Achieving High Availability and Disaster Recovery with Two Data Centers
April 20, 2023
Synchronous replication in the Raft groups, which requires the majority of replicas for each tablet, is crucial to YugabyteDB’s cluster resilience as it ensures a zero data loss failover (or Recovery Point Objective of zero) for high availability. For high performance, the acknowledgement of the majority, rather than all replicas, is sufficient as the majority can vote for a new leader in case of a Raft leader failure.
Configurations typically involve a Replication Factor (RF) of 3, where a write to the leader waits for acknowledgement from one follower; the write is committed without waiting for the other since the leader and one follower form the majority. Replicas are distributed across different fault domains, such as data centers, zones, or regions, according to the desired fault tolerance level. In case of failure, functional replicas within the Raft group can serve consistent reads and writes, while those that have partitioned away from the Raft consensus quorum cannot make progress. For example, a Raft leader isolated from all of its followers cannot show the current state because it doesn’t know if a new leader was elected, after its lease, on the other side of the network partition.
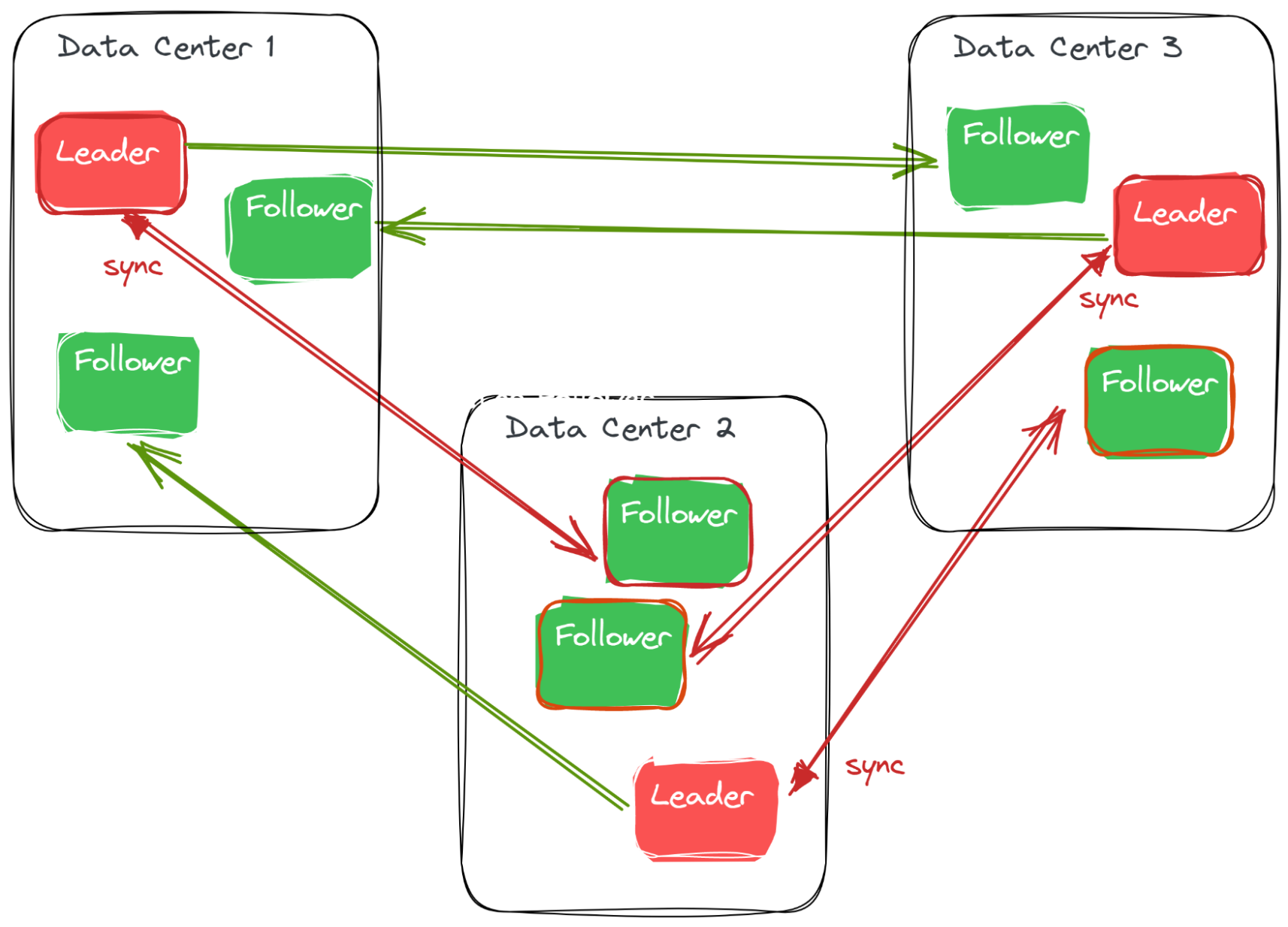
Constraints of Synchronous Replication
Synchronous replication is advantageous because it provides high availability (HA) for common failures and ensures no-data-loss disaster recovery (DR) if a data center is destroyed. The most common deployment scenario involves replication factor of 3 spread over 3 fault domains, but higher replication factors can be utilized to increase fault tolerance. For instance, in the cloud, replication factor (RF) of 5 spread over 3 regions can withstand a total region failure and one additional node failure in another region.
There are two constraints associated with a synchronous replication.
- Latency. With a quorum-based replication factor of 3, writes to the Raft leader will wait for one replica to acknowledge before acknowledging the write. Therefore, at least two regions must be in close proximity to the client to guarantee low latency. The Raft leader is placed in one of these two regions; writes will have low latency as long as both regions are functioning.
- Number of fault domains. A replication quorum requires at least three failure zones. In the cloud, it is common to deploy to three data centers because many cloud regions have at least three availability zones (AZs), and many cloud providers have at least two regions close enough to provide low latency. However, if you are in a region with only two AZs or on-premises with only two data centers, you need an alternative solution for disaster recovery.
It is necessary to distinguish between disaster recovery and high availability when there are only two data centers. Regardless of the technology, achieving no-data-loss disaster recovery alongside high availability is impossible. So as a reference for those migrating from traditional databases to distributed SQL, let’s examine traditional database log streaming replication,to ensure the same Recovery Point Objective (RPO) and Recovery Time Objective (RTO) is maintained after migrating to an horizontally scalable architecture.
Traditional Monolithic Databases’ Physical Replication
To protect from infrastructure failures, traditional databases such as Oracle, SQL Server or PostgreSQL employ log streaming replication. In this scenario, the primary database is located in one data center and serves both reads and writes, while a standby database is located in the second data center and can only serve non-current reads (since it is not aware of the ongoing transactions on the primary). This synchronization can be automated with tools such as Data Guard for Oracle, Always On for SQL Server, and Patroni for PostgreSQL. In these configurations, a single stream of transactional logging (redo log for Oracle, transaction log for SQL Server, WAL for PostgreSQL) is sent asynchronously from the primary database to the standby database. There are two possibilities in this case.
- “Max protection” mode of Data Guard or “strict synchronous mode” of Patroni, which provides no-data-loss disaster recovery by waiting for the acknowledgement of the standby database at commit. This means that any committed transaction on the primary database is guaranteed to be recoverable on the standby database. In the event of network failure, if the standby database is inaccessible, the primary database will hang at commit for all transactions, which is not a desirable situation for high availability purposes.
- “Max Performance” mode of Data Guard, “Asynchronous-commit mode” of Always On or Patroni, which provides high availability through asynchronous replication, even for the commit record. This means that the primary database is always available, but disaster recovery may miss the latest committed transactions.
Is it possible to achieve both high availability on the primary and a no-data-loss disaster recovery? Yes, it is possible, but it requires more than two data centers. With three data centers, you can replicate asynchronously to both and wait at commit for only one of them, ensuring that the primary remains available even in the event of a network failure to one data center. If one standby data center is destroyed, the other can acknowledge and the primary continues to function. If the primary data center is destroyed, the most caught up data center can be activated without any data loss. This process, for a monolithic database, is similar to the quorum mentioned above for each tablet, except that, requiring a full database failover, it has a higher Recovery Time Objective (RTO) than that of a distributed SQL database.
Monolithic Database Replication Between Two Data Centers
With only two data centers, you have to choose between synchronous commit for no-data-loss DR and asynchronous commit for high availability. There’s also a third mode, with confusing names: “non-strict synchronous commit” in Patroni, “Synchronous-commit” in Always On, or “Max Availability” in Data Guard. Those can switch between synchronous and asynchronous:
- When there is no failure, commits are synchronous to guarantee no data is lost in case of failover; commit takes longer but the latest committed transactions are stored on the standby
- When there is a failure, replication switches (after a configurable timeout) to asynchronous commit to restore availability; the timeout is short to avoid the primary to stall for too long but cannot provide a no data loss failover
However, when it comes to availability, this mode is not optimal in a two data center (2DC) configuration where the network between them is a single point of failure. If there is no failure, and the primary and the standby can communicate, then recovery is not required. Similarly if there is a network failure but the primary stays available to the application, there’s no need for recovery either. But if there’s a failure and the primary becomes unavailable, recovery is necessary. Unfortunately, in this case, commits have switched to asynchronous mode, meaning that there may be some data loss.
In a two data center configuration, the “Max Availability” mode of Oracle Data Guard, the “Synchronous-commit” in Always On, or the “non-strict synchronous mode” of Patroni, adds latency to all transactions and typically only allows for no data loss recovery when there’s no failure to recover. It is in practice similar to the asynchronous mode. There’s only one scenario when this intermediate mode can provide RPO=0 in a 2DC deployment, and that’s when the disaster begins by destroying the primary before any network issue. In that case, replication may have remained synchronous until the primary database was down for the application. All committed changes would be available on the standby. Testing your recovery plan with a simple shutdown of the primary database would put you in this scenario and make you feel protected. However, in a real disaster, this is unlikely to be the case. If the data center burns down, there’s a good chance that you’ll experience some network issues, and that the “Max Availability” mode will have switched to asynchronous before the database goes down for all applications. In practice, a fault-tolerant primary relies on asynchronous replication to the Disaster Recovery data center.
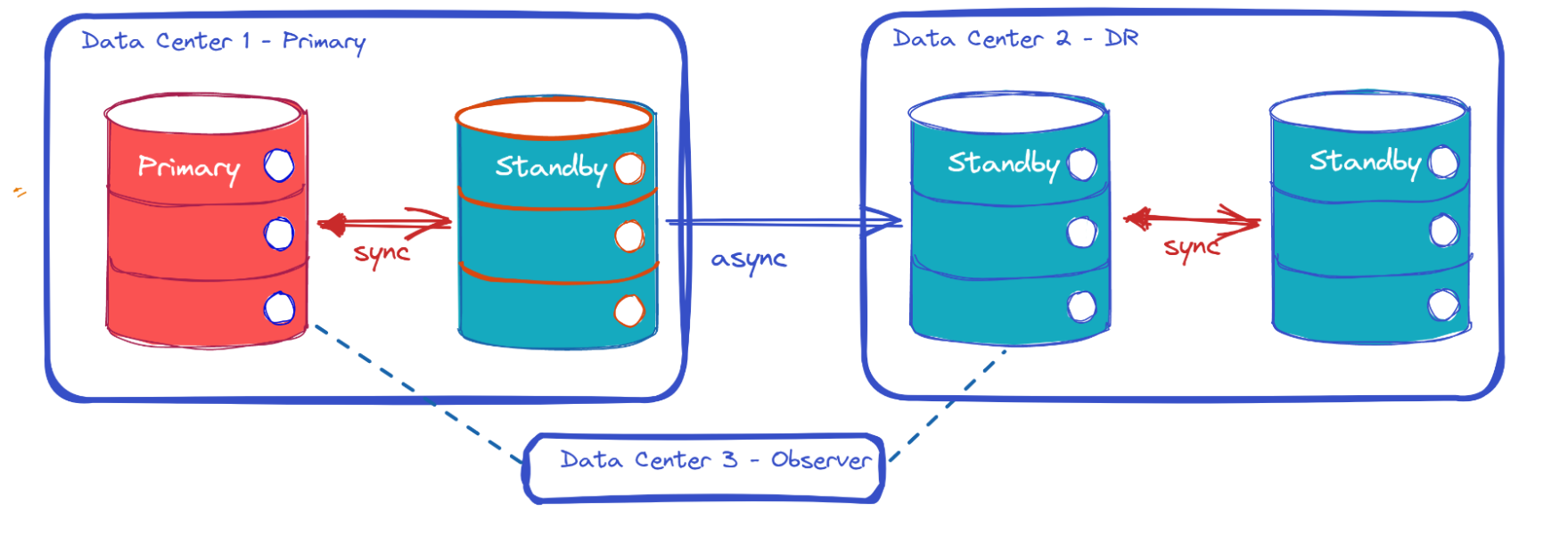
The principle behind the Oracle Active Data Guard “Far Sync” is the same: the redo stream is stored synchronously within the same data center, but sent asynchronously to the DR data center to avoid compromising the primary’s availability. In all cases, you still need a synchronous standby in each data center as the monolithic database by itself is not resilient to common failures.
During my consulting experience, I had a discussion with a user who was surprised during their disaster scenario test. They had completed all necessary validations and were 100% confident in their configuration. So they decided to conduct a real test during a maintenance weekend. They ran the application and then shut down the power to the data center, but that’s when they realized that not all components stop at the same time. Some network switches stopped before others, and the standby became unreachable while the application continued to commit changes for a few seconds. The standby database was not synchronized and the automatic failover didn’t happen. They realized that this configuration had a Recovery Time Objective of hours (since the failover is manual) and a Recovery Point Objective higher than zero. That’s not the fault of the technology, but it is an inherent problem if there are only two data centers.
Does that mean that you cannot have both High Availability and Disaster Recovery in a 2DC configuration? Of course not. However, you do need to address them differently. High availability should be prioritized for the most common failures within a data center, such as server or storage failure or network issues. Meanwhile, disaster recovery should be planned for rare scenarios where the entire data center is lost due to fire, flood, or earthquake. If high availability is the priority, then replication between the two data centers must be asynchronous, which may result in some data loss during a rare disaster recovery situation. If you cannot accept any data loss, then adding another data center, on-premises or in the cloud, to get a quorum is necessary. Without a quorum, you cannot determine the latest changes.
Another reason for the quorum is to avoid “split brain”, which is when both sides believe they are the primary and take unsynchronized actions, leading to data corruption. It’s not always necessary to have a full third replica to prevent split brain; a third site running an observer can be sufficient. However, this solution does not address the issue of both HA and DR. In reality, failover to the standby will never occur when no-data loss is not guaranteed. In a 2DC scenario, disaster recovery is a human decision because one must determine what happened on the primary site, whether it was a short network disconnect or an unrecoverable loss of the entire data center, and how the application was available to users before all was down.
Distributed SQL Replication
Before delving into the YugabyteDB solution, it’s important to understand a key difference between traditional database streaming replication and distributed SQL replication. Traditional databases are monolithic, with only one instance that can write to the database files. These writes are protected by the write ahead logging (WAL or transaction/redo log), which is also monolithic, creating a single stream recording the changes to the physical pages. This leads to asynchronous replication being possible for all writes except for the commit record since all previous changes are ensured to be applied.
Distributed SQL, on the other hand, is designed to be horizontally scalable, meaning there is no single stream. In YugabyteDB, for example, each shard (called tablets) is its own Raft group that replicates changes in parallel. The transaction tables also replicate their changes, such as the commit record, in parallel. While this enables scaling with multiple streams running concurrently, synchronous replication introduces cross-datacenter latency to all writes, not just at commit.
Note that there is one exception in traditional databases: Oracle RAC allows for multiple threads of redo for one database, but they still need to be synchronized when applied in parallel. A full comparison of Oracle Maximum Availability options with YugabyteDB resilience was done at Comparing the Maximum Availability of YugabyteDB and Oracle Database.
Given these considerations, it’s clear that synchronous replication between two data centers is not a fool-proof fault tolerant solution, no matter what technology is used. Stretching a YugabyteDB cluster across two data centers would add more latency to all writes, leave changes unprotected if the quorum is on the primary side (one leader and one follower on the “primary” side), or add more latency to all writes when the quorum involves the standby (two followers on the standby), and makes the primary unavailable if the standby is down.
The right solution includes two key components:
- Fault tolerance: Synchronous quorum replication on each data center to protect against the most common failures and provide high availability.
- Disaster recovery: Asynchronous replication between the two data centers to protect against the rare total failure of a data center
YugabyteDB Cross-Cluster Replication
For fault tolerance, a YugabyteDB cluster is created in each data center with a replication factor of 3 spread over 3 failure domains within the data center. It is ideal to use different racks, and if possible, different failure zones. For disaster recovery, an additional asynchronous replication is established between the two clusters. This is accomplished using YugabyteDB xCluster, which is part of the open-source database.
This must be used as an active-passive configuration to avoid replication conflict and keep ACID guarantee. To help with this, a role can be set to each cluster so that one is considered active, and the other standby. The goal is to accept only reads on the standby cluster.
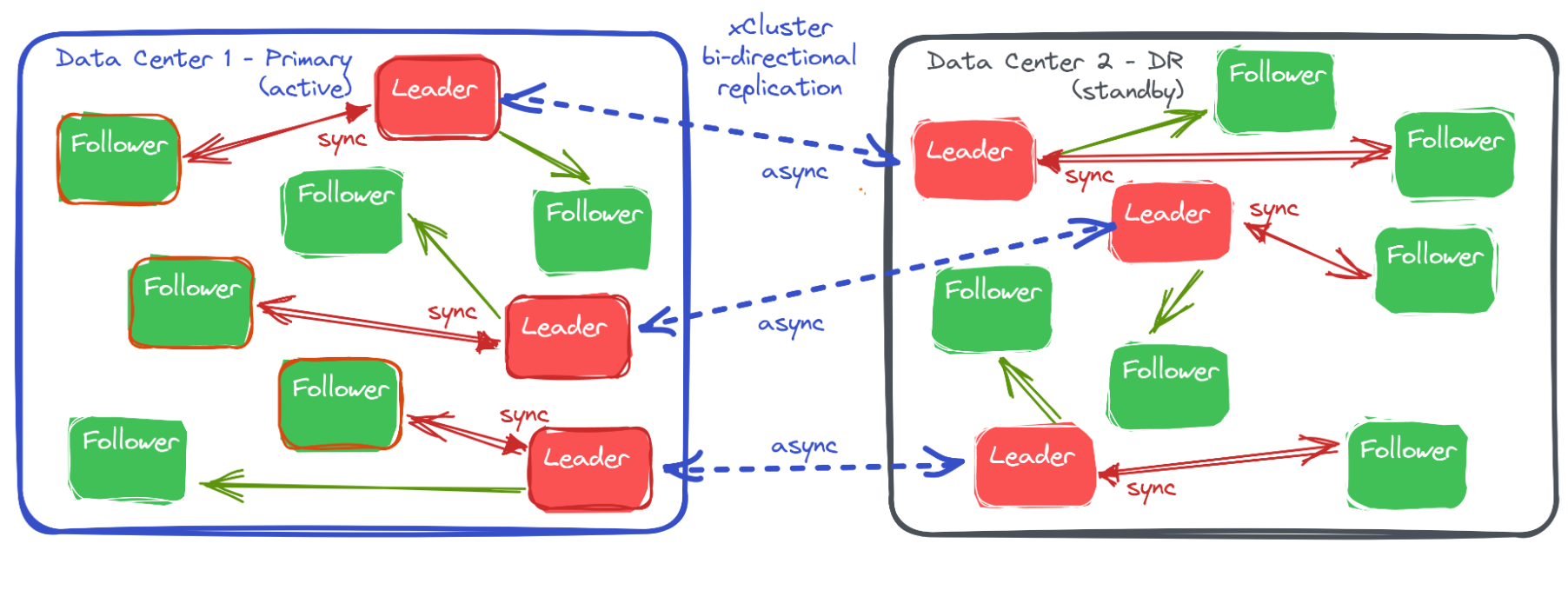
With this xCluster configuration, you have high availability to provide application continuity when any component, compute, network, or storage fails in one data center. If communication between the two data centers fails, the primary will stay active and remain available for the application. The standby can provide reads for reporting. The reads from the standby are like follower reads within a cluster, and they may lag behind the latest changes. However, they still provide a consistent state of the database. As we mentioned earlier, there are multiple replication streams, so some tablets may lag more than others. However, by using multi-version concurrency control and maintaining a xCluster Safe Time, YugabyteDB exposes the latest transactional consistent state.
If the standby data center burns down, the primary is still active with high availability—thanks to its synchronous replication to quorum over the data center failure zones. If the primary data center burns down, you can decide to activate the standby on the DR site to get the application available again. You can check for possible data loss, which is the gap between the failure time and the xCluster Safe Time mentioned above. As with any asynchronous replication, the decision to failover and open the application will depend on what happened to the primary site and whether it is completely destroyed or expected to be available again in a short time.
In scenarios other than a disaster, it may be necessary to switch over to a different data center for configuration testing purposes, to carry out significant maintenance on one data center, or to balance the load between the two. The good news is that this can be accomplished without any data loss, thanks to a graceful failover that ensures the primary has replicated all write operations before the switch takes place.
Note that YugabyteDB is the only distributed SQL database that provides cross-cluster replication, and is true open source. The recent features that allow the safe failover and switchover mentioned above are found in our latest release and described in our blog post, YugabyteDB 2.17: Increased BCDR Protection with Enhanced xCluster Replication.


