Announcing YugabyteDB 1.2 and Company Update
March 13, 2019
The team at YugaByte is excited to announce that YugabyteDB 1.2 is officially GA! You can download the latest version from our Quick Start page.
New in 1.2: YugaByte SQL Beta 3
YugaByte SQL (YSQL) is our PostgreSQL v11 compatible, distributed SQL API. It is ideal for powering microservices that require low latency, internet scale, geographic data distribution and extreme resilience to failures but want the data modeling flexibility of SQL (joins, indexes, multi-table transactions, views, and more).
At the core of YSQL lies DocDB, YugabyteDB’s massively scalable, transactional document store inspired by Google Spanner. Unlike other distributed SQL projects, YSQL does not re-implement the SQL dialect of PostgreSQL in a new programming language. Instead, we’ve reused PostgreSQL’s C code to ensure maximum compatibility, easy upgrades, and to avoid a costly programming language switch from say Go to C in the critical I/O path. This latest Beta 3 release marks the most important milestone to date in our SQL journey that started with Beta 1 in May 2018 followed by Beta 2 in September 2018.
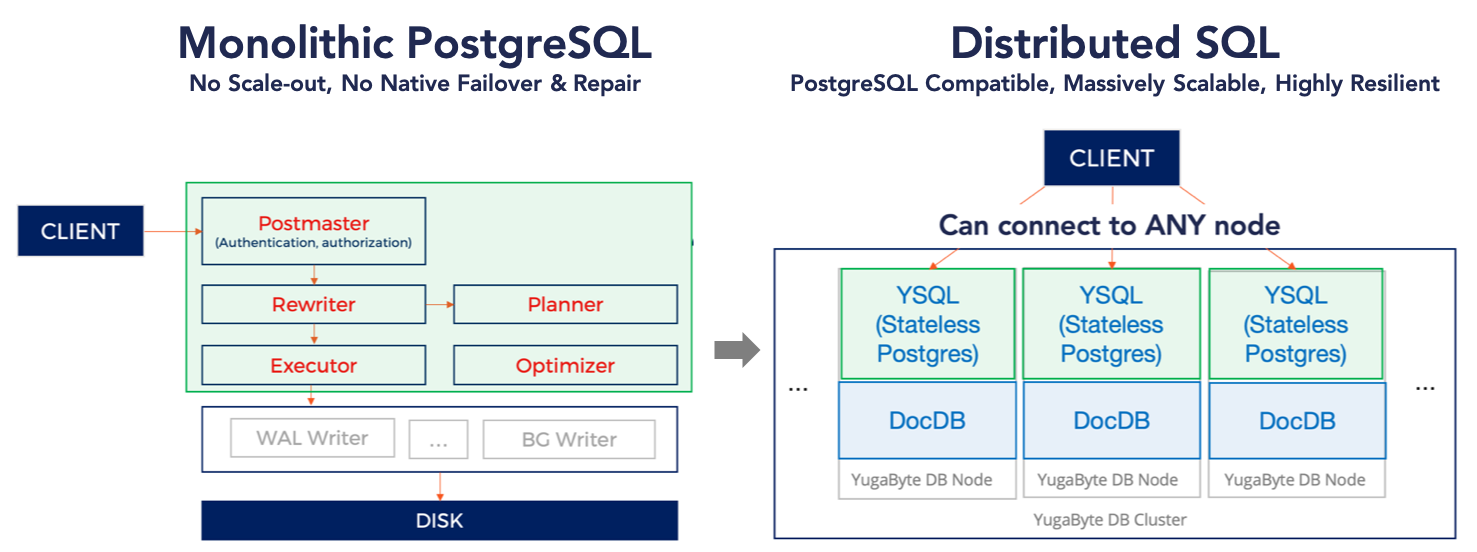
From Monolithic PostgreSQL to Distributed SQL
Here’s a select list of cluster-aware SQL features now available in YugabyteDB:
- DDL statements: CREATE, DROP and TRUNCATE tables
- Data types: All primitive types including numeric types (integers and floats), text data types, byte arrays, date-time types, UUID, SERIAL, as well as JSONB
- DML statements: Most statements such as INSERT, UPDATE, SELECT and DELETE. Bulk of core SQL functionality now supported includes JOINs, WHERE clauses, GROUP BY, ORDER BY, LIMIT, OFFSET and SEQUENCES
- Transactions: ABORT, ROLLBACK, BEGIN, END, and COMMIT
- Expressions: Built-in functions and operators
- Other Features: VIEWs, EXPLAIN, PREPARE-BIND-EXECUTE, and JDBC Support
For the complete list of supported features, check out the YSQL API docs.
As we drive towards YSQL GA in this Summer’s 2.0 release, look for some of the remaining SQL features to show up in the YugabyteDB GitHub repo in the coming weeks, including:
- Serializable Isolation
- Foreign Keys
- UDFs
- Certifications with popular ORM frameworks including Spring Boot, Sequelize, SQLAlchemy and more.
What about support for GIS (geospatial queries) and stored procedures? They are on the roadmap and look for them to be supported in one of the post 2.0 releases.
What about performance? We are in the middle of running comprehensive benchmarks for YSQL and YCQL, as well as, the latest versions of competing databases. There will be lots of exciting news to report on the performance and benchmarking front in the coming weeks, so please stay tuned!
New in 1.2: Jepsen Testing Passed
Last year we published our DIY Jepsen testing results – including the tests and failure modes implemented as well as the bugs found. We recently engaged Kyle Kingsbury, the creator of the Jepsen test suite, for an official analysis and are happy to report that YugabyteDB 1.2 formally passes Jepsen tests using the YCQL API.
YugabyteDB now passes tests for snapshot isolation, linearizable counters, sets, registers, and systems of registers, as long as clocks are well-synchronized.
Read more at YugabyteDB 1.2 Passes Jepsen Testing.
New in 1.2: Streamlined Kubernetes Experience
Many of our users run YugabyteDB natively in Kubernetes for business-critical use cases, including running a private Database-as-a-Service (DBaaS). These users have put YugabyteDB on Kubernetes though the ringer by verifying correctness and availability not only during various failure scenarios, but also while performing various Day 2 operations such as rolling upgrades, security patching of underlying nodes and backup/restores.
To make it easy to deploy and run YugabyteDB as a StatefulSet, we have released a comprehensive Helm Chart.
With this Helm Chart, you can now create a YugabyteDB cluster in Kubernetes using just a few simple steps. You can also customize various parameters such as the replication factor, the total resources allocated to a pod (CPU, memory, number of disks and the size of disks) and the number of pods, and more!
CockroachDB Benchmarks
In case you missed it, last month we published an in-depth YugabyteDB vs CockroachDB comparison that looked at performance benchmarks, plus architecture and design differences.
In a nutshell, YugabyteDB delivers an average of 3.5x higher throughput and 3x lower latency compared to CockroachDB. Here are some selected highlights from the large scale, transactional workloads we ran:
- 5x more insert throughput, 9x faster
- 4x more query throughput, 3x faster
- 4x more distributed transactions throughput
YugabyteDB offers additional features such as read replicas (for timeline-consistent, low-latency reads from the local region) and automatic data expiry (by setting a TTL at table level or row level) which you won’t find in CockroachDB.
You can download the in-depth comparison here or watch the webinar playback here.
New Customer Wins
We are excited to announce Plume and Ink Aviation as YugaByte’s newest customers!
Use Cases: Internet of Things, Smart Devices, AI
Plume’s intelligent, AI-driven platform enables a rich set of modern consumer services for the home that can run on third-party hardware platforms and be deployed at massive scale. Plume is the pioneer of Adaptive WiFi, the world’s first self-optimizing Wi-Fi delivering a reliable and consistent internet experience to every corner of the home through the invention of Wi-Fi Pods and SuperPods. The Plume Cloud enables the most advanced and resilient home Wi-Fi solution because of its ability to dynamically adapt and respond to changing network conditions. An open-source common software, OpenSync can be integrated into third-party hardware for connection to the Plume Cloud.

Use Case: Traveler Experiences
Ink Aviation provides smart, simple and effective systems for the aviation industry that improve the passenger experience while reducing operating costs. Products and services include mobile passenger handling, departure control systems, web and mobile check-in, plus bag drop kiosks
New Case Studies
Two new case studies are now available for download from the website.

Industry: Retail & E-Commerce
Use Case: Internet-Scale Microservices
Narvar helps retailers like Nordstrom, The Home Depot and Old Navy champion their customers at every step of their journey. Learn how YugabyteDB helped Narvar reduce costs, avoid AWS lock-in and maintain GDPR compliance.
Download the case study.

Industry: Logistics and Supply Chain
Use Case: Internet of Things
Turvo is a collaborative IoT platform changing the game in logistics whose team includes the founders of Uber Freight. Learn how YugabyteDB helped Turvo reduce costs, simplify operations and increase developer agility while achieving Internet scale with low latencies.
Download the case study.
Join Us at PostgresConf 2019!
For those you attending PostgresConf 2019 in NYC next week, make sure to stop by our booth to pick up some swag, catch a demo and chat with us about all things PostgreSQL and distributed SQL. Also, make sure to check out the YugabyteDB talks happening at this year’s conference:
March 20: “The What and the How of Making PostgreSQL GDPR Compliant”
and
March 21: “High Performance Multi-Region PostgreSQL Using a Distributed Data Storage Engine”
We are Hiring!
Current open positions in Sunnyvale, CA include:
- Developer Advocate
- Solutions Engineer
- Software Engineer – Core Database
- Software Engineer – Cloud Infrastructure
- Software Engineer – Full Stack
Our team consists of domain experts from leading software companies such as Facebook, Oracle, Nutanix, Google and LinkedIn. We have come a long way in a short time but we cannot rest on our past accomplishments. We need your ideas and skills to make us better at every function. Together, we will create the next great software company. All while having tons of fun and blazing new trails!
What’s Next?
- Get started with YugabyteDB on the cloud or container of your choice.
- Compare YugabyteDB to databases like Google Cloud Spanner, CockroachDB, MongoDB and DynamoDB.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


