The Effect of Isolation Levels on Distributed SQL Performance Benchmarking
September 24, 2019
This post addresses a concern raised about a benchmarking result we recently published comparing the performance of YugabyteDB, Amazon Aurora and CockroachDB. It was pointed out that we unfairly used the default isolation level for each database rather than use serializable isolation level in all databases (even though serializable level was not required for these workloads). In addition, we are also happy to share additional results with the workloads run at YugabyteDB’s serializable isolation level. Let’s dive right into the details!
Benchmarking is Driven By Target Workloads
The general perception is that benchmarks published by vendors can never be trusted. However, well-run benchmarks absolutely have their place, even if performed by a vendor. Benchmarks are well-run when the input parameters to the benchmarked systems match the needs of the target workloads included in the benchmark. The target workloads for the benchmark in question are simple inserts and secondary indexes served with high performance, massive scale and ACID guarantees.
- Simple Inserts: A workload that inserts millions of rows, each with a key column and a value column. The queries in this use case can efficiently retrieve the value given the key.
- Secondary Index Inserts: A workload that inserts millions of rows into a table with the same schema as above – a key column and a value column, but with an index on the value column. The queries in this use case can efficiently lookup by either the key or the value.
The “I” in ACID stands for the isolation level, which essentially determines the safety guarantees necessary for the workload. As long as the ACID requirement is met, choosing a stronger than necessary isolation level could adversely affect performance.
Always Choose Serializable Isolation Level?
Serializable isolation is a must-have in databases for supporting workloads where the read set of a transaction does not fully overlap with the write set, as shown in this example. However, not all workloads require such strict guarantees, especially if the tradeoff of such guarantees results in poorer performance. Opting for a weaker isolation levels in workloads that do not require serializable isolation to achieve a higher performance may be a sensible tradeoff.
Let us work from the perspective of a user looking to address these target workloads using four ACID-compliant SQL databases, namely Oracle, YugabyteDB, Amazon Aurora and CockroachDB. These databases are viable, real-world candidates for the simple inserts and secondary index workloads since they support the necessary features including ACID guarantees. Note that the weakest/default isolation level at which some of the above databases guarantee ACID for these workloads is READ COMMITTED. As explained previously, going for isolation level stricter than READ COMMITTED simply because a database supports it, may bring performance penalties (depending on a database’s design/implementation) .
The following table summarizes support for various isolation levels in the four databases. Analysis of the semantic differences between these isolation levels and how they are usually implemented by databases can be found in standard database literature and hence is not provided as part of this post.
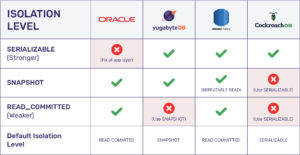
From the above table, the following would be the isolation level choices for a user running the benchmark with the aim of maximizing performance:
- CockroachDB: the benchmark uses SERIALIZABLE isolation level because that is the lowest level that guarantees consistency for these workloads in this database. Note that SERIALIZABLE is the only supported isolation level.
- YugabyteDB: the benchmark only requires SNAPSHOT isolation level because that is the lowest level at which it can guarantee consistency for these workloads. A user setting YugabyteDB to SERIALIZABLE for these use cases may be unnecessarily giving up the performance. But for the sake of completeness we have provided performance numbers for these benchmarks under both the SNAPSHOT & SERIALIZABLE isolation levels in YugabyteDB.
- Amazon Aurora and Oracle: can safely support these at READ COMMITTED isolation level.
The obvious next question is why do database vendors undertake extra engineering effort to support features like secondary indexes at isolation levels weaker than SERIALIZABLE or SNAPSHOT? This is because for a predominant majority of workloads (and even most workloads involving multi-row or multi-table transactions), it is possible to achieve higher performance at lower isolation levels without compromising correctness. Databases consider such effort as feature development and market it accordingly. It is natural to expect that users would want the best performance (as long as ACID guarantees are met for the set of operations their workload does), rather than opt for the strongest isolation level irrespective of the workload and compromise on the performance.
Is YugabyteDB Fast under Serializable Isolation?
It was pointed out that YugabyteDB was run at a lower isolation level (Snapshot) than that of CockroachDB (which only supports Serializable). The recommendation was to run YugabyteDB also at Serializable isolation. Switching the workload to Serializable isolation level is easy in YugabyteDB. Simply change the connection session property in JDBC:
connection.setTransactionIsolation(Connection.TRANSACTION_SERIALIZABLE);
The results of re-running the benchmarks under serializable isolation level are shown below.
Simple Inserts
The bar charts below summarize the results.
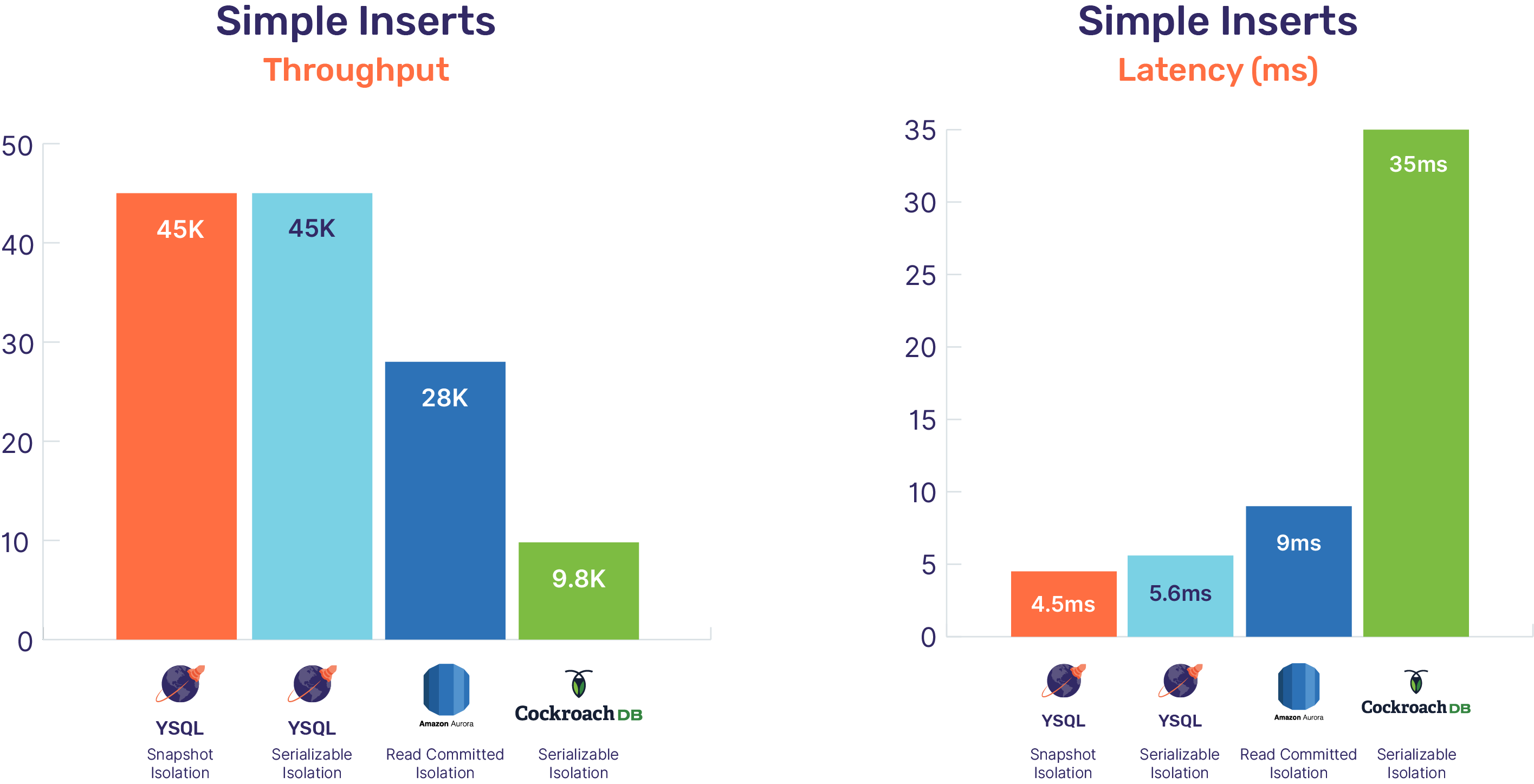
There was no significant difference between the performance of YugabyteDB at Serializable and Snapshot isolation levels – both isolation levels give a throughput of 45K writes/sec with about 4.5ms to 6ms latency.
Secondary Index Insert
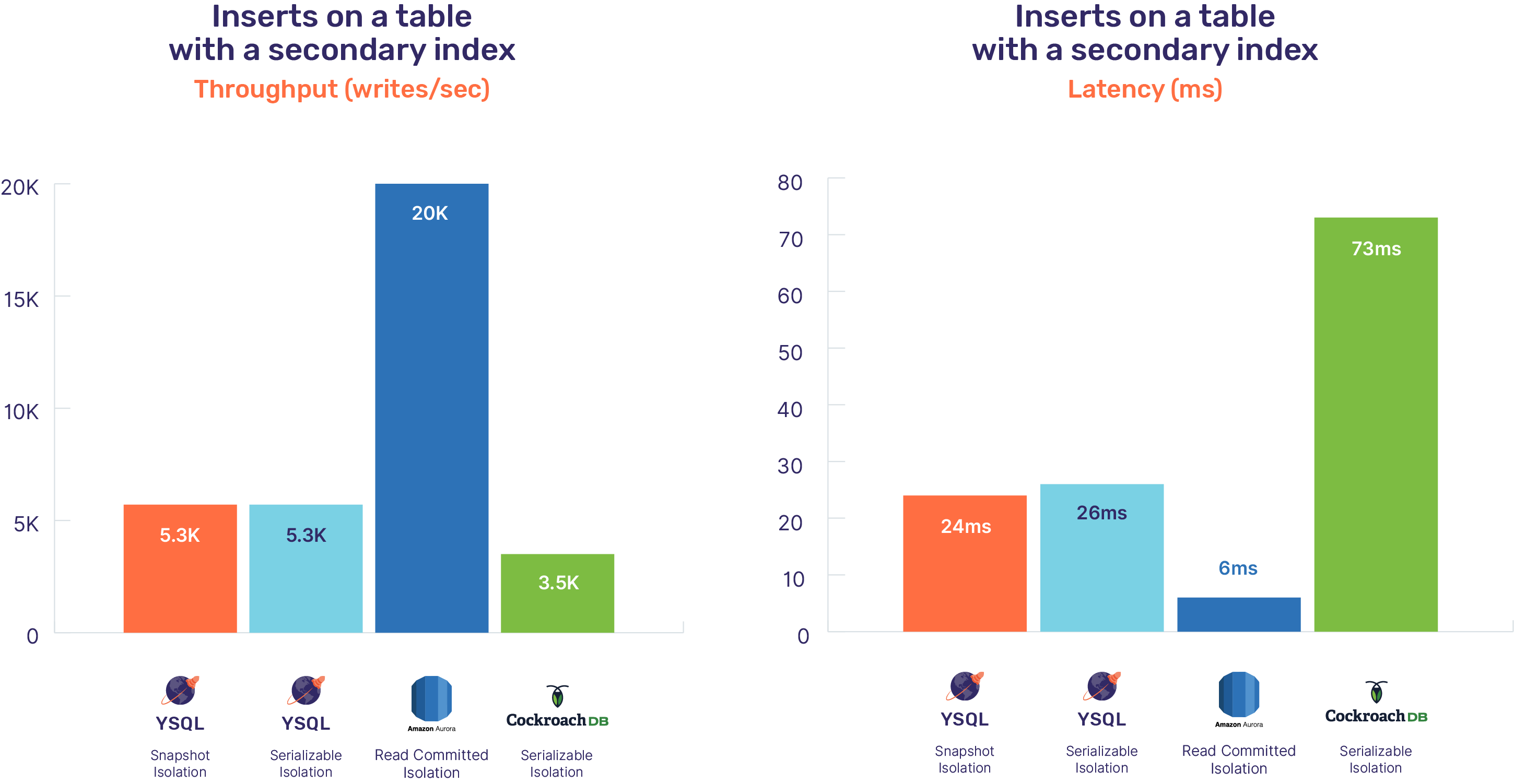
Once again, the performance numbers are comparable between the two isolation levels for YugabyteDB – 5.3K writes/sec with latencies around 25ms. Amazon Aurora comes out as the best performing database for this workload. This is because unlike the other two databases that are horizontally write scalable, writes are processed at only node in Amazon Aurora without the need to use any network RPCs. In other words, a user desiring the high performance of Aurora has to give up on horizontal write scalability.
Why Does Serializable Perform As Well As Snapshot in YugabyteDB?
The results of the previous sections show that, for the workloads benchmarked, the performance of YugabyteDB is similar at both Serializable and Snapshot isolation levels. This is because of the underlying implementation in YugabyteDB. The operations in these workloads (simple inserts and secondary index inserts) can be thought of as reading a set of rows (aka the read set), and subsequently updating the same set of rows (aka the write set). For simple inserts, every row being inserted is a part of the read set (an SQL insert operation needs to ascertain that the row does not already exist) and trivially a part of the write set as well. Similarly, in the case of a secondary index insert, all the rows in the read set are present in the write set as well.
For a workload that can have its transaction read set different from its write set, Serializable isolation level (where the DB detects a read-write conflict) versus Snapshot isolation (where the DB detects only write-write conflicts) will indeed produce different performance numbers.
Conclusion
Picking Snapshot as the Default
While serializable isolation is essential for some workloads, we believe it is not necessary for every workload. It is possible to achieve higher performance with Snapshot, and with high-performance as a core focus of YugabyteDB, we believe that picking Snapshot isolation as the default to maximize performance is the right approach for our users. A deep dive into the type of workloads that mandate serializable isolation at the cost of lower performance is a topic of a separate blog post coming soon. Benchmarking the databases for such workloads is a natural follow-up exercise.
High-performance with Both Serializable and Snapshot
YugabyteDB delivers high performance for simple inserts and secondary index inserts workloads under both Snapshot and Serializable isolation levels.


