Scaling Sequences with Server-Level Caching in YugabyteDB
September 19, 2023
Generating unique, sequential numbers is hard when multiple applications are trying to generate them at the same time. While UUIDs offer a solution, they are random and large, coming in at 128 bits. ULIDs reduce randomness by ordering UUIDs using the current time as a factor, but issues arise with extended delays. This is where database sequences come in handy.
Sequences in databases automatically generate incrementing numbers, perfect for generating unique values like order numbers, user IDs, check numbers, etc. They prevent multiple application instances from concurrently generating duplicate values. The database maintains the last number generated and then sequentially increments it upon request. This works well for single-node databases like PostgreSQL or MySQL, where all apps communicate with one db node holding the sequence.
But in a distributed, scalable database like YugabyteDB, applications can talk to any node in the cluster, potentially increasing latencies when recording or fetching h the next value in a sequence. This is because the different nodes need to be consistent with regard to which numbers have been handed out. This blog explores YugabyteDB’s optimizations in this regard and offers tips to scale sequences in your distributed applications.
Scaling Sequences: The Basics
To start, create a simple sequence named s1 using the CREATE SEQUENCE statement.
CREATE SEQUENCE s1;
Now fetch some values from the sequence.
yugabyte@yugabyte=# select nextval('s1');
nextval
---------
1
(1 row)
yugabyte@yugabyte=# select nextval('s1');
nextval
---------
2
(1 row)
yugabyte@yugabyte=# select nextval('s1');
nextval
---------
3
(1 row)The returned numbers are sequential, which is expected since the sequence starts at 1 and increments by 1.
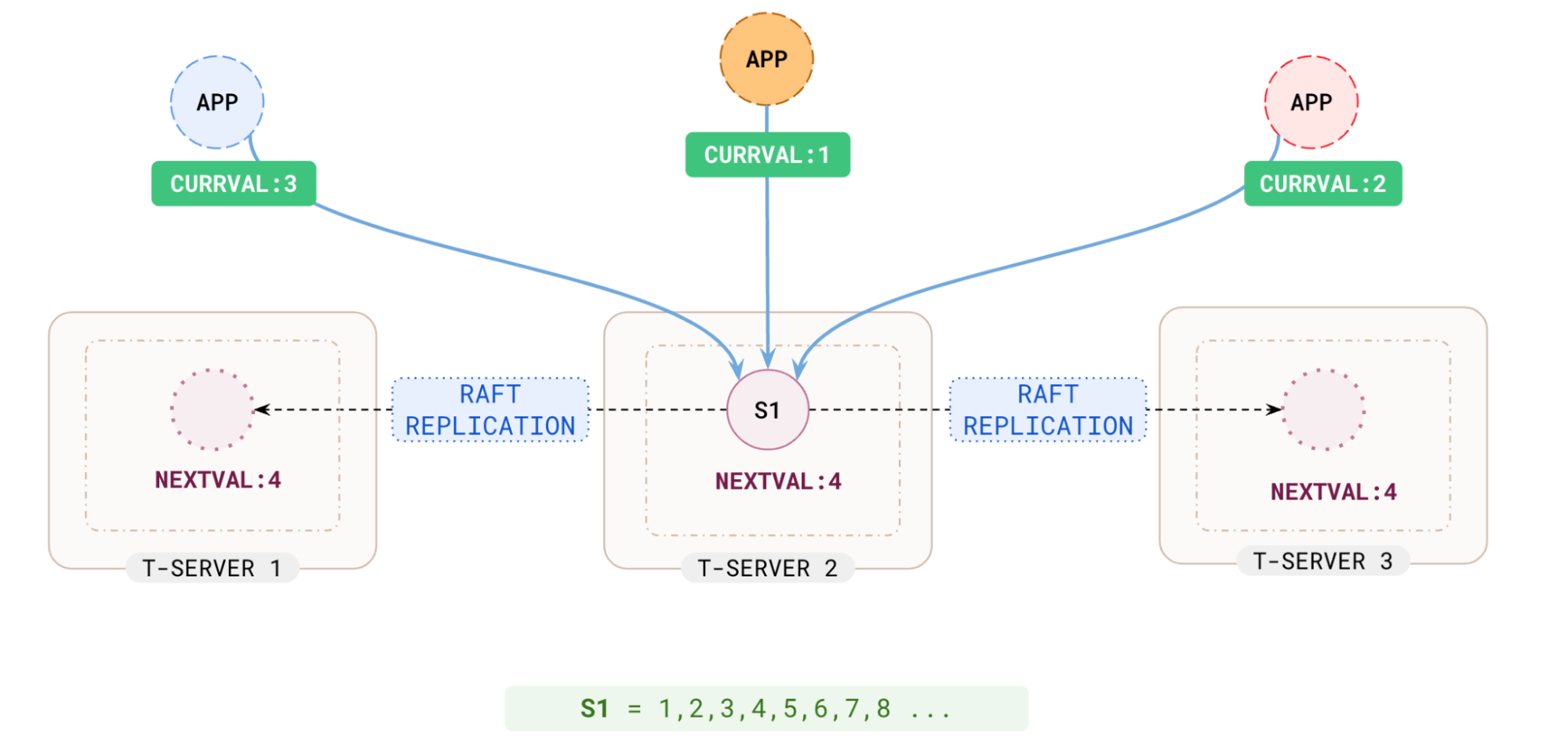
Scaling Sequences with Connection-Level Caching
Now, open a new connection to the database and fetch the next value of the sequence.
❯ ysqlsh
ysqlsh (11.2-YB-2.17.2.0-b0)
Type "help" for help.
yugabyte@yugabyte=# select nextval('s1');
nextval
---------
101
(1 row)You would have expected it to return 4 but it returned 101. This is due to the sequence values being generated upfront (defaulting to 100, but this default value can be increased during the sequence creation) and cached per connection for better retrieval performance. Without caching, after every generation, the state of the sequence would have to be persisted and replicated via RAFT consensus to the replicas. Thus the first sequence numbers (1-100) were generated and cached for the first connection, so the second connection starts at 101.
NOTE: The minimum value of the cache can be configured using the gflag ysql_sequence_cache_minval.
Similarly, on a different connection, it would start at a multiple of 100 plus the increment (1). One key thing to note is that, if a client disconnects, the per-connection sequence number cache is discarded.
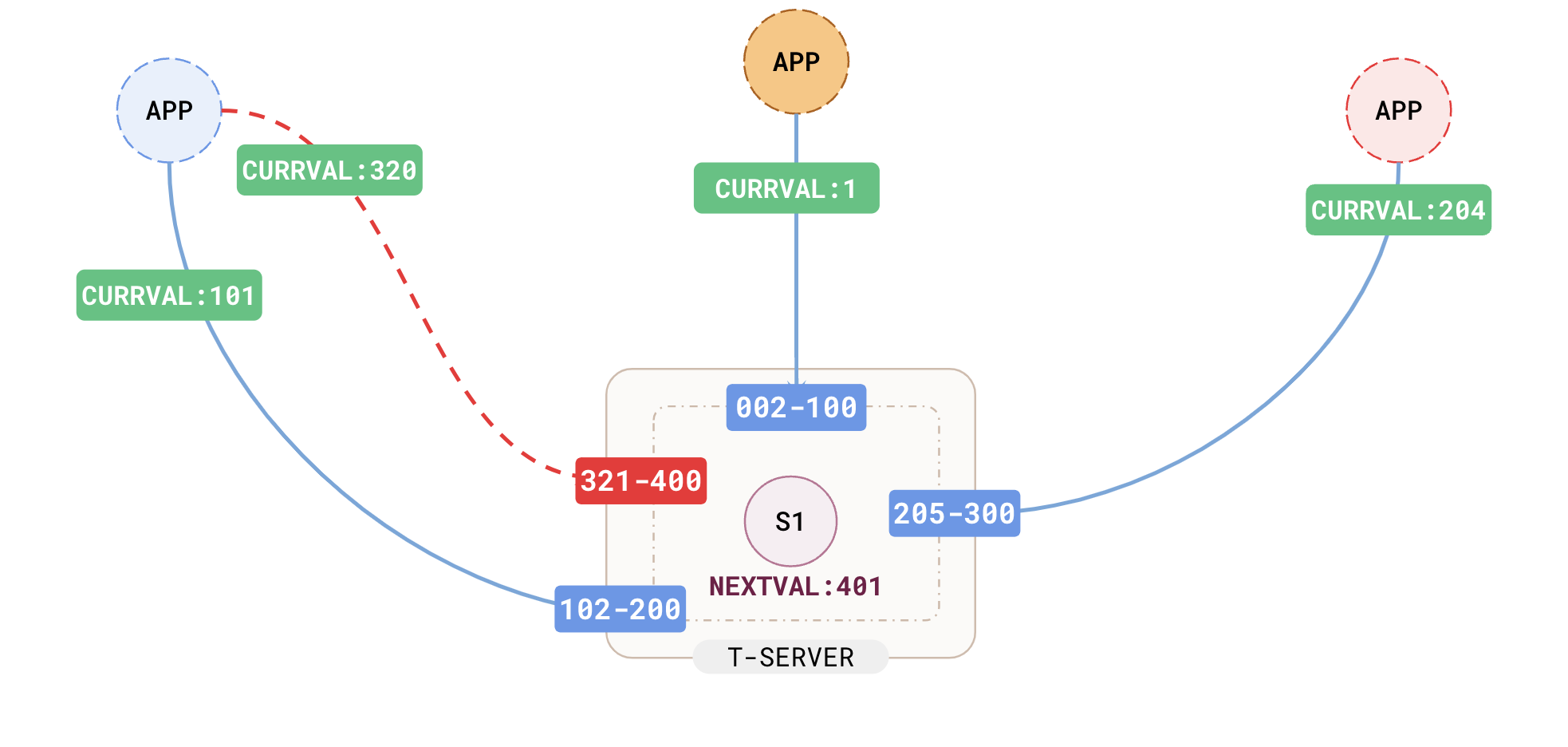
This is great, but what if many clients connect to the database simultaneously? Each connection will cache pre-generated numbers from the tablet leader where the sequence is kept. If there are a large number of connections or the cache is consumed fast, all connections would have to query the same tablet (i.e. shard), burdening the server and increasing latency due to RAFTreplication.
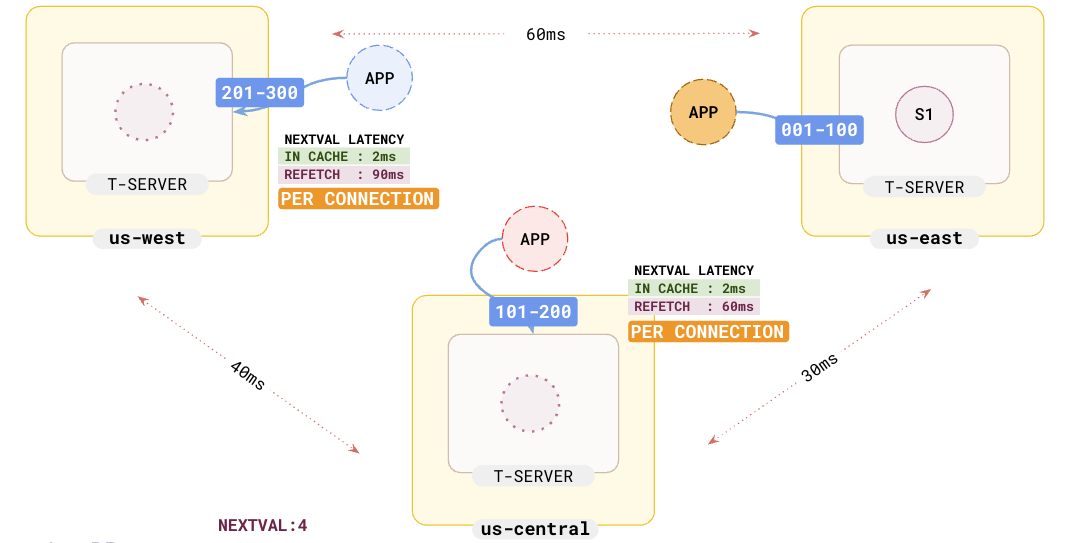
If you are scaling by adding application instances, all the new connections would query the same yb-tserver for new values since that is where the sequence is maintained. The problem is exacerbated in a multi-region as shown in the following illustration.
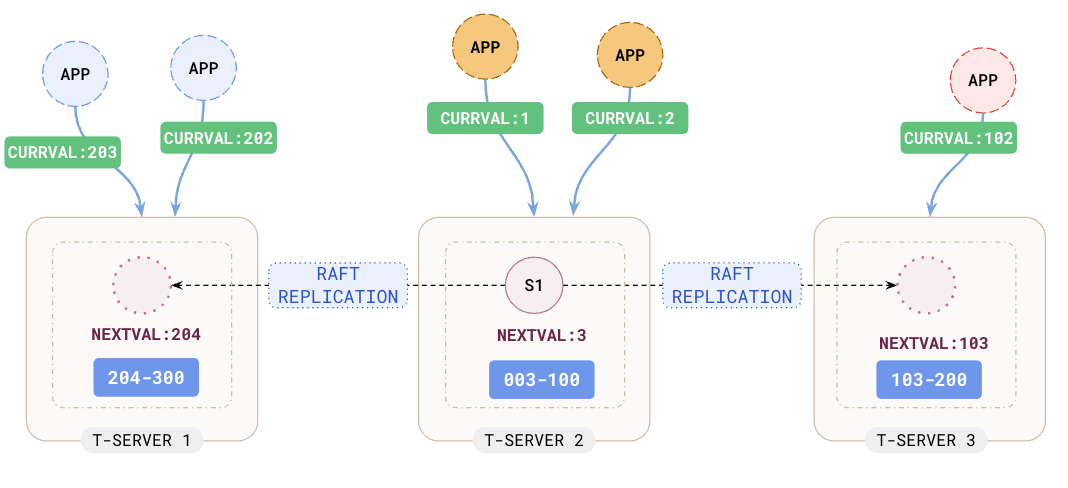
Scaling Sequences with YB-TServer Level Caching
To avoid going to the tablet/shard hosting the sequence for every connection and cache refresh, YugabyteDB now supports the caching of the sequence values per YB-Tserver. Now all connections to a specific yb-tserver will share the same cached sequence values. This capability can be turned ON using the yb-tserver gflag ysql_sequence_cache_method:
ysql_sequence_cache_method=server # (Note: the default method is connection)
Let’s connect to a specific node —127.0.0.1—and create a new sequence.
❯ ysqlsh -h 127.0.0.1 ysqlsh (11.2-YB-2.19.0.0-b0) Type "help" for help. yugabyte@yugabyte=# yugabyte@yugabyte=# CREATE SEQUENCE s2; CREATE SEQUENCE Time: 91.898 ms
Now let’s fetch some values from the sequence.
yugabyte@yugabyte=# SELECT nextval('s2');
nextval
---------
1
(1 row)
yugabyte@yugabyte=# SELECT nextval('s2');
nextval
---------
2
(1 row)
yugabyte@yugabyte=# SELECT nextval('s2');
nextval
---------
3
(1 row)This is as expected. Now, let’s open a new connection to the same server
❯ ysqlsh -h 127.0.0.1
ysqlsh (11.2-YB-2.19.0.0-b0)
Type "help" for help.
yugabyte@yugabyte=# SELECT nextval('s2');
nextval
---------
4
(1 row)Connecting to the same server provides the next sequence value since all connections share that server’s sequence cache. Now, let’s connect to a different cluster node, like 127.0.0.2.
❯ ysqlsh -h 127.0.0.2
ysqlsh (11.2-YB-2.19.0.0-b0)
Type "help" for help.
yugabyte@yugabyte=# SELECT nextval('s2');
' nextval
---------
101
(1 row)Since this connection was to a different node without any cached sequence values, it pulled new values from the sequences table for local caching. A new connection to this node will show the next value from these cached sequence values.
❯ ysqlsh -h 127.0.0.2
ysqlsh (11.2-YB-2.19.0.0-b0)
Type "help" for help.
yugabyte@yugabyte=# SELECT nextval('s2');
' nextval
---------
102
(1 row)With TServer-level cache enabled, when an application disconnects or if a connection is lost, the unused values in the cache are not discarded. They will be used by other connections. Since the cache is shared by multiple connections, you can increase the cache size appropriately (say to 1,000 or 10,000).
The minimum cache size for all sequences can be configured via the gflag ysql_sequence_cache_minval.
You can change the cache size of a specific sequence after the sequence is created using the ALTER SEQUENCE statement. For example, to increase the cache size to 1000:
ALTER SEQUENCE s2 CACHE 1000;
Also, this greatly reduces latency in multi-region setups since cache refresh happens per node, not per connection. The reduced latencies are evident in the illustration below.
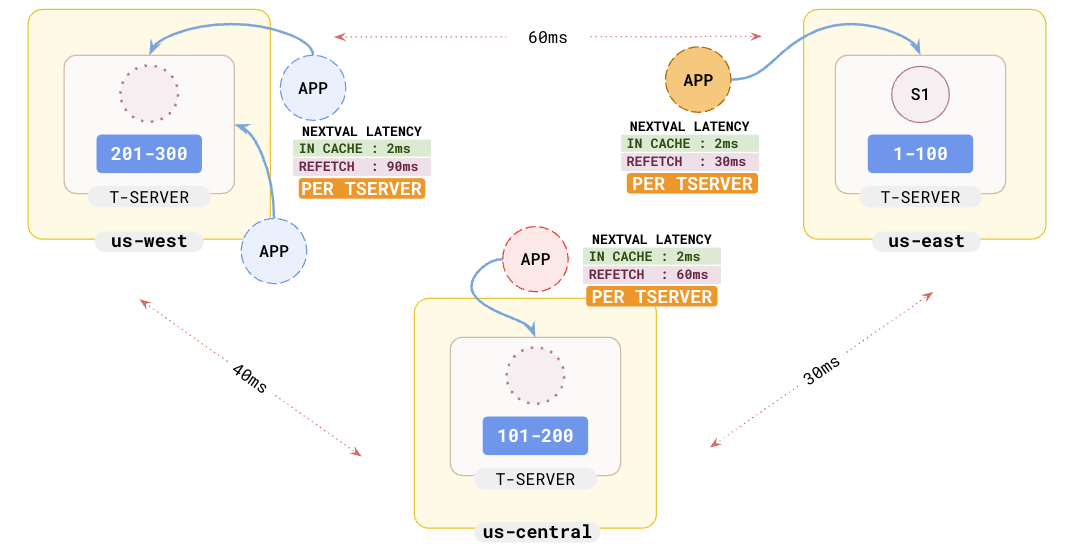
Conclusion
In a distributed database, sequence number generation is challenging and could become a latency-intensive operation. Use server-side UUIDs (or application-side ULIDs) when possible. For scenarios where server-side sequential/unique numbers are needed, database sequence is the right solution. Enabling the per-server sequence caching can greatly improve the performance of your applications, especially in a multi-region scenario.


