Powering AI at Scale: Benchmarking 1 Billion Vectors in YugabyteDB
November 6, 2025
📞”Hello, thank you for calling El Guapa’s. I am your AI assistant. How can I help you?”
When your local taco shop starts using Artificial Intelligence, you know the technology of the future is already here.
Adoption of AI is rapid and widespread. From hyper-personalized recommendation engines to sophisticated Retrieval-Augmented Generation (RAG) models, the ability to provide users with contextual information is now a necessity. Large Language Models (LLMs) along with Vector Indexes are the key technologies powering this AI revolution.
We have successfully benchmarked YugabyteDB’s vector index performance with the Deep1B dataset, running a staggering one billion vectors. This milestone firmly establishes YugabyteDB as a leading distributed database for powering even the most demanding of AI applications.
In this blog, we explore why scalable vector indexes are essential, share the benchmark results, and highlight the advantages of unifying vector and relational data in a single store.
Supercharging LLMs with Vector Search
LLMs are general-purpose tools that are limited to the knowledge that they have been trained on. This is typically the data available on the public internet.
To allow LLMs to provide accurate responses for a specific application or product, we must supply them with domain-specific, real time data and context. In the case of the previously mentioned taco shop, this would be store hours, menu, prices, and daily specials. However, the amount of content you can pass on to LLMs is limited.
To understand what is a vector database and how it enables fast semantic search, read this comprehensive YugabyteDB guide.
This poses a problem for businesses that rely on massive volumes of data to operate. Imagine the backend system that powers not just one local taco shop, but thousands of restaurants across the globe.
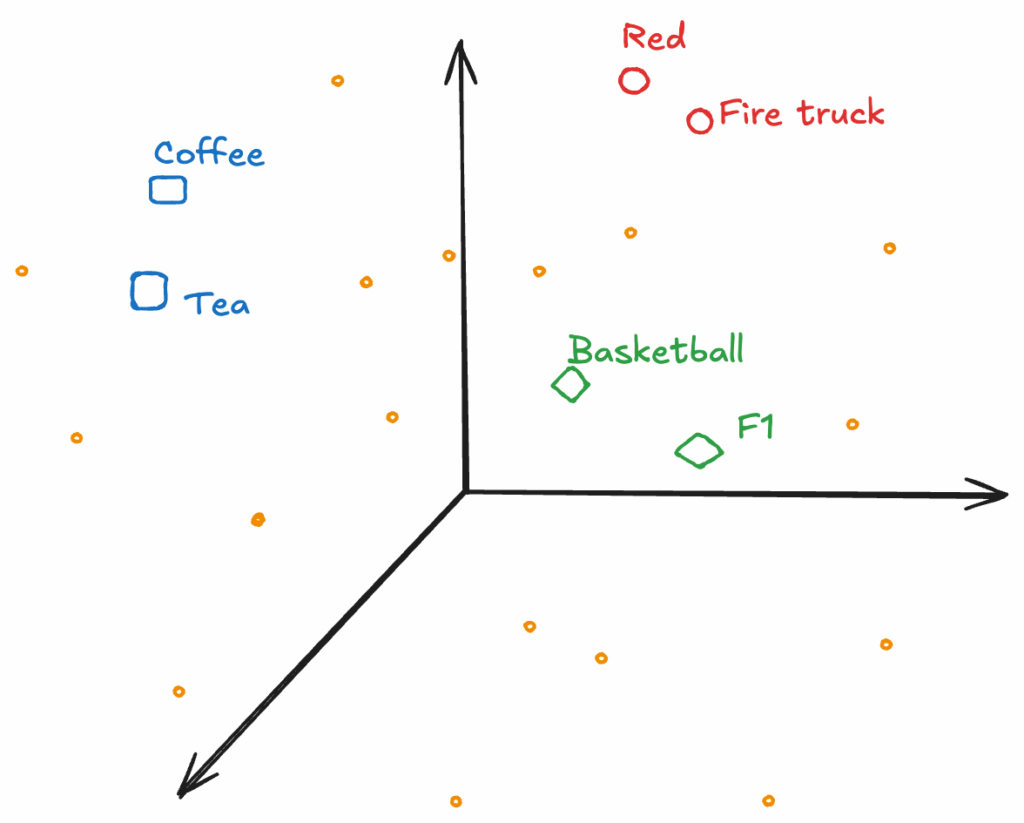
The solution for this problem lies in vector search, which allows you to find similar data points in high-dimensional spaces. Vector search is achieved by converting the text (or any form of data) into multi-dimensional embeddings.
Embeddings are coordinates that place related concepts close to each other. The vector index is built from these embeddings, which then allows you to retrieve related data based on an input prompt. The result is fed as context to the LLM along with the input prompt.
The challenge is not just performing timely vector searches, but doing so at a massive scale (billions of vectors and beyond) while maintaining low latency and high accuracy.
The Deep1B Benchmark
yugabyte=# SELECT COUNT(*) FROM public.pg_vector_collection; 1000000000
Deep1B is a large-scale benchmark dataset widely used to evaluate the performance and scalability of vector search and similarity algorithms. Containing one billion 96-dimensional embeddings derived from deep learning models trained on natural images, Deep1B serves as a gold standard for testing approximate nearest neighbor (ANN) search systems.
Its massive size makes it ideal for assessing how search frameworks handle real-world, production-level workloads involving billions of vectors. Researchers and engineers use Deep1B to measure key metrics, including recall, latency, and memory efficiency. This helps push the boundaries of high-performance vector databases and large-scale retrieval systems.
Understanding the HNSW Algorithm
The HNSW (Hierarchical Navigable Small World) algorithm is one of the most popular methods for ANN search. Three key parameters play a crucial role in balancing accuracy, speed, and memory usage: m, ef_construction, and ef_search:
- m: Determines the number of bi-directional connections each node (vector) maintains in the graph. A higher m increases accuracy by improving graph connectivity, but also raises memory consumption and index build time.
- ef_construction: Controls the size of the dynamic candidate list during the index-building phase. Larger values lead to a more thorough exploration of neighbors, resulting in higher-quality graphs and better recall, albeit at the cost of slower indexing.
- ef_search: Governs the size of the candidate list during the query phase. Increasing it improves recall (accuracy of search results) but also increases query latency.
Put simply, m and ef_construction determine how accurately the index is built or updated, while ef_search controls how accurately the system retrieves results when searching the index. Higher values provide more accurate results, but come with trade-offs. These include greater memory usage and increased latency.
It is important to tune the values based on the needs of your application. To get better results, you need more memory.
Enhancing the HNSW Algorithm with Distributed SQL
In a traditional single-node database, you’re limited by the memory available on that single machine. A distributed database introduces a fourth parameter, Node count, which allows you to dynamically expand the system’s memory footprint by scaling horizontally.
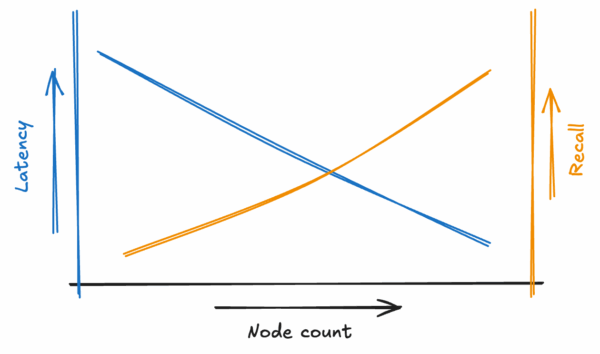
Using Deep1B, YugabyteDB achieved an impressive recall of 96.56% while still maintaining sub-second latency. This demonstrates both high accuracy and fast performance at massive scale.
| #vectors | 1,000,000,000 |
|---|---|
| #dimensions | 96 |
| m | 32 |
| ef_construction | 256 |
| ef_search | 256 |
| Recall | 96.56% |
| Latency | 0.319 seconds |
Architected for Scale
YugabyteDB leverages Usearch and a Vector LSM (Log-Structured Merge) abstraction to power high-dimensional approximate nearest-neighbor (ANN) search at scale.
Usearch provides a highly optimized vector search engine, while the Vector LSM organizes vectors in in-memory buffers and immutable on-disk chunks. This enables transactional, consistent access to the vector data for massive AI workloads that demand real-time data.
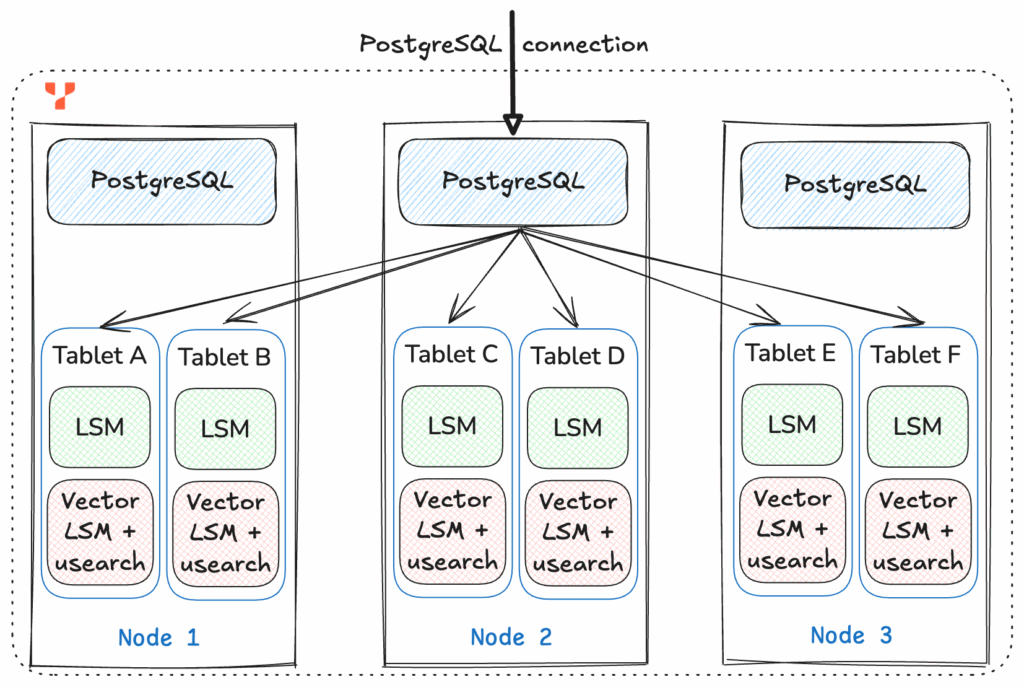
Automatic Sharding and Shard Redistribution To handle billions of vectors across a distributed cluster, YugabyteDB employs automatic sharding and shard re-distribution.
Each table is split into tablets, and vectors are co-located with their corresponding table rows to maximize data locality. Queries are executed in parallel across all tablets, with local top-K results aggregated globally. The system automatically rebalances shards as nodes are added or removed, ensuring consistent performance and scalability.
Instead of a single massive Usearch index, we have multiple smaller indexes that are automatically managed by the database. This combination produces search results with low latency and very high recall.
YugabyteDB offers a pluggable architecture that enables the easy integration of different vector indexing strategies. This modular design allows developers to choose or swap index implementations based on the workload, whether it involves high-accuracy recall, low-latency queries, or memory-optimized storage.
It also decouples the core database from the ANN algorithms, enabling YugabyteDB to quickly adopt new innovations in the field.
To learn more about the architecture of YugabyteDB’s Vector LSM, check out this recent blog.
A Unified Store Powered by Distributed PostgreSQL
yugabyte=# SELECT content FROM walkthroughs ORDER BY embedding <-> '[....]' LIMIT 3;
A founding principle of PostgreSQL is its extensibility, which allows developers to easily introduce new data types, indexes, and functions.
This design philosophy has proven particularly valuable for modern AI and vector search workloads. With the pg_vector extension, PostgreSQL can store high-dimensional vector embeddings in an HNSW index, enabling efficient nearest-neighbor search directly within the relational database.
What makes pg_vector especially powerful is its integration with familiar SQL syntax.
Users can define vector columns and run queries using the same commands they use for relational data, eliminating the learning curve associated with specialized vector databases. This enables existing PostgreSQL users to seamlessly integrate AI-driven functionality into their applications with minimal effort.
By combining extensibility with SQL familiarity, pg_vector enables PostgreSQL to maintain the simplicity and versatility that have made it a cornerstone of modern data management.
Combining the Best of PostgreSQL with YugabyteDB’s Distributed Innovation
Instead of managing a separate vector store alongside your main database, you can handle both transactional and vector workloads in a single platform.
When creating YugabyteDB, we made the architectural choice to reuse the powerful Query Engine of PostgreSQL rather than reimplement it from scratch. This enables us to provide a highly compatible PostgreSQL database that offers users the best of both worlds: full PostgreSQL functionality and distributed, scalable vector search capabilities.
Conclusion
Scaling to billions of vectors doesn’t require new systems or trade-offs, just YugabyteDB’s distributed PostgreSQL solution delivering simplicity, performance, and developer familiarity.
By combining a distributed architecture, Usearch, and the Vector LSM, we deliver low-latency, high-recall vector search, achieving an impressive 96.56% recall while seamlessly supporting transactional workloads. Automatic sharding, shard redistribution, and a pluggable indexing design ensure that AI applications can scale effortlessly without sacrificing reliability or flexibility.
With PostgreSQL compatibility and the pg_vector extension, developers can leverage familiar SQL to define vector columns, create indexes, and run nearest-neighbor queries, eliminating the learning curve of specialized vector stores. This unified approach simplifies operations, debugging, and observability, allowing teams to focus on building smarter applications rather than managing multiple systems.
By merging the power of PostgreSQL with a distributed, AI-ready vector search engine, YugabyteDB provides a robust platform for modern data-driven applications.
Whether it’s semantic search, recommendation engines, or retrieval-augmented generation, YugabyteDB combines scale, accuracy, and operational simplicity, making it the ideal choice for enterprises tackling the challenges of delivering massive vector workloads.


