Data Replication in YugabyteDB
August 24, 2023
Database Management Systems (DBMS) are built to store and retrieve data efficiently. They are built on top of sophisticated storage engines that may sometimes be developed independently. Application developers should not have to focus on how to store and retrieve information but on building applications using DBMS.
YugabyteDB has developed a storage layer— DocDB—that is a customized version of RocksDB, providing persistent storage, transaction processing, and data replication. Because YugabyteDB is a distributed database that emphasizes data consistency, synchronous data replication is very important, used to satisfy different use cases. For even greater flexibility, the Yugabyte database also provides data replication at different levels in both synchronous and asynchronous patterns. This article explains in detail the different data replication options available with YugabyteDB.
How Synchronous Replication Works in YugabyteDB
YugabyteDB, a distributed SQL database, contrasts with legacy monolithic database servers by storing data on multiple servers to enhance fault tolerance and high availability. To overcome the challenge of achieving consensus among various nodes, YugabyteDB employs the RAFT (Replication and Fault Tolerance) protocol, ensuring consistent data replication across different database nodes within the same cluster.
In YugabyteDB, tables are sharded into tablets and stored across different fault domains, with the number of copies determined by a cluster’s Replication Factor (RF). Replication occurs at the tablet level through the RAFT protocol, with one tablet initialized as the leader and the rest as followers. This leader-based consensus protocol facilitates log flows from the leader to followers. Leader and follower are two states of the tablet during normal operation.
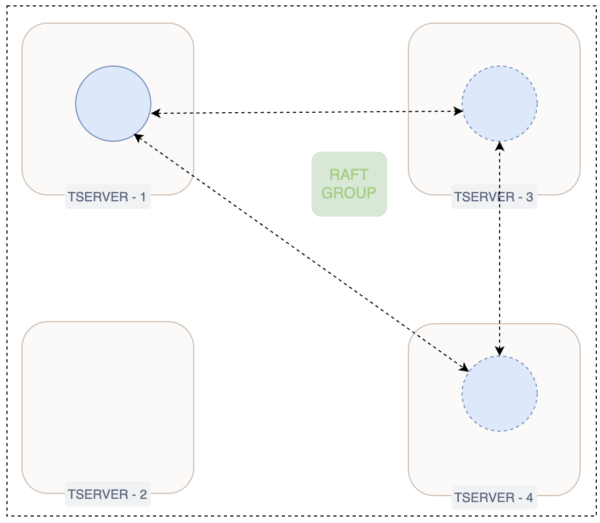
The tablet leader serves both read and write requests from clients. Upon receiving a write request, the leader sends the log entry to all tablet peers and waits for acknowledgment from at least half of them. Only after receiving these acknowledgments does the leader commit the change and acknowledge the client.
There are situations when either a tablet leader or follower goes offline, possibly due to a network partition or planned maintenance. There is no impact when a tablet follower goes offline.
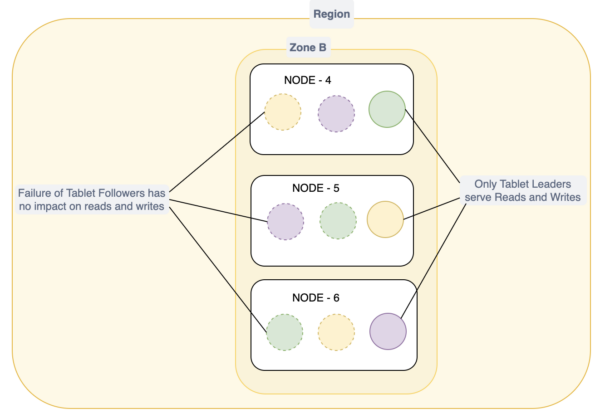
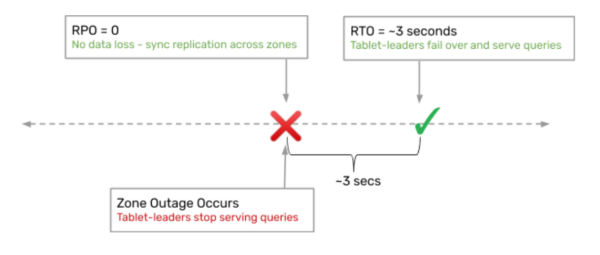
However, if a tablet leader goes offline, a tablet peer/follower must take its place and start handling reads and writes. The Recovery Point Objective (RPO) in this situation is zero, and the Recovery Time Objective (RTO) is 3 seconds, meaning a new leader will be elected within that time frame. Tablet leaders send regular heartbeat signals to followers, and if a follower fails to receive one in a specific time, it becomes a candidate for leadership, issuing a vote request. To prevent multiple followers from becoming candidates simultaneously, timeout values are set randomly for each. The RAFT protocol ensures that the follower with all the log entries is elected as the new leader.
If the tablet leader or follower goes offline and comes back to join the RAFT group, it must synchronize with the changes. The tablet leader will send both previous and current log entries together to the tablet peer, which updates the current entry only if the previous one matches. If they don’t match, the peer returns an error, compelling the leader to send the older two entries. This process continues until the tablet peer is caught up with all the log entries.
Read Replica in YugabyteDB
Read replica is a separate cluster within the same universe that can serve read-only workloads. DocDB utilizes RAFT replication to asynchronously copy to read replica nodes (also known as observer nodes). This configuration is favored for applications that require higher latency if they are included as part of the primary cluster.
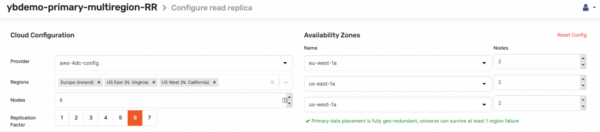
These independent clusters (potentially including multiple read replica clusters within the same universe) can have a different Replication Factor (RF) than the primary universe. The RF can be 1 or any even number since these tablets don’t participate in the RAFT consensus logic. Once a Read Replica cluster is built with an RF, it cannot be modified. All schema changes are replicated with eventual consistency through RAFT. Any config changes and software upgrades are at the universe level; therefore, they are automatically propagated to the Read Replica clusters as well. As the Read Replica is part of the primary universe, any DML directed at the read replica is forwarded to the primary cluster, and the changes are replicated back to the Read Replica asynchronously.
xCluster Replication in YugabyteDB
Asynchronous replication between a source and a target cluster safeguards against regional failure, while synchronous replication, typically spread across an odd number of fault domains within a region, ensures lower latency for reads and writes. If fault domains extend to another region, latency increases due to the use of RAFT in synchronous replication, which may be unacceptable for some applications. In scenarios that require business continuity or disaster recovery solutions and where complete region loss is a concern, data must be replicated across two independent clusters.
YugabyteDB provides xCluster replication, similar to the disaster recovery (DR) solutions offered by traditional relational databases. xCluster replication can replicate data across independent primary clusters asynchronously. The data is replicated at the DocDB level with the committed data replicated to the target cluster. Currently, xCluster supports both active-passive unidirectional and active-active* bidirectional replication. More complex topologies are not supported with xCluster replication.
*Note: To develop applications using xCluster use these patterns:
xCluster replication can be set up to operate in two modes—non-transactional replication and transactional replication.
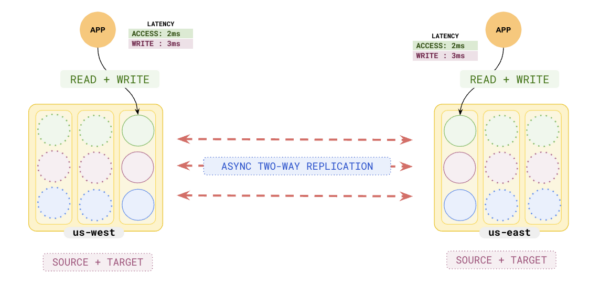
Non-Transactional Replication
With a non-transactional replication, bidirectional replication is allowed, and whenever there is a conflict, the last writer wins. The target universe is on the READ COMMITTED isolation level which only guarantees that the reader does not see any uncommitted transactions. There is no guarantee that a reader will see a consistent snapshot of all committed data prior to the statement execution.
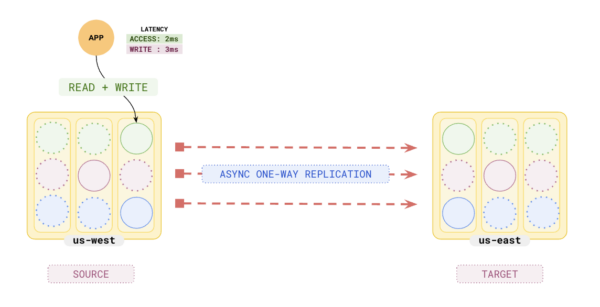
Transactional Replication
With transactional replication, the only supported topology is active-passive unidirectional replication. The target cluster maintains an xCluster Safe Time, which is the consistent snapshot time that the queries would read the data. With this topology, the xCluster provides an option for either a planned or unplanned switchover.
Planned Switchover
With a planned switchover, the application connections are drained, and the target cluster is allowed to catch up with all changes before initiating the role change. With a planned failover, the RPO is zero, and the RTO depends on how quickly the application connections can be changed to point to the target universe.
Unplanned Switchover
In an unplanned switchover, the primary cluster is lost, and the target cluster’s role will be changed to primary. The RPO depends on the replication lag, while the RTO is similar to a planned switchover, depending on how quickly the connections can be redirected to the target universe. The target universe must have point-in-time recovery enabled so that during the role change, the universe can be rolled back to xCluster safe time.
Achieving High Availability and Disaster Recovery with Two Data Centers >>>
Increase BCDR Protection with Enhanced xCluster Replication >>>
Change Data Capture
Enterprises today need to be able to make sense of transactional data very quickly. Therefore, they need to replicate the data to large data warehouses quickly for data analytics. Change Data Capture (CDC) is an ideal solution for this. CDC can be built using several methods, such as a trigger-based approach or mining the database transaction logs to create a stream of changes for the desired target. Every solution comes with its own advantages and disadvantages. The trigger-based method can significantly reduce the primary database’s performance, while the log mining approach is challenging due to proprietary formats and limited information from vendors.
With YugabyteDB, the yb-tserver has a stateless CDC service that is used to create a stream of database changes. Debezium connector for YugabyteDB can be used to consume events generated by the CDC stream and pushed into a Kafka topic. Any other application can use these messages to process or store forward into a target.
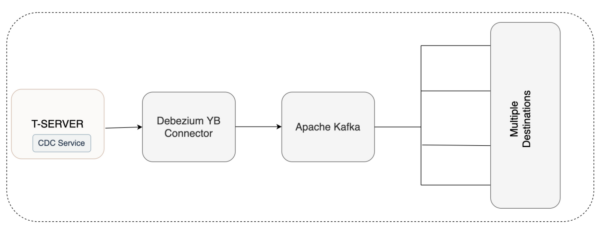
YugabyteDB CDC provides 3 guarantees:
- The order of changes delivered is guaranteed only if the changes are within a single tablet. Any changes from multiple tablets can be received out of order.
- The changes are pushed at least once, guaranteeing no messages are lost.
- CDC ensures there are no gaps; that is, if a message is received per timestamp, then all messages prior to that timestamp have been already pushed.
Conclusion
YugabyteDB’s key design goals include strong consistency guarantees and high availability during tablet leader failure. It offers multiple solutions using asynchronous replication and streams database events to different destinations as required by the application. This allows database architects to select various patterns, designing a highly available infrastructure to provide a seamless user experience.


