When Should You Use Distributed PostgreSQL For Gen AI Apps?
June 3, 2024
Postgres continues to evolve the database landscape beyond traditional relational database use cases. Its rich ecosystem of extensions and derived solutions has made Postgres a formidable force, especially in areas such as time-series and geospatial, and most recently, gen(erative) AI workloads.
Pgvector has become a foundational extension for gen AI apps that want to use Postgres as a vector database. In brief, pgvector adds a new data type, operators, and index types to work with vectorized data (embeddings) in Postgres. This allows you to use the database for similarity searches over embeddings.
Pgvector started to take off in 2023, with rocketing GitHub stars:
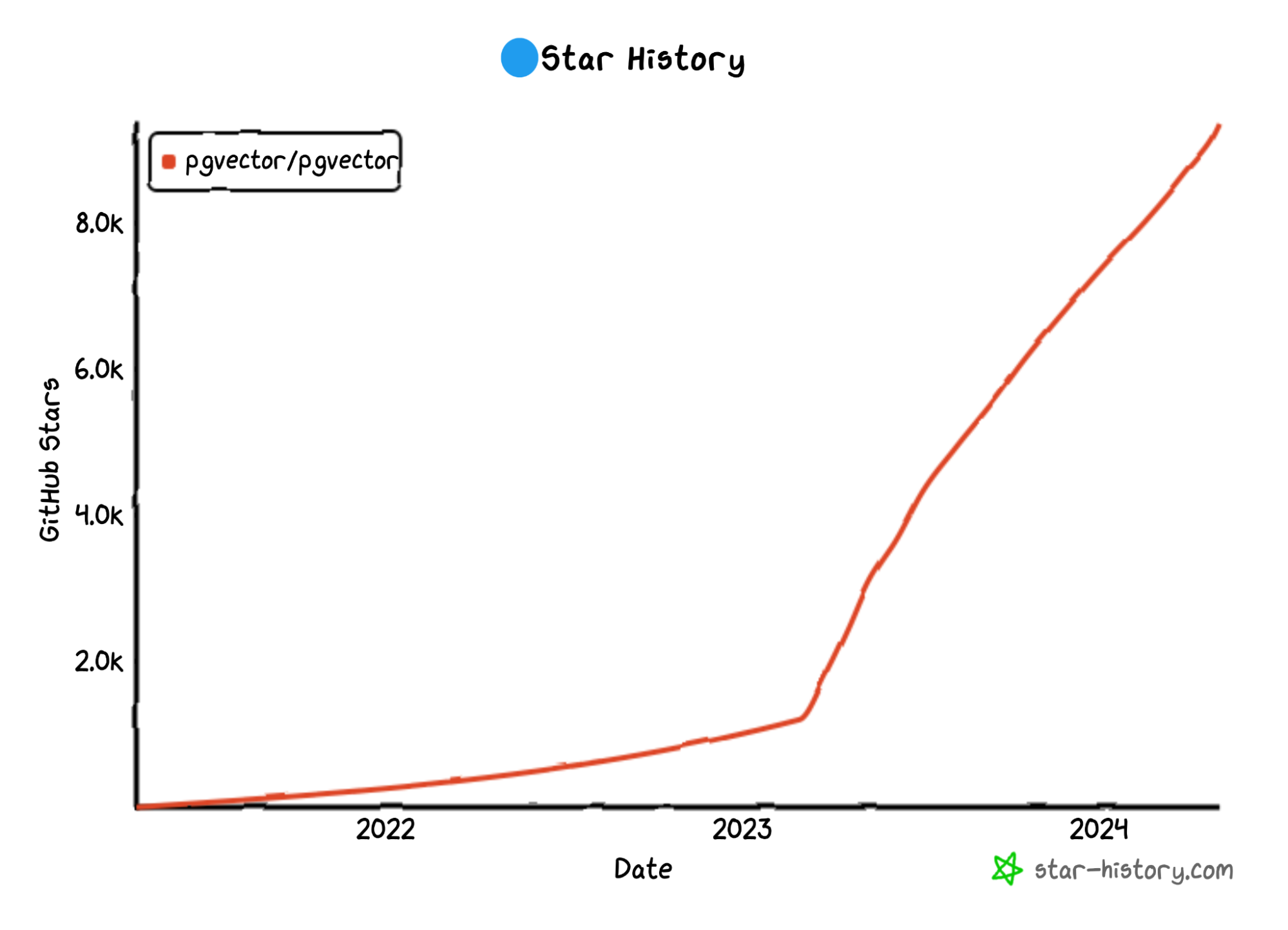
Pure vector databases, such as Pinecone, had to acknowledge the existence of pgvector and start publishing competitive materials. I consider this a good sign for Postgres.
Why a good sign? Well, as my fellow Postgres community member Rob Treat put it: “First they ignore you. Then they laugh at you. Then they create benchmarketing. Then you win!”
So, how is this related to the topic of distributed Postgres?
The more often Postgres is used for gen AI workloads, the more frequently you’ll hear (from vendors behind other solutions) that gen AI apps built on Postgres will have:
- Scalability and performance issues
- Challenges with data privacy
- A hard time with high availability
If you do encounter the listed issues, you shouldn’t immediately dump Postgres and migrate to a more scalable, highly available, secure vector database, at least not until you’ve tried running Postgres in a distributed configuration!
Let’s discuss when and how you can use distributed Postgres for gen AI workloads.
What is Distributed Postgres?
Postgres was designed for single-server deployments. This means that a single primary instance stores a consistent copy of all application data and handles both read and write requests.
How do you make a single-server database distributed? You tap into the Postgres ecosystem!
Within the Postgres ecosystem, people usually assume one of the following of distributed Postgres:
- Multiple standalone PostgreSQL instances with multi-master asynchronous replication and conflict resolution (like. EDB Postgres Distributed)
- Sharded Postgres with a coordinator (like CitusData)
- Shared-nothing distributed Postgres (like YugabyteDB)
Check out the following guide for more information on each deployment option. As for this article, let’s examine when and how distributed Postgres can be used for your gen AI workloads.
Problem #1: Embeddings Use All Available Memory and Storage Space
If you have ever used an embedding model that translates text, images, or other types of data into a vectorized representation, you might have noticed that the generated embeddings are quite large arrays of floating point numbers.
For instance, you might use an OpenAI embedding model that translates a text value into a 1536-dimensional array of floating point numbers. Given that each item in the array is a 4-byte floating point number, the size of a single embedding is approximately 6KB—a substantial amount of data.
Now, if you have 10 million records, you would need to allocate approximately 57 Gigabytes of storage and memory just for those embeddings. Additionally, you need to consider the space taken by indexes (such as HNSW, IVFFlat, etc.), which many of you will create to expedite the vector similarity search.
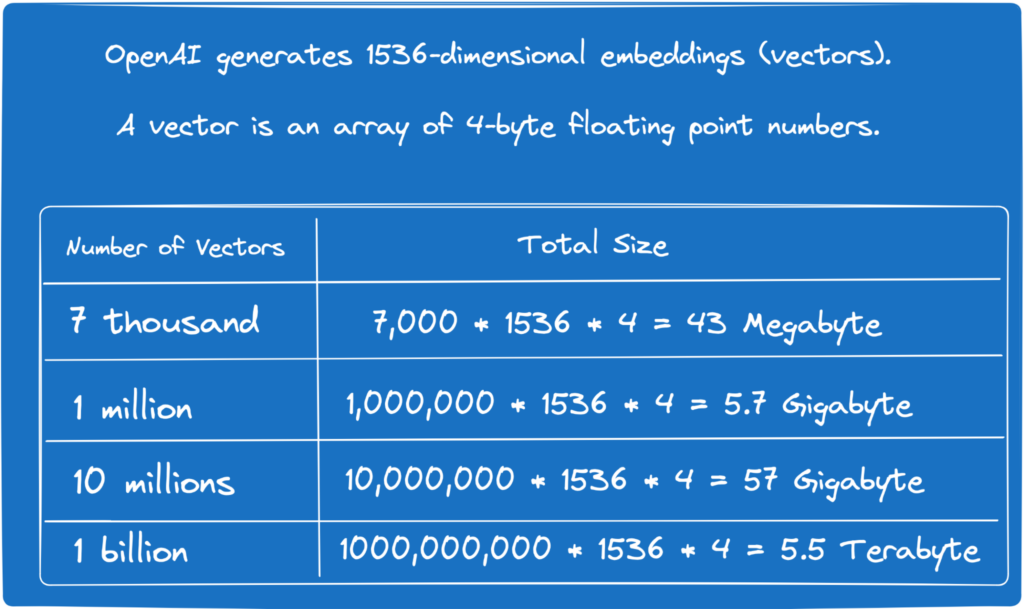
Overall, the greater the number of embeddings, the more memory and storage space Postgres will require to store and manage them efficiently.
You can reduce storage and memory usage by switching to an embedding model that generates vectors with fewer dimensions, or by using quantization techniques. But, suppose I need those 1536-dimensional vectors and I don’t want to apply any quantization techniques. In that case, if the number of embeddings continues to increase, I could outgrow the memory and storage capacity of my database instance.
This is an obvious area where you can tap into distributed Postgres. For example, by running sharded (CitusData) or shared-nothing (YugabyteDB) versions of PostgreSQL, you can allow the database to distribute your embeddings evenly across an entire cluster of nodes.
Using this approach, you are no longer limited by the memory and storage capacities of a single node. If your application continues to generate more embeddings, you can always scale out the cluster by adding more nodes.
Problem #2: Similarity Search is Compute-Intensive Operation
This problem is closely related to the previous one, but with a focus on CPU and GPU utilization.
When we say “just perform the vector similarity search over the embeddings stored in our database,” the task sounds straightforward and obvious to us, humans. However, from the database server’s perspective, it’s a compute-intensive operation requiring significant CPU cycles.
For instance, here is the formula used to calculate the cosine similarity between two vectors. We typically use cosine similarity to find the most relevant data for a given user prompt.

Imagine A as a vector or embedding of a newly provided user prompt, and B as a vector or embedding of your unique business data stored in Postgres. If you’re in healthcare, B could be a vectorized representation of a medication and treatment of a specific disease.
To find the most relevant treatment (vectors B) for the provided user symptoms (vector A), the database must calculate the dot product and magnitude for each combination of A and B. This process is repeated for every dimension (the ‘i’ in the formula) in the compared embeddings. If your database contains a million 1536-dimensional vectors (treatments and medications), Postgres must perform a million calculations over these multi-dimensional vectors for each user prompt.
Approximate nearest neighbor search (ANN) allows us to reduce CPU and GPU usage by creating specialized indexes for vectorized data. However, with ANN, you sacrifice some accuracy; you might not always receive the most relevant treatments or medications since the database does not compare all the vectors. Additionally, these indexes come with a cost: they take time to build and maintain, and they require dedicated memory and storage.
If you don’t want to be bound by the CPU and GPU resources of a single database server, you can consider using a distributed version of Postgres. Whenever compute resources become a bottleneck, you can scale your database cluster out and up by adding new nodes. Once a new node joins the cluster, a distributed database like YugabyteDB will automatically rebalance the embeddings and immediately begin utilizing the new node’s resources.
Problem #3: Data Privacy
Whenever I demonstrate what a combination of LLM and Postgres can achieve, developers are inspired. They immediately try to match and apply these AI capabilities to the apps they work on.
However, there is always a follow-up question related to data privacy: ‘How can I leverage an LLM and embedding model without compromising data privacy?’ The answer is twofold.
First, if you don’t trust a particular LLM or embedding model provider, you can choose to use private or open-source models. For instance, use Mistral, LLaMA, or other models from Hugging Face that you can install and run from your own data centers or cloud environments.
Second, some applications need to comply with data residency requirements to ensure that all data used or generated by the private LLM and embedding model never leaves a specific location (data center, cloud region, or zone).
In this case, you can run several standalone Postgres instances, each working with data from a specific location, and allow the application layer to orchestrate access across multiple database servers.
Another option is to use the geo-partitioning capabilities of distributed Postgres deployments, which automate data distribution and access across multiple locations, simplifying application logic.
Let’s continue with the healthcare use case to see how geo-partitioning allows us to distribute information about medications and treatments across locations required by data regulators. Here I’ve used YugabyteDB as an example of a distributed Postgres deployment.
Imagine three hospitals, one in San Francisco, and the others in Chicago and New York. We deploy a single distributed YugabyteDB cluster, with several nodes in regions (or private data centers) near each hospital’s location.
To comply with data privacy and regulatory requirements, we must ensure that the medical data from these hospitals never leaves their respective data centers.
With geo-partitioning, we can achieve this as follows:
- Create Postgres tablespaces mapping them to cloud regions in the US West, Central and East. There is at least one YugabyteDB node in every region.
CREATE TABLESPACE usa_east_ts WITH ( replica_placement = '{"num_replicas": 1, "placement_blocks": [{"cloud":"gcp","region":"us-east4","zone":"us-east4-a","min_num_replicas":1}]}' ); CREATE TABLESPACE usa_central_ts WITH ( replica_placement = '{"num_replicas": 1, "placement_blocks": [{"cloud":"gcp","region":"us-central1","zone":"us-central1-a","min_num_replicas":1}]}' ); CREATE TABLESPACE usa_west_ts WITH ( replica_placement = '{"num_replicas": 1, "placement_blocks": [{"cloud":"gcp","region":"us-west1","zone":"us-west1-a","min_num_replicas":1}]}' ); - Create the treatment table that keeps information about treatments and medications. Each treatment has an associated multi-dimensional vector – description_vector – that is generated for the treatment’s description with an embedding model. Finally, the table is partitioned by the hospital_location column.
CREATE TABLE treatment ( id int, name text, description text, description_vector vector(1536), hospital_location text NOT NULL ) PARTITION BY LIST (hospital_location); - The partitions’ definition is as follows. For instance, the data of the hospital3 which is in San Francisco will be automatically mapped to the usa_west_ts whose data belongs to the database nodes in the US West.
CREATE TABLE treatments_hospital1 PARTITION OF treatment(id, name, description, description_vector, PRIMARY KEY (id, hospital_location)) FOR VALUES IN ('New York') TABLESPACE usa_east_ts; CREATE TABLE treatments_hospital2 PARTITION OF treatment(id, name, description, description_vector, PRIMARY KEY (id, hospital_location)) FOR VALUES IN ('Chicago') TABLESPACE usa_central_ts; CREATE TABLE treatments_hospital3 PARTITION OF treatment(id, name, description, description_vector, PRIMARY KEY (id, hospital_location)) FOR VALUES IN ('San Francisco') TABLESPACE usa_west_ts;
Once you’ve deployed a geo-partitioned database cluster and defined the required tablespaces with partitions, let the application connect to it and allow the LLM to access the data. For instance, the LLM can query the treatment table directly using:
select name, description from treatment where 1 - (description_vector ⇔ $user_prompt_vector) > 0.8 and hospital_location = $location
The distributed Postgres database will automatically route the request to the node that stores data for the specified hospital_location. The same applies to INSERTs and UPDATEs; changes to the treatment table will always be stored in the partition->tablespace->nodes belonging to that hospital’s location. These changes will never be replicated to other locations.
Problem #4: High Availability
Although Postgres was designed to function in a single-server configuration, this doesn’t mean it can’t be run in a highly available setup. Depending on your desired recovery point objective (RPO) and recovery time objective (RTO), there are several options.
So, how is distributed Postgres useful? With distributed PostgreSQL, your gen AI apps can remain operational even during zone, data center, or regional outages.
For instance, with YugabyteDB, you simply deploy a multi-node distributed Postgres cluster and let the nodes handle fault tolerance and high availability. The nodes communicate directly. If one node fails, the others will detect the outage. Since the remaining nodes have redundant, consistent copies of data, they can immediately start processing application requests that were previously sent to the failed node. YugabyteDB provides RPO = 0 (no data loss) and RTO within the range of 3-15 seconds (depending on the database and TCP/IP configuration defaults).
In this way, you can build gen AI apps and autonomous agents that never fail, even during region-level incidents and other catastrophic events.
Summary
Thanks to extensions like pgvector, PostgreSQL has evolved beyond traditional relational database use cases and is now a strong contender for generative AI applications. However, working with embeddings might pose some challenges, including significant memory and storage consumption, compute-intensive similarity searches, data privacy concerns, and the need for high availability.
Distributed PostgreSQL deployments offer scalability, load balancing, and geo-partitioning, ensuring data residency compliance and uninterrupted operations. By leveraging these distributed systems, you can build scalable gen AI applications that scale and never fail.


