Deploying a Real-Time Location App with Hasura GraphQL Engine and Distributed SQL
August 21, 2020
Hasura is one of the leading vendors in the GraphQL ecosystem. They offer an open source engine that connects to your databases and microservices, and then auto-generates a production-ready GraphQL backend. GraphQL is a query language (more specifically a specification) for your API, and a server-side runtime for executing queries by using a type system you define for your data. GraphQL is often used for microservices, mobile apps, and as an alternative to REST. Although GraphQL isn’t tied to any specific database or storage engine and is instead backed by your existing code and data, YugabyteDB is a perfect complement to GraphQL giving you horizontal scalability, fault tolerance, and global data distribution in a single system.
In this blog post we’ll show you how to do:
- Install a 3 node YugabyteDB cluster on Google Kubernetes Engine (GKE)
- Deploy the Hasura GraphQL Engine on GKE
- Stand up Hasura’s “realtime-location-tracking” app locally and connect to resources on GKE
The “realtime location application” is built using React and is powered by Hasura GraphQL Engine backed by a 3 node YugabyteDB cluster. It has an interface for users to track location of a vehicle using Hasura live queries, in real time. The application makes use of Hasura GraphQL Engine’s real-time capabilities using subscription.

New to distributed SQL or YugabyteDB? Read on.
What is Distributed SQL?
Distributed SQL databases are becoming popular with organizations interested in moving data infrastructure to the cloud or to cloud native environments. This is often motivated by the desire to reduce TCO or move away from the scaling limitations of monolithic RDBMS like Oracle, MySQL, and SQL Server. The basic characteristics of Distributed SQL are:
- A SQL API for querying and modeling data, with support for traditional RDBMS features like primary keys, foreign keys, indexes, stored procedures, and triggers.
- Automatic distributed query execution so that no single node becomes a bottleneck.
- A distributed SQL database should support automatically distributed data storage. This includes indexes which should be automatically distributed (aka sharded) across multiple nodes of the cluster so that no single node becomes a bottleneck for ensuring high performance and high availability.
- Distributed SQL systems should also provide for strongly consistent replication and distributed ACID transactions.
For a deeper discussion about what Distributed SQL is, check out, “What is Distributed SQL?”
What is YugabyteDB?
YugabyteDB is an open source, high-performance distributed SQL database built on a scalable and fault-tolerant design inspired by Google Spanner. YugabyteDB is PostgreSQL wire compatible with support for advanced RDBMS features like stored procedures, triggers, and UDFs.
Step 1: Install YugabyteDB on a GKE Cluster Using Helm 3
In this section we are going to install YugabyteDB on the cluster. The complete steps are documented here. We’ll assume you already have a GKE cluster up and running as a starting point.
The first thing to do is to add the charts repository.
$ helm repo add yugabytedb https://charts.yugabyte.com
Now, fetch the updates.
$ helm repo update
Create a namespace. In this case we’ll call it yb-demo.
$ kubectl create namespace yb-demo
Expected output:
namespace/yb-demo created
We are now ready to install YugabyteDB. In the command below we’ll be specifying values for a resource constrained environment.
$ helm install yb-demo yugabytedb/yugabyte \ --set resource.master.requests.cpu=1,resource.master.requests.memory=1Gi,\ resource.tserver.requests.cpu=1,resource.tserver.requests.memory=1Gi,\ enableLoadBalancer=True --namespace yb-demo --wait
To check the status of the cluster, execute the below command:
$ kubectl get services --namespace yb-demo
![]()
Note the external-IP for yb-tserver-service which we are going to use to establish a connection between YugabyteDB and Hasura. In this demo, the IP is 35.224.XX.XX and the YSQL port is 5433.
Step 2: Setting up Hasura to Use YugabyteDB
Get the Hasura Kubernetes deployment and service files by executing the commands below.
$ wget https://raw.githubusercontent.com/hasura/graphql-engine/master/install-manifests/kubernetes/deployment.yaml
$ wget https://raw.githubusercontent.com/hasura/graphql-engine/master/install-manifests/kubernetes/svc.yaml
Modify the database URL in deployment.yaml file to include the IP of YugabyteDB. This file can be edited using a text editor like vi. Note that by default the yugabyte user in YugabyteDB doesn’t have a password and the default database is yugabyte.
For the purposes of this tutorial, the modification should look like this:
value: postgres://yugabyte:@35.224.XX.XX:5433/yugabyte
Note: If you’d like everything to run in the yb-demo namespace, make sure to modify the namespace value in both the deployment.yaml and svc.yaml files. This is the setup I have chosen for this demo.
After saving the file use kubectl to create a Hasura deployment using the commands below:
$ kubectl create -f deployment.yaml deployment.apps/hasura created
$ kubectl create -f svc.yaml service/hasura created
To find the external IP and open the Hasura console execute the command below:
$ kubectl get services --namespace yb-demo

Now use https://<EXTERNAL-IP>/console to access the Hasura console. In this case it is 34.68.XX.XX. You should now see the Hasura console.
Step 3: Install the Realtime Tracking Location App
In step 3 we’ll be working locally. For the purposes of this demo, I am on a Mac.
Download the sample applications
$ git clone https://github.com/hasura/graphql-engine
$ cd graphql-engine/community/sample-apps/realtime-location-tracking
Install the Hasura CLI
$ curl -L https://github.com/hasura/graphql-engine/raw/stable/cli/get.sh | bash
Modify the config.yaml file
Navigate to the hasura/ directory and edit the config.yaml file with the external IP of the Hasura service. For example:
endpoint: https://34.68.XX.XX
Modify the docker-compose.yaml file
Within the same hasura/ directory modify the docker-compose.yaml file with the following changes.
Eliminate the need for a password.
environment: - “POSTGRES_PASSWORD:“
Modify the port assignment so it can connect to YugabyteDB.
ports: - “5433:5433“
Specify the connect string with YugabyteDB parameters.
environment: - HASURA_GRAPHQL_DATABASE_URL: postgres://yugabyte:@35.224.xx.xx:5433/yugabyte
Modify the constants.js file
Navigate to the src/ directory and edit the constants.js file with the following changes.
//Constants file export const HASURA_GRAPHQL_URL = '34.68.XX.XX/v1/graphql'; const HASURA_GRAPHQL_ENGINE_HOSTNAME = '34.68.XX.XX';
Apply the migrations
Navigate back to the hasura/ directory and run the migration scripts.
$ hasura migrate apply
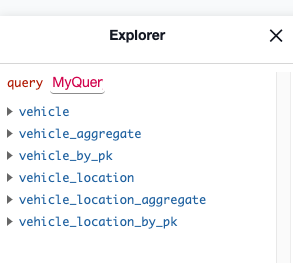
You should now be able to see the sample apps tables in the Hasura console.
Start the application
We are now ready to run the app at the root of the application located at ~/graphql-engine/community/sample-apps/realtime-location-tracking/
Note: You’ll need to Install Node.js if not already present on your system.
$ npm start
You should see a browser window open up with the landing page for the sample app.
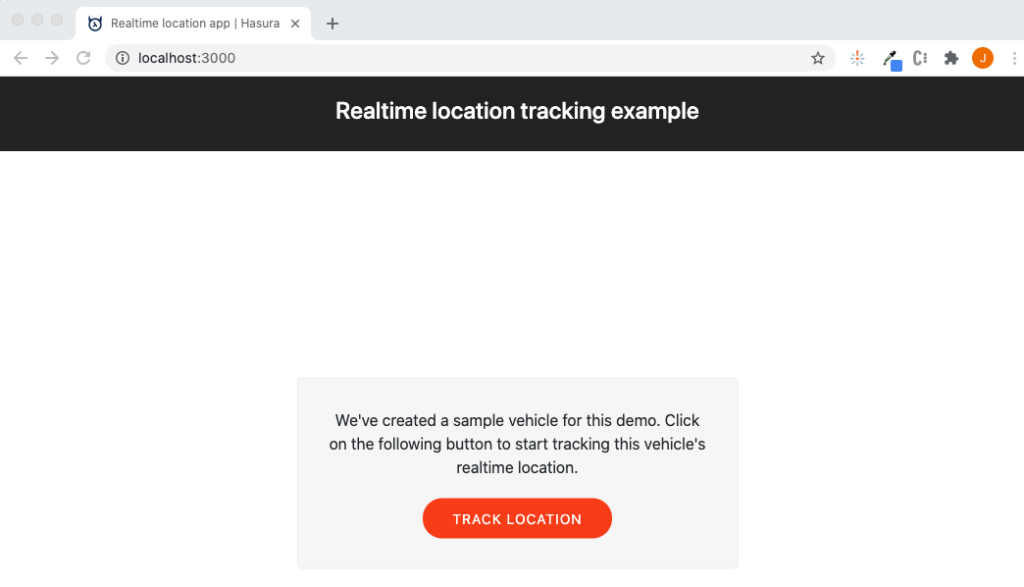
Click on the “track location” button to view a real time location tracking example.
![]()
Conclusion
That’s it! You now have the Hasura GraphQL Engine running on top of a 3 node YugabyteDB cluster on GKE. The GraphQL realtime location tracking application is running locally but leveraging Hasura and YugabyteDB in the cloud.


