Build Scalable Generative AI Applications with Azure OpenAI and YugabyteDB
October 27, 2023
This tutorial outlines the steps required to build a scalable, generative AI application using the Azure OpenAI Service and YugabyteDB.
Follow the guide to learn how to programmatically interface with the Azure OpenAI GPT and Embeddings models, store embeddings in YugabyteDB, and perform a similarity search across a distributed YugabyteDB cluster with the pgvector extension.
Explore Additional Updates to YugabyteDB with Release 2.19 >>>
The sample application we will use is a lodging recommendations service for travelers going to San Francisco. It supports two distinct modes:
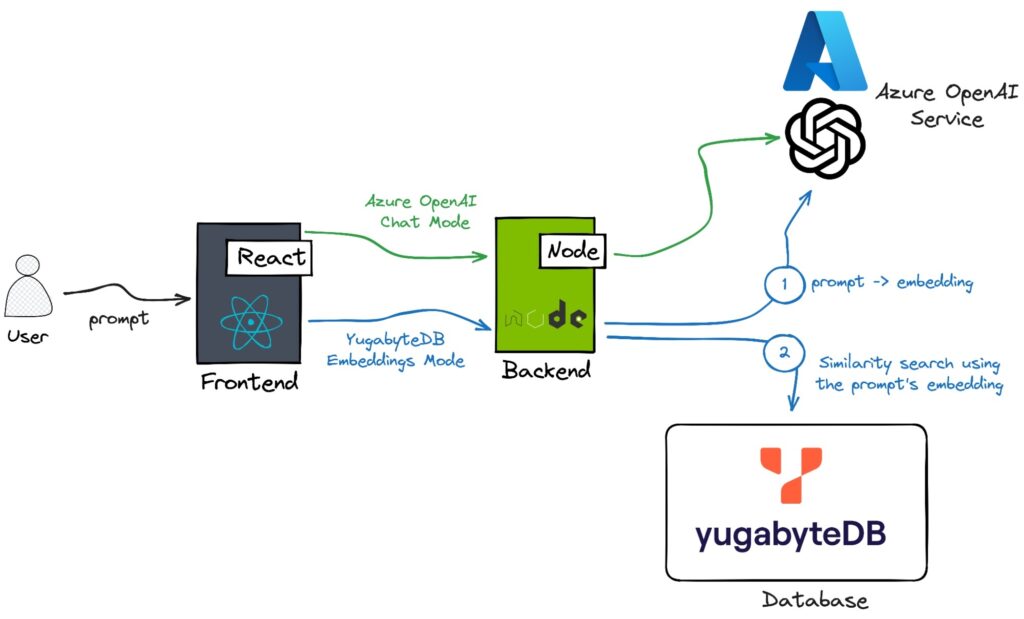
- Azure OpenAI Chat Mode: In this mode, the Node.js backend leverages one of the Azure OpenAI GPT models to generate lodging recommendations based on the user’s prompt.
- YugabyteDB Embeddings Mode: Initially, the backend employs an Azure OpenAI Embeddings model to convert the user’s prompt into an embedding (a vectorized representation of the text data). Next, the server does a similarity search in YugabyteDB to find Airbnb properties that match the user’s prompt. YugabyteDB takes advantage of the PostgreSQL pgvector extension for the similarity search within the database.
Prerequisites
- A Microsoft Azure subscription
- Access to the Azure OpenAI Service resource
- The latest js version
- The latest version of Docker
- A YugabyteDB cluster of version 2.19.2 or later
- psql or ysqlsh tool
Deploying Azure OpenAI Models
This application employs both the GPT and Embeddings models to showcase the distinct performance and traits of each for the app’s use case.
Follow the Microsoft’s OpenAI guide to:
- Create the Azure OpenAI resource under your subscription.
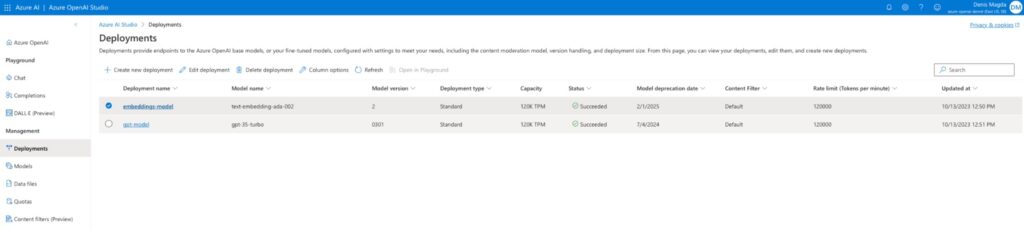
- Deploy a GPT model of gpt-35-turbo (or later). Name the deployment “gpt-model”.
- Deploy an Embedding model of text-embedding-ada-002 Name it “embeddings-model”.
Once the resources are provisioned, you’ll see them in your Azure OpenAI Studio:
Setting Up the Application
Download the application and provide settings specific to your Azure OpenAI Service deployment:
- Clone the repository:
git clone https://github.com/YugabyteDB-Samples/yugabytedb-azure-openai-lodging-service
- Initialize the project:
cd {project_dir}/backend npm init cd {project_dir}/frontend npm init - Open the {project_dir}/application.properties.ini file and provide the Azure OpenAI specific settings:
AZURE_OPENAI_KEY= # Your Azure OpenAI API key AZURE_OPENAI_ENDPOINT= # Your Azure OpenaAI endpoint for the Language APIs AZURE_GPT_MODEL_DEPLOYMENT_NAME = gpt-model AZURE_EMBEDDING_MODEL_DEPLOYMENT_NAME = embeddings-model
Setting Up YugabyteDB
YugabyteDB introduced support for the PostgreSQL pgvector extension in version 2.19.2. This extension makes it possible to use PostgreSQL and YugabyteDB as a vectorized database.
Start a 3-node YugabyteDB cluster in Docker (or feel free to use another deployment option):
mkdir ~/yb_docker_data
docker network create custom-network
docker run -d --name yugabytedb_node1 --net custom-network \
-p 15433:15433 -p 7001:7000 -p 9001:9000 -p 5433:5433 \
-v ~/yb_docker_data/node1:/home/yugabyte/yb_data --restart unless-stopped \
yugabytedb/yugabyte:2.19.2.0-b121 \
bin/yugabyted start \
--base_dir=/home/yugabyte/yb_data --daemon=false
docker run -d --name yugabytedb_node2 --net custom-network \
-p 15434:15433 -p 7002:7000 -p 9002:9000 -p 5434:5433 \
-v ~/yb_docker_data/node2:/home/yugabyte/yb_data --restart unless-stopped \
yugabytedb/yugabyte:2.19.2.0-b121 \
bin/yugabyted start --join=yugabytedb_node1 \
--base_dir=/home/yugabyte/yb_data --daemon=false
docker run -d --name yugabytedb_node3 --net custom-network \
-p 15435:15433 -p 7003:7000 -p 9003:9000 -p 5435:5433 \
-v ~/yb_docker_data/node3:/home/yugabyte/yb_data --restart unless-stopped \
yugabytedb/yugabyte:2.19.2.0-b121 \
bin/yugabyted start --join=yugabytedb_node1 \
--base_dir=/home/yugabyte/yb_data --daemon=falseNote: If you’re starting the cluster differently, update the following database connectivity settings in the {project_dir}/application.properties.ini file:
DATABASE_HOST=localhost DATABASE_PORT=5433 DATABASE_NAME=yugabyte DATABASE_USER=yugabyte DATABASE_PASSWORD=yugabyte
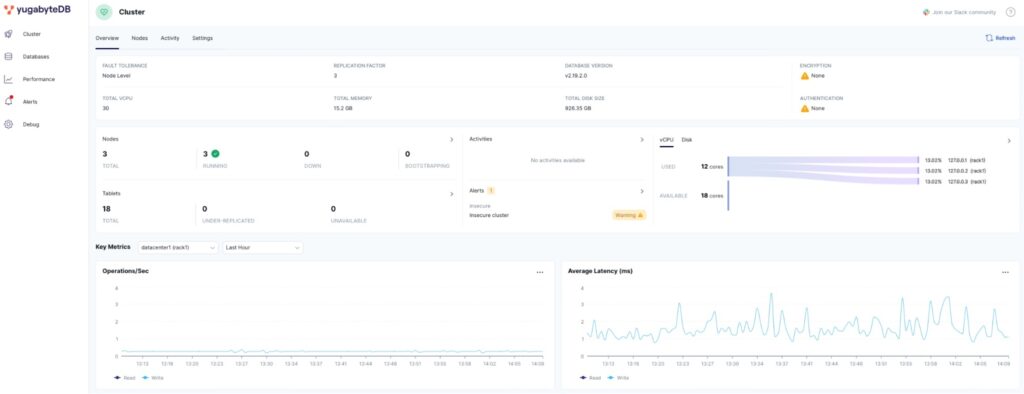
Open up the YugabyteDB UI to confirm that the database is up and running:
http://127.0.0.1:15433
Loading the Airbnb Data Set
As long as the application provides a lodging recommendation service for San Francisco, you can leverage a publicly available Airbnb data set with over 7500 relevant listings:
- Create the airbnb_listing table (feel free to use ysqlsh or another comparable SQL tool instead of psql):
psql -h 127.0.0.1 -p 5433 -U yugabyte -d yugabyte {project_dir}/sql/0_airbnb_listings.sql - Load the data set:
psql -h 127.0.0.1 -p 5433 -U yugabyte \copy airbnb_listing from '{project_dir}/sql/sf_airbnb_listings.csv' DELIMITER ',' CSV HEADER; - Execute the script below to enable the pgvector extension and add the description_embedding column of the vector type to the airbnb_listing table:
\i {project_dir}/sql/1_airbnb_embeddings.sql
Generating Embeddings For Airbnb Listings
Airbnb listings provide a detailed property description including number of rooms, types of amenities, a location, and other features. That information is stored in the description column and is a perfect fit for the similarity search against user prompts. However, to enable the similarity search, each description first needs to be transformed into its vectorized representation.
The application comes with the embeddings generator ({project_dir}backend/embeddings_generator.js) that creates embeddings for all Arbnb properties descriptions.
The generator reads the descriptions of the listings and uses the Azure OpenAI Embedding model to generate a description vector that is then stored in the description_embedding column of the database:
const embeddingResp = await azureOpenAi.getEmbeddings(embeddingModel, description); const res = await dbClient.query( "UPDATE airbnb_listing SET description_embedding = $1 WHERE id = $2", ['[' + embeddingResp.data[0].embedding + ']', id]);
Start the generator using the following command:
node {project_dir}/backend/embeddings_generator.jsNote, it can take 10+ minutes to generate embeddings for over 7500 Airbnb properties. You’ll see the message below once the process is completed:
Processing rows starting from 34746755 Processed 7551 rows Processing rows starting from 35291912 Finished generating embeddings for 7551 rows
Starting the Application
With the Azure OpenAI models deployed and Airbnb data with embeddings loaded in YugabyteDB, start to explore the application:
- Start the Node.JS backend:
cd {project_dir}/backend npm start - Start the React frontend:
cd {project_dir}/frontend npm start - Open the application UI (in case it’s not opened by default): http://localhost:3000/

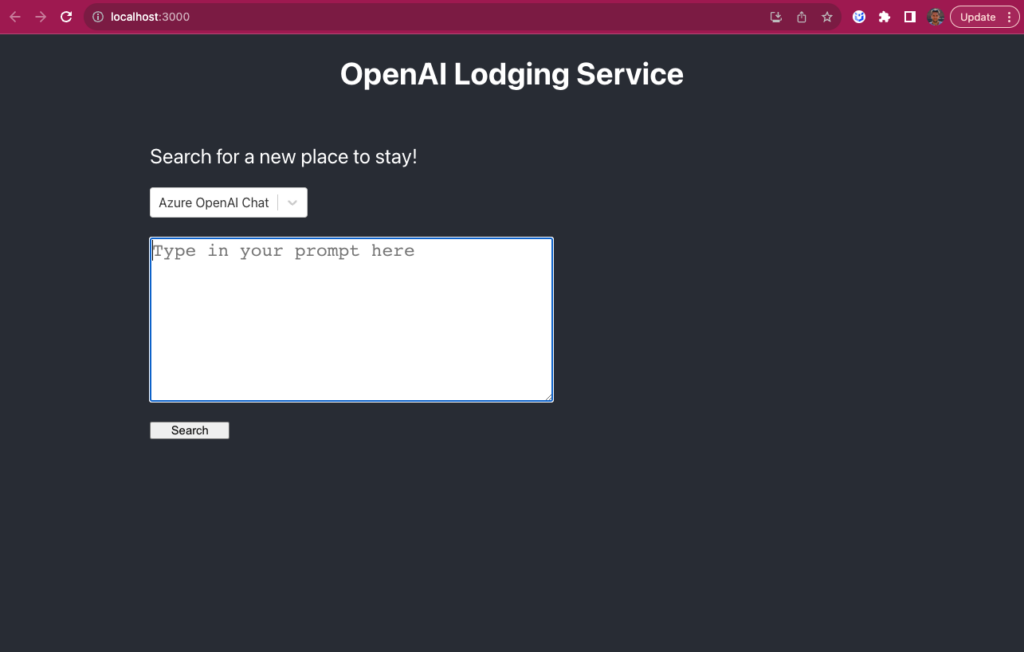
Exploring the Azure OpenAI Chat Mode
The Azure OpenAI Chat mode of the application relies on the Azure Chat Completions API. In this mode, the app’s behavior is similar to that of ChatGPT. You can interact with it in much the same way. Type in your prompt and it will be sent as-is to the neural network that returns the requested information.
For example, send the following prompt to the GPT model to get a few recommendations:
I’m looking for an apartment near the Golden Gate Bridge with a nice view of the Bay.

Internally, the application performs the following steps (see the {project_dir}/backend/openai_chat_services.js for details):
- It prepares system and user messages for the neural network; the system message clarifies what is expected from the GPT model:
const messages = [ { role: "system", content: "You're a helpful assistant that helps to find lodging in San Francisco. Suggest three options. Send back a JSON object in the format below." + "[{\"name\": \"<hotel name>\", \"description\": \"<hotel description>\", \"price\": <hotel price>}]" + "Don't add any other text to the response." }, { role: "user", content: prompt } ]; - The messages are sent to the Azure OpenAI Service:
const chatCompletion = await this.#azureOpenAi.getChatCompletions(this.#gptModel, messages);
- The application extracts the JSON data with recommendations from the response and returns those recommendations to the React frontend:
const message = chatCompletion.choices[0].message.content; const jsonStart = message.indexOf('['); const jsonEnd = message.indexOf(']'); const places = JSON.parse(message.substring(jsonStart, jsonEnd + 1)); return places;
Depending on the selected model type, your subscription, and the neural network’s workload, it can take between 5 and 20 seconds for the Chat Completions API to generate the recommendations.
To make the solution scalable, with the latency for recommendations retrieval coming in at under a second, we need to switch to the app’s YugabyteDB Embeddings mode.
Scaling with the YugabyteDB Embeddings Mode
If you select the YugabyteDB Embeddings mode from the application UI and send the same prompt, you’ll get a different list of suggestions, but at less than one second of latency:
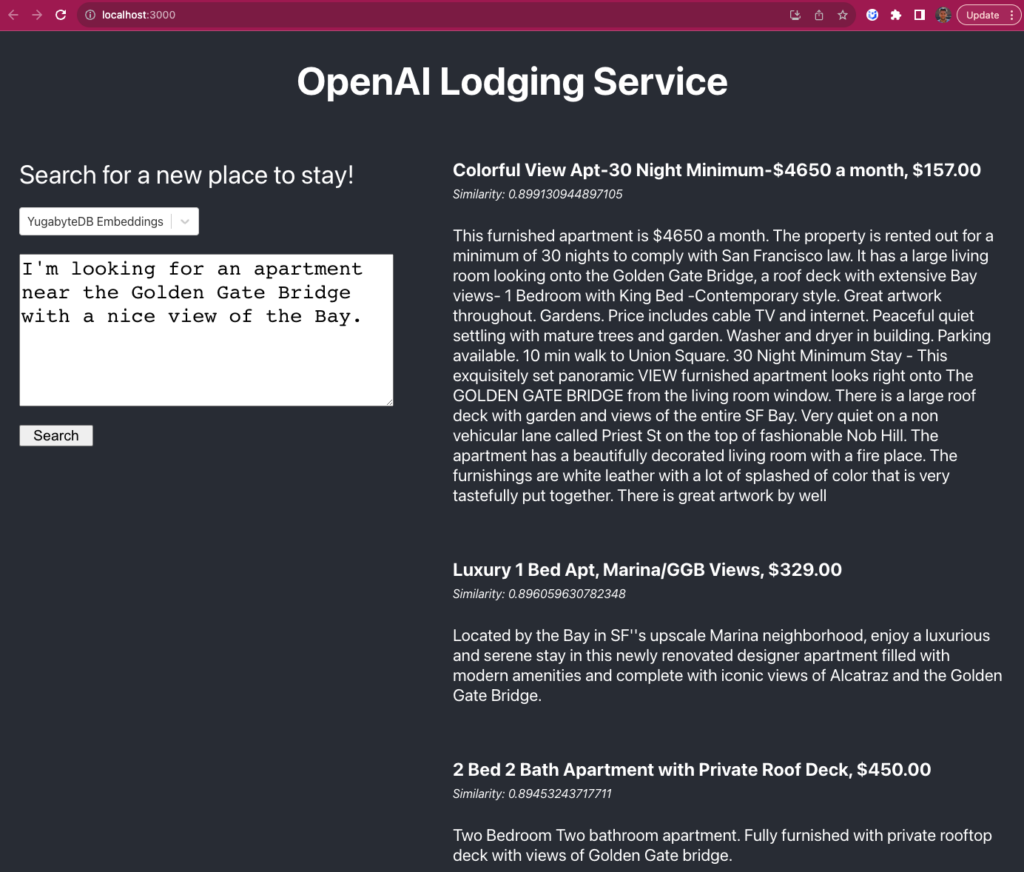
This mode performs better because the similarity search is done via our own data set stored in the distributed YugabyteDB Cluster.
The application performs the following steps to generate the recommendations (see the {project_dir}/backend/yugabytedb_embeddings_service.js for details):
- The application generates a vectorized representation of the user prompt using the Azure OpenAI Embeddings model:
const embeddingResp = await this.#azureOpenAi.getEmbeddings(this.#embeddingModel, prompt);
- The app uses the generated vector to retrieve the most relevant Airbnb properties stored in YugabyteDB:
const res = await this.#dbClient.query( "SELECT name, description, price, 1 - (description_embedding <=> $1) as similarity " + "FROM airbnb_listing WHERE 1 - (description_embedding <=> $1) > $2 ORDER BY similarity DESC LIMIT $3", ['[' + embeddingResp.data[0].embedding + ']', matchThreshold, matchCnt]);The similarity is calculated as a cosine distance between the embeddings stored in the description_embedding column and the user prompt’s vector.
- The suggested Airbnb properties are returned in the JSON format to the React frontend:
for (let i = 0; i < res.rows.length; i++) { const row = res.rows[i]; places.push({ "name": row.name, "description": row.description, "price": row.price, "similarity": row.similarity }); } return places;
In Conclusion…
The Azure OpenAI Service simplifies designing, building, and productizing generative AI applications by offering developer APIs for various major programming languages.
YugabyteDB enhances the scalability of these applications by distributing data and embeddings across a cluster of nodes, facilitating similarity searches on a large scale.


