YugabyteDB vs CockroachDB vs. Amazon Aurora: Comparing PostgreSQL-Compatible Database Performance
September 17, 2019
One of the flagship features of the Yugabyte distributed SQL database is the PostgreSQL-compatible YugabyteDB SQL (YSQL) API. In this blog post, we will look at the performance and scalability of YSQL and compare it to two other PostgreSQL-compatible databases—Amazon Aurora PostgreSQL and CockroachDB.
SQL benchmarks demonstrated that YSQL is 10x more scalable than the maximum throughput possible with Amazon Aurora. Additionally, for a similar hardware profile, YSQL delivered nearly 2x the throughput of Amazon Aurora at half the latency.
Distributed SQL combines the SQL language and transactional capabilities of an RDBMS with the cloud-native capabilities such as high availability, scalability, fault tolerance and geo-distribution that are typical to NoSQL databases.
Benchmark Setup
The table below summarizes the design points of these three databases.
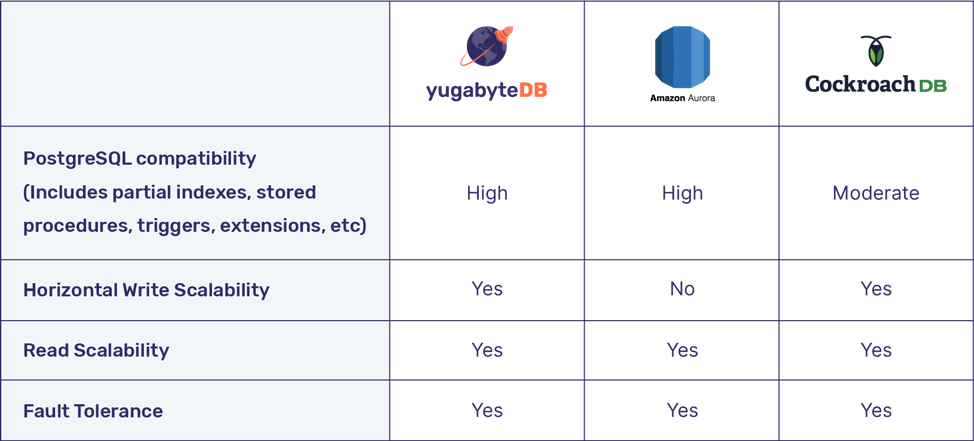
Note: We are not considering a multi-master setup in Aurora PostgreSQL because it compromises data consistency.
So now let’s look at the following performance and scalability aspects of these databases:
- Write performance
- Scaling writes
- Scaling reads
- Scaling connections
- Distributed transactions
All the benchmarks below were performed in the Oregon region of AWS cloud, using a benchmark application located on Github. YugabyteDB 2.0 was set up on a three node cluster of type i3.4xlarge (16 vCPUs on each node) in a multi-az deployment. This deployment is shown as a UI screenshot below.

CockroachDB (version 19.1.4) had an identical setup. Aurora PostgreSQL was set up on 2 nodes of type db.r5.4xlarge (16 vCPUs on each node). One node was the master, the other node a standby for fast failover in a different AZ. This setup is shown below.

Note: CockroachDB only supports Serializable isolation, while YugabyteDB and Amazon Aurora support both Serializable and Snapshot isolation. Amazon Aurora even supports the lower isolation level of Read Committed which is also its default. The benchmarks in this post use the default settings in all DBs – which is sufficient for the correctness of these workloads (simple inserts and secondary indexes). The SQLInserts and SQLSecondaryIndex workloads of this benchmark client (see Github page) were used for these results.
Write Performance
The benchmark was to insert 50M unique key-values into the database using prepare-bind INSERT statements with 256 writer threads running in parallel. There were no reads against the database during this period. The benchmark results are shown below.
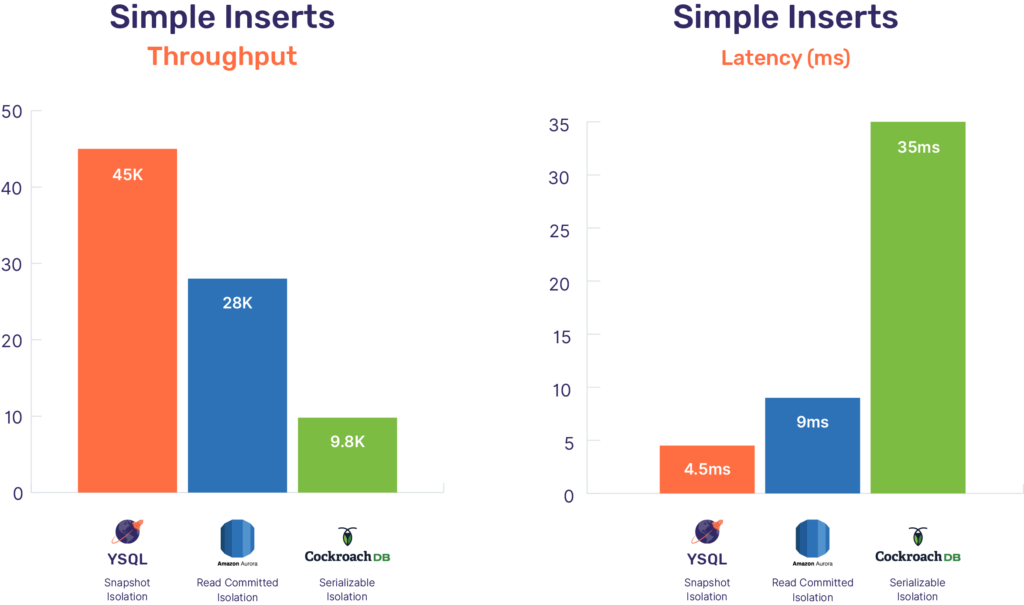
While the results are already impressive, we are just getting started with the performance of YSQL. YugabyteDB’s core storage engine, DocDB, which powers both YSQL and YCQL, is capable of much higher throughput. The semi-relational YCQL API, which runs on top of DocDB similar to YSQL, is more mature and hence performs better, as shown below.
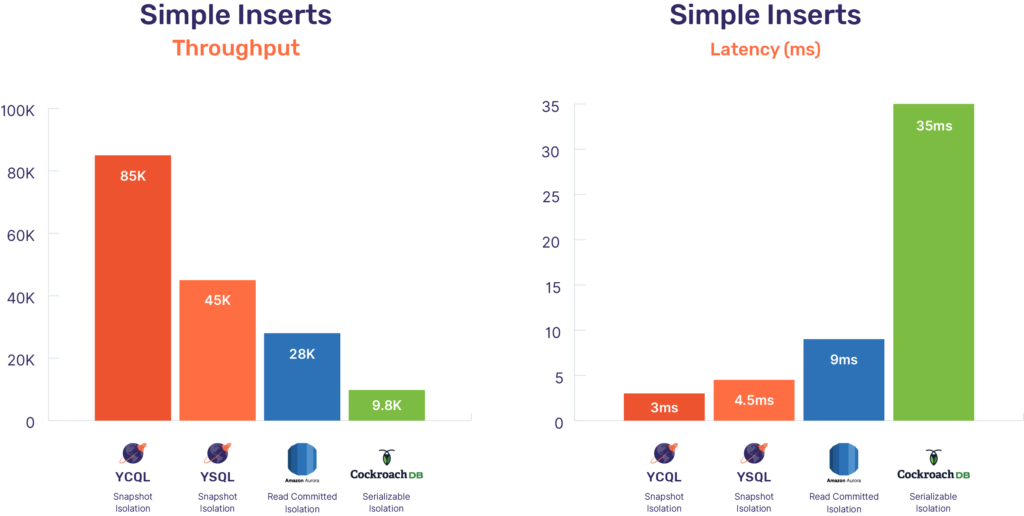
There are additional improvements that we are working on in the YSQL query layer to achieve even better performance (to match that of YCQL).
Scaling Writes
What happens when we need to scale? We had noted in the table above that AWS Aurora cannot horizontally scale writes. The only way to scale writes in Aurora is vertical scaling, meaning the node has to be made beefier. The maximum write IOPS Aurora can scale to is limited by the largest available node in terms of vCPUs.
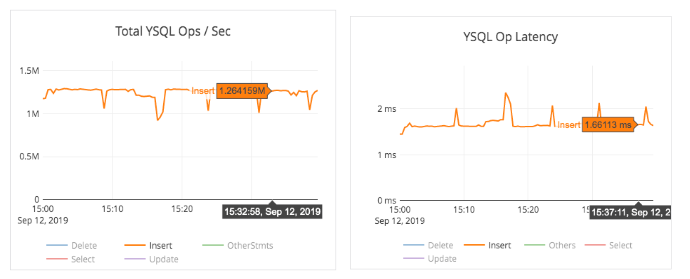
Beyond 1 Million Writes/Sec in YugabyteDB
Since YugabyteDB is both high-performance and horizontally scalable, an experiment to scale it to a million write ops/sec was in order. The setup was a 100 node YugabyteDB cluster with c5.4xlarge instances (16 vCPUs and 1TB of storage per node) in a single zone. This cluster, named MillionOps, is shown below.
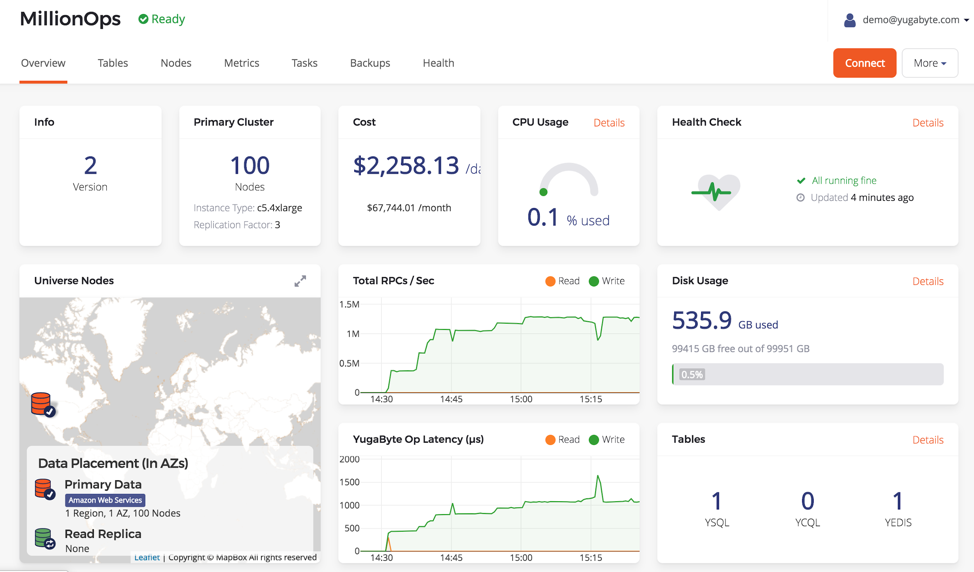
This cluster was able to perform 1.26 million writes/sec at 1.7ms latency!
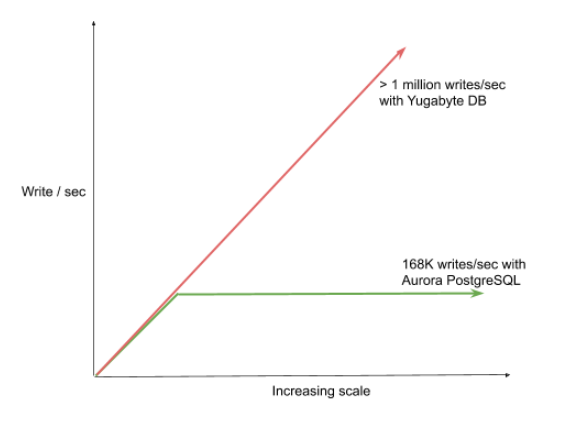
168K Writes/Sec Ceiling for Aurora PostgreSQL
The above benchmark numbers (28K writes/sec) was observed on a 16 vCPU (db.r5.4xlarge) machine. The largest instance available for Aurora has 96 vCPUs (db.r5.24xlarge), which has 6x more resources than the one used for the benchmark shown above with 16 vCPUs (db.r5.4xlarge). Assuming that the writes scale with the machine size, the maximum write throughput of an Aurora database with multiple tables is capped at 168K ops/sec. Even though Amazon Aurora can store up to 64TB of data, this throughput bottleneck will pose a practical challenge in exploiting the available storage. After this write throughput ceiling, the only choice is to manually shard the data at the application layer, which is a complex undertaking.
By contrast, a YugabyteDB cluster scales linearly with the number of nodes. A 12 node cluster of YugabyteDB would be able to exceed the above write throughput of 168K ops/sec. A graph comparing the write scalability of these two databases is shown below.
Scaling Reads
Both these databases can scale reads, however:
- Read scaling in Aurora compromises consistency by serving stale reads.
- Application design could get more complex if they have to query read replicas in Aurora.
Let us look at how read scalability is achieved in these databases. The Aurora PostgreSQL documentation states the following in terms of scaling the database.
Scaling Aurora PostgreSQL DB Instances
is You can scale Aurora PostgreSQL DB instances in two ways, instance scaling and read scaling. For more information about read scaling, see …
We have already looked at the write throughput ceiling as a result of instance scaling. Let us examine read scaling in Aurora. Reads and writes have separate endpoints in Aurora. In order to scale reads, it is the responsibility of the application to explicitly read from the multiple read endpoints.

Firstly, this means that applications are required to explicitly include which endpoint to connect to in their design. This decreases the velocity of developing applications because which the endpoint to connect to becomes a part of the application architecture and may not be a trivial exercise, especially when considering failover scenarios.
Secondly, and more importantly, the bigger issue is that reading from a replica returns stale data – which could compromise consistency. In order to read the source of truth, the application has to read from the master node (which also handles all the writes). Because a single node needs to serve consistent reads, this architecture would limit the read throughput to whatever can be served by the largest node (similar to the analysis we did with writes).
By contrast, YugabyteDB treats all nodes exactly same. This improves things in the following ways:
- The application simply needs to connect to a random node in the cluster, and the rest is handled by the database. All the database nodes can be put behind just one load-balancer.
- When performing reads, all nodes of the cluster are able to participate and hence the read throughput is much higher.
Eliminating the Load Balancer with Cluster-Aware JDBC Drivers
To simplify things even further, we’re working on a cluster-aware version of the standard JDBC driver, called YugabyteDB JDBC. These drivers can connect to any one node of the cluster and “discover” all the other nodes from the cluster membership that is automatically maintained by YugabyteDB.
Events such as node additions, removals, and failures are asynchronously pushed to these client drivers, resulting in the applications staying up-to-date when it comes to the cluster membership. With cluster-aware JDBC drivers, you no longer need to update the list of nodes behind the load-balancer manually or manage the lifecycle of the load-balancer, making the infrastructure much simpler and agile.
Scaling Connections
Scaling the number of connections is a common concern with PostgreSQL. There is a limit to the number of connections to an Aurora PostgreSQL database. The table below (taken from recent AWS documentation) summarizes the recommended number of connections to the database based on the instance sizes.
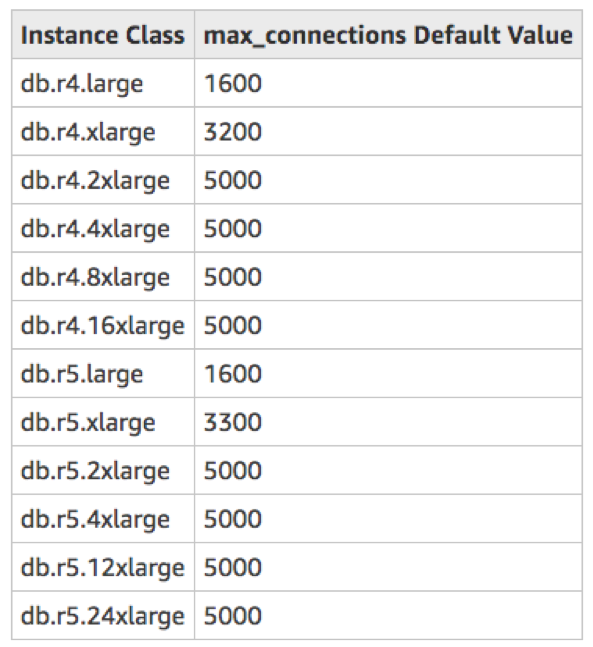
The table shows that the maximum number of connections recommended, even in the case of the largest Aurora PostgreSQL database, is 5000 (though the theoretical maximum mentioned in the docs is 262,142). In cloud-native applications, which have many microservices and massive scale, this quickly becomes a limitation.
With YugabyteDB, the number of connections is specified per node in the cluster. The default number of connections per node (also configurable) is 300. In our example setup of 3 nodes we would get a maximum of 900 connections. But scaling for connections is easy. By choosing 6 instances with 8 vCPUs (instead of 3 instances with 16 vCPUs), we have effectively doubled the number of connections to 1.8K while keeping the resources the same! Similarly, by choosing 24 instances with 8 vCPUs (this is a rough equivalent of the largest Aurora cluster with 96 vCPUs), the deployment can scale to over 10K connections.
Distributed Transactions – Latency vs Scalability
YugabyteDB is a horizontal write scalable database. This means that all nodes of the cluster are simultaneously active (as opposed to just one master, as is the case with Aurora). To achieve horizontal write scalability, the data is seamlessly split up into small chunks, called tablets, which are then distributed across all the nodes of the cluster.
When YugabyteDB needs to perform a distributed transaction, it needs to perform writes across the different tablets, which end up being RPC calls to remote nodes. The upshot of this is that the database might have to perform RPC calls over the network in order to handle an end user’s transaction. This can affect both the latency and throughput as seen by the end user. With Amazon Aurora, the entire transaction is handled on the master node with no remote RPC calls.
This becomes an architectural tradeoff that is fundamental to the two designs. Therefore, think carefully before picking one versus the other. But what do the raw performance numbers look like? In order to determine that, we performed a benchmark to insert 5M unique key values into a database table with a secondary index enabled on the value column. There were no reads against the database during this period.
Analysis of Tradeoffs Using a Benchmark
Below are the results of this secondary index benchmark across these PostgreSQL-compatible databases. These benchmarks write 5 million transactions (each of which write two keys as a transaction) with 128 writer threads. These benchmarks were performed with the standard setup outlined above.
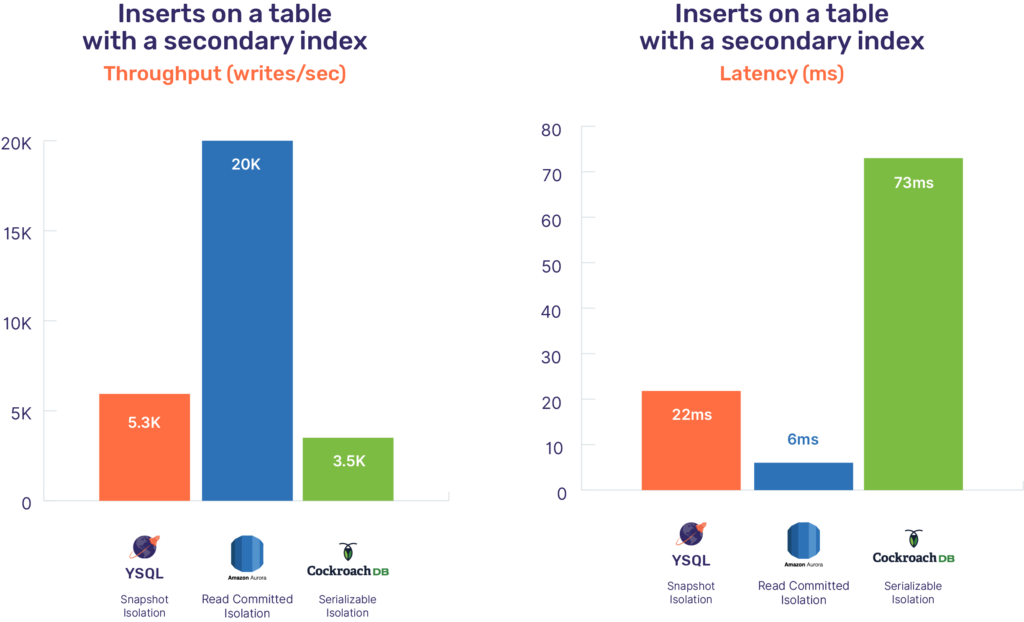
YugabyteDB needs 3-4 remote RPC calls before it can perform a distributed transaction involving multiple shards of the main table and the index (which is also modeled as a table). This results in a correspondingly higher latency and lower throughput. The write latency of a transaction in the above benchmark in YugabyteDB is 22ms, while that of Aurora PostgreSQL is only 6ms. Additionally, the write throughput of a 3 node (16 vCPU) YSQL cluster is only 5.3K, while that of Aurora PostgreSQL is 20K.
Let us look at what happens when the time comes to scale the writes of the above workload. We have already discussed in a previous section that Aurora PostgreSQL can only scale to a maximum of 96 cores, or the write ceiling of the Aurora PostgreSQL database is capped at 120K transactions/second across all the transactions performed by the app and indexes on the various tables in the database. With YugabyteDB, a 63 node cluster would deliver 120K transactions/sec, a 106 node cluster would deliver over 200K transactions/sec.
This means that Aurora PostgreSQL is a great choice if your database instance would never need to handle more than 120K transactions/sec. If future proofing for increasing scale is important, then YugabyteDB is a better choice.
Note: The analysis in this section only applies to write transactions. Reads are not affected.
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.
Update: A new post “The Effect of Isolation Levels on Distributed SQL Performance Benchmarking” includes performance results from running these workloads at serializable isolation level in YugabyteDB.


