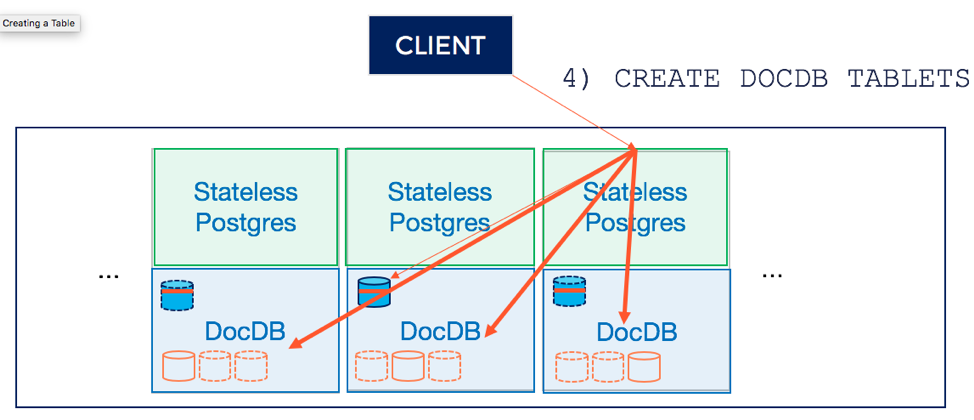
Once the above steps are complete, the table is ready to use.
Read/Write IO Path
The read and write IO paths are quite similar. Let us understand the write IO path, which involves replication of data in DocDB. The read IO path is similar, except for the last step which can serve data directly from the leader of the tablet in DocDB.
1. Parse and analyze the query
Just as with PostgreSQL, the PostgreSQL server process receives the query. It then goes through the parser, analyzer, planner and the executor. Some of the planning, analysis and execution steps, however, are different to accommodate a distributed database instead of the local store.
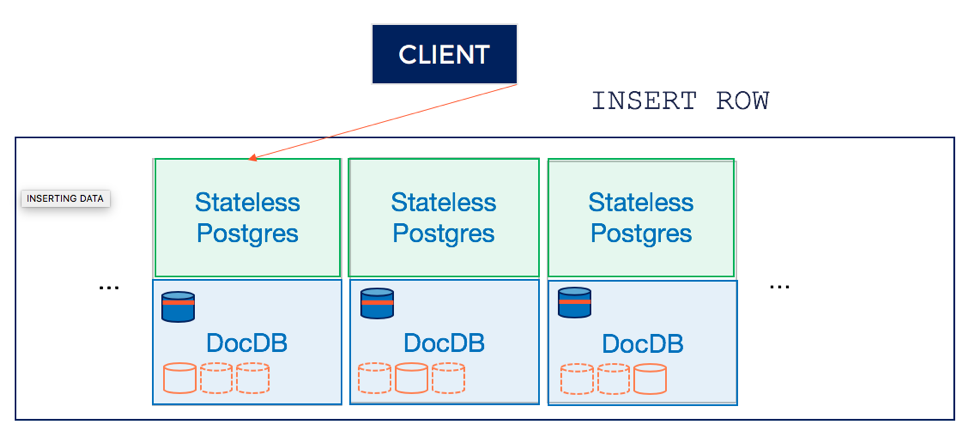
2. Route the insert to the tablet leader
The SQL insert statement may end up updating a single row or multiple rows. Although DocDB can handle both cases natively, these two cases are detected and handled differently to improve the performance of YSQL. Single row inserts are routed directly to the tablet leader that owns the primary key of that row. Every node also has a built-in transaction manager to coordinate distributed transactions. Inserts affecting multiple rows are handled by this transaction manager (at the node that receives the request first). The single-row insert case is shown below.
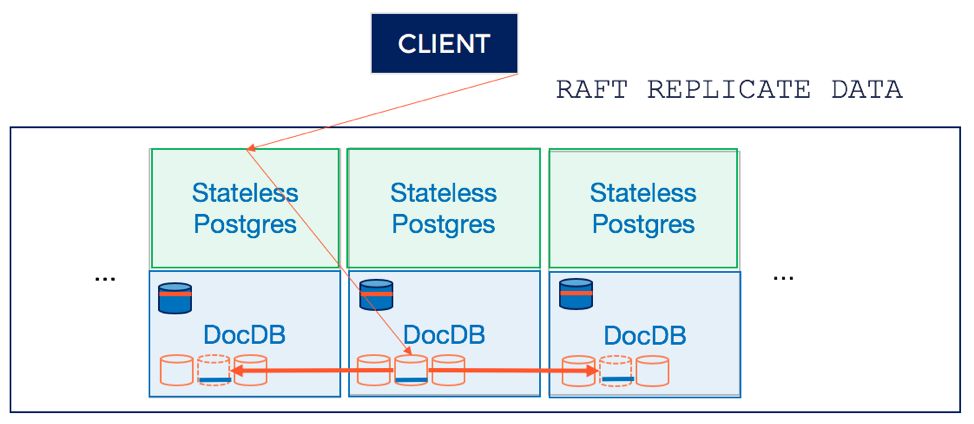
3. Replicate the write through Raft
In the of single-row inserts, the tablet leader replicates the data using the Raft protocol onto the followers. This simpler case is shown below. In the case of multi-row inserts, the transaction manager writes multiple records (transaction status records, provisional records, etc) across tablets (often on different nodes). Each of these writes are replicated using Raft consensus. The hybrid logical clock or HLC tracking in the cluster serves as a coarsely synchronized, highly available global clock to coordinate writes. This results in the writes being fault tolerant, with a high-performance system.
Mapping SQL Tables to Documents
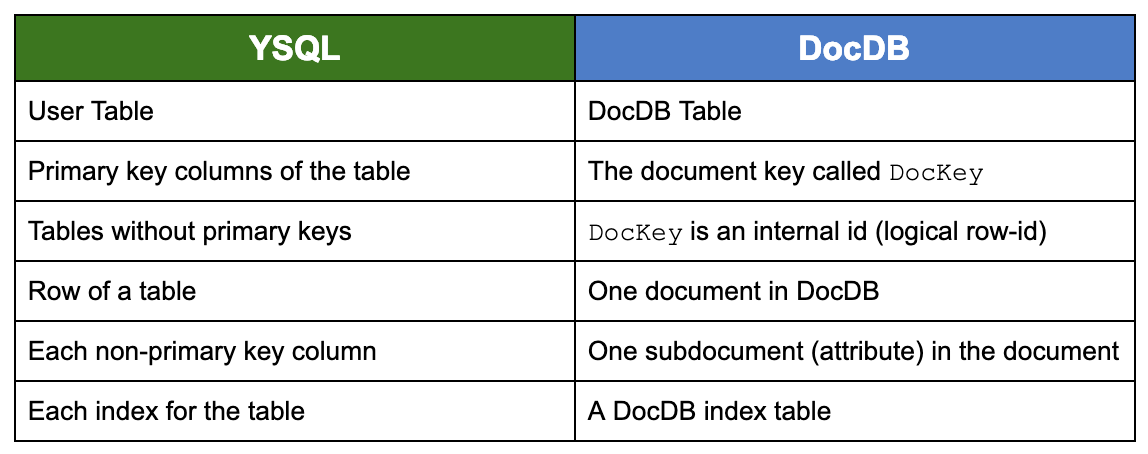
Each user table in YSQL maps to a corresponding DocDB table with multiple tablets. The YSQL tables come with their own schemas, while all the DocDB tables have the same schema, which is shown below. The actual schema enforcement is done using table schema metadata.
DocKey → { Document Value }The combined set of primary key column values are used to construct the DocKey above. Each of the value columns (non-primary key columns) are mapped to one attribute in the Document Value above.
The various YSQL constructs are mapped to suitable DocDB equivalents. This is shown in the table below.
So how does this look in practice? Let us take an example. Consider the following rather simple table.
CREATE TABLE msgs (
user_id TEXT,
msg_id INT,
subject TEXT
msg TEXT,
PRIMARY KEY (user_id, msg_id);This will correspond to a DocDB table that has a document key to value schema. Now, lets us perform the following insert at time T1.
T1: INSERT INTO msgs (user_id, msg_id, subject, msg)
VALUES ('user1', 10, 'hello', 'hello world');This will get translated into the following entries in the DocDB table.
DocKey ('user1', 10):
{
column_id (subject), T1 -> 'hello',
column_id (msg), T1 -> 'hello world'
}
YSQL Benefits
A YSQL cluster appears as a single logical PostgreSQL database to applications. All nodes in the YSQL layer are identical and application clients can connect to any node in order to read or write data. Along with maximum PostgreSQL compatibility, such an architecture delivers a number of benefits.
Horizontal Write Scalability
Since DocDB is capable of being scaled out on demand, a stateless YSQL tier makes it easy to add nodes on demand. This enables rapid scaling of the cluster when more resources (CPU, memory, storage capacity) are required.
Highly Resilient w/ Native Failover & Repair
The underlying DocDB cluster is fault-tolerant. This means that node failures do not affect the SQL application using this distributed SQL database. It simply starts communicating to a new node as opposed to native PostgreSQL where the common approach of master-slave replication inevitably leads to manual failover and/or inability to serve recent commits.

Geo-Distribution w/ Multi-Region Deployments
DocDB supports geo-distributed deployments, meaning you can deploy a distributed SQL database across different geographic regions and zone.
Cloud Native Operations
DocDB allows dynamically changing nodes of the database with no app impact. Schema changes as well as infrastructure migrations are now zero downtime, even for a SQL database.
Summary
Bringing together two iconic database technologies such as Spanner and PostgreSQL into a new open source, cloud native database has been an immensely satisfying engineering achievement. However, we understand that a well-engineered database on its own right does not build trust in the minds of developers and architects. We have to earn that trust using the traditional means of communication, collaboration and sharing of success stories.
Through this series of posts, we explain our design principles, the tradeoffs associated with those principles, the actual implementation details and finally, the lessons learned especially around some of the more challenging aspects. We intend to prove our claims through exhaustive correctness testing (such as Jepsen) as well as comprehensive performance benchmarking (including TPCC). As we make rapid progress towards YSQL GA this summer, we are working closely with a few of our current users to highlight how YSQL can complement their existing investment in YugabyteDB. If your project can benefit from YSQL as well, don’t hesitate to reach us on our community Slack channel.
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.

")
