What Makes the Architecture of Geo-Distributed Apps Different and Better
November 10, 2022
In an earlier blog, we broke down the definition of geo-distributed apps. So now let’s compare and contrast geo-distributed apps with what I call regular apps (those deployed within a single data center or availability zone). A good way to make this comparison to understand the differences and find the similarities is to drill down into the architecture.
Geo-Distributed App Architecture
So what are a geo-distributed app’s main building blocks? Its architecture is fundamentally the same as that of regular applications. It has data and application layers, just like the standard app. It might have a dedicated API layer and consist of several micro-services. It may also use a load balancer to better handle user traffic, and it may rely on some middleware. The list goes on and on!
So, what are the differences? Well, the answer to that lies in the definition of geo-distributed apps.
A geo-distributed app is an app that spans multiple geographic locations for high availability, resiliency, compliance, and performance. So a geo-distributed application’s architecture must support high availability, resilience, compliance, and performance.
So now, let’s review those characteristics in relation to the load balancer, application layer, and data layer.
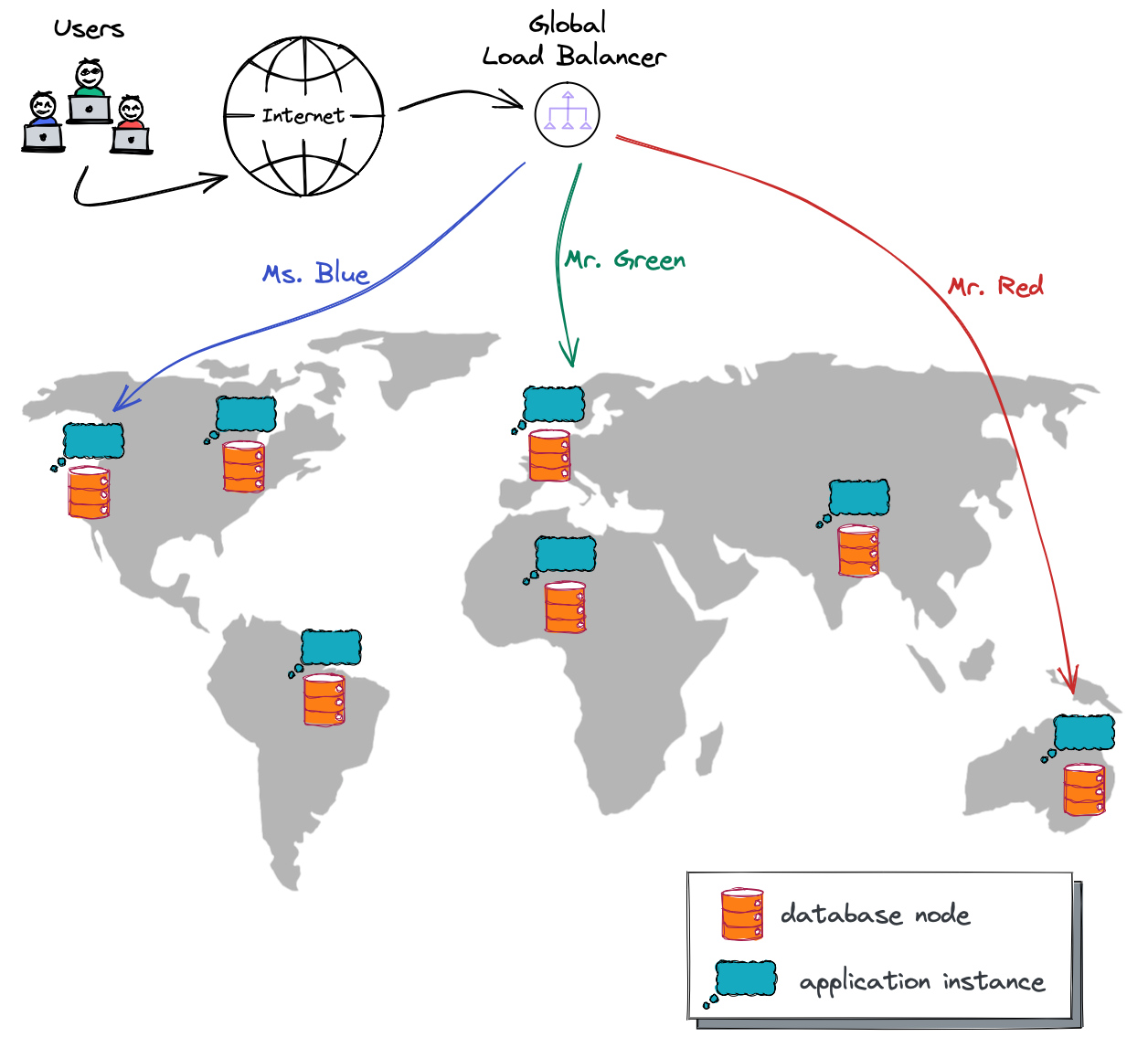
Users of a geo-distributed app live across the globe. They could live just on a single continent or country (or a large part of it) or be as geographically dispersed as the users in the sample map above. If you look at the map, you will see three users named Ms. Blue, Mr. Green, and Mr. Red.
These users launch the application (usually by opening up their laptops, launching a browser, connecting to the internet, and typing the app in the browser window). They expect to see the app’s page within a second (if not sooner). If your app does not load within three seconds, a significant portion (up to 40%) of your users will abandon your app. So, how does a geo-distributed app handle this?
Global Load Balancer
The geo-distributed app in our illustration relies on a global load balancer. It receives requests and then, based on the user’s location, forwards the requests to the application instance closest to the user.
The picture shows that Ms. Blue’s request is routed to an application instance running in the western US, Mr. Green’s to an instance in Europe, and Mr. Red’s to an instance in Australia. Naturally, the closer the application instance is to the user, the faster the app can process their request. This is how the global load balancer contributes to the performance characteristic of this geo-distributed app.
But how does the load balancer help with high availability and reliability? Imagine that the US West region becomes unavailable, and the load balancer can no longer forward Ms. Blue’s requests there. The balancer doesn’t shut down; it doesn’t panic. Instead, it figures out the next closest location for Ms. Blue’s request (which, according to the map above, should be US East. It forwards her traffic there, automatically.
Geo-Distributed Application Layer
The application that receives the user request can be a monolith, or it can be split into several microservices. It does not matter for this example. What is important is that multiple instances of the app are running across the globe. This is done to ensure that the geo-distributed app can survive any type of cloud outage. This makes the application layer reliable and highly available. On top of that, with multiple instances, the geo-distributed app can serve user requests at low latency, regardless of the user’s location. This is what makes the app layer performant.
A Horizontally Scalable Data Layer
Finally, the application instance selected to serve a user request needs to read data from or write it to the data layer (i.e. the database). With geo-distributed apps, you usually use a distributed database that can scale horizontally. This is why the map above has multiple database nodes scattered worldwide.
Distributed databases improve the reliability and availability of geo-distributed apps. These databases store redundant copies of data, allowing the app to remain operational during an outage. If a database node becomes unavailable due to a cloud incident, live and healthy nodes can handle the application requests.
From a performance standpoint, the closer the user’s data is to the application instance, the better. You don’t want Sydney’s application instance that is handling user requests from Mr. Red to have to, in turn, make a request to a database node in Asia or South America. Absolutely you don’t. With distributed databases, arranging data close to the user’s location and the application is possible to minimize latencies.
Just as importantly, placing users’ data in specific locations helps geo-distributed apps comply with data residency requirements. GDPR is a serious requirement. So, when the global load balancer forwards Mr. Green’s requests to an app instance in Europe, the instance is required to read personal data from and write it to the database node(s) deployed within the European Union.
That’s it. As you can see, the architecture of a geo-distributed app comes with the same components used in regular applications—including a data layer, application layer, and load balancer. The only difference is that in the case of geo-distributed apps, all of those components have to function across several distant locations.


