Understand the Differences Between NewSQL and Distributed SQL
November 7, 2022
Have you been told that NewSQL and distributed SQL databases are the same thing? It is a common misconception. Even though they both represent an evolution in the transactional database, there are significant differences in their capabilities and how evolved they are. This greatly impacts the value they bring to an organization.
NewSQL first emerged as a term over 11 years ago. It represented a new set of solutions that sought to address the need for a distributed database by bolting on a few features to the existing, monolithic database architectures that are still used by many enterprises.
Distributed SQL approached the same problem (and a few more) differently. It introduces a new architecture built from the ground up specifically to meet the cloud native needs of today’s companies. The adoption of distributed SQL databases is accelerating because companies face new situations and challenges that cannot be easily addressed with NoSQL, SQL, or the extra extensions of NewSQL databases. But before we address those challenges, let’s look at the features most IT organizations focus on when evaluating a new database.
SQL, NoSQL, NewSQL, and Distributed SQL Database Feature Comparisons
As you can see in the table below, NewSQL is fundamentally the same as SQL. The only difference is scalability (vertical vs. horizontal), which was the main challenge that the developers of NewSQL focused on.
Understand what is distributed SQL and how it combines SQL reliability with horizontal scalability.
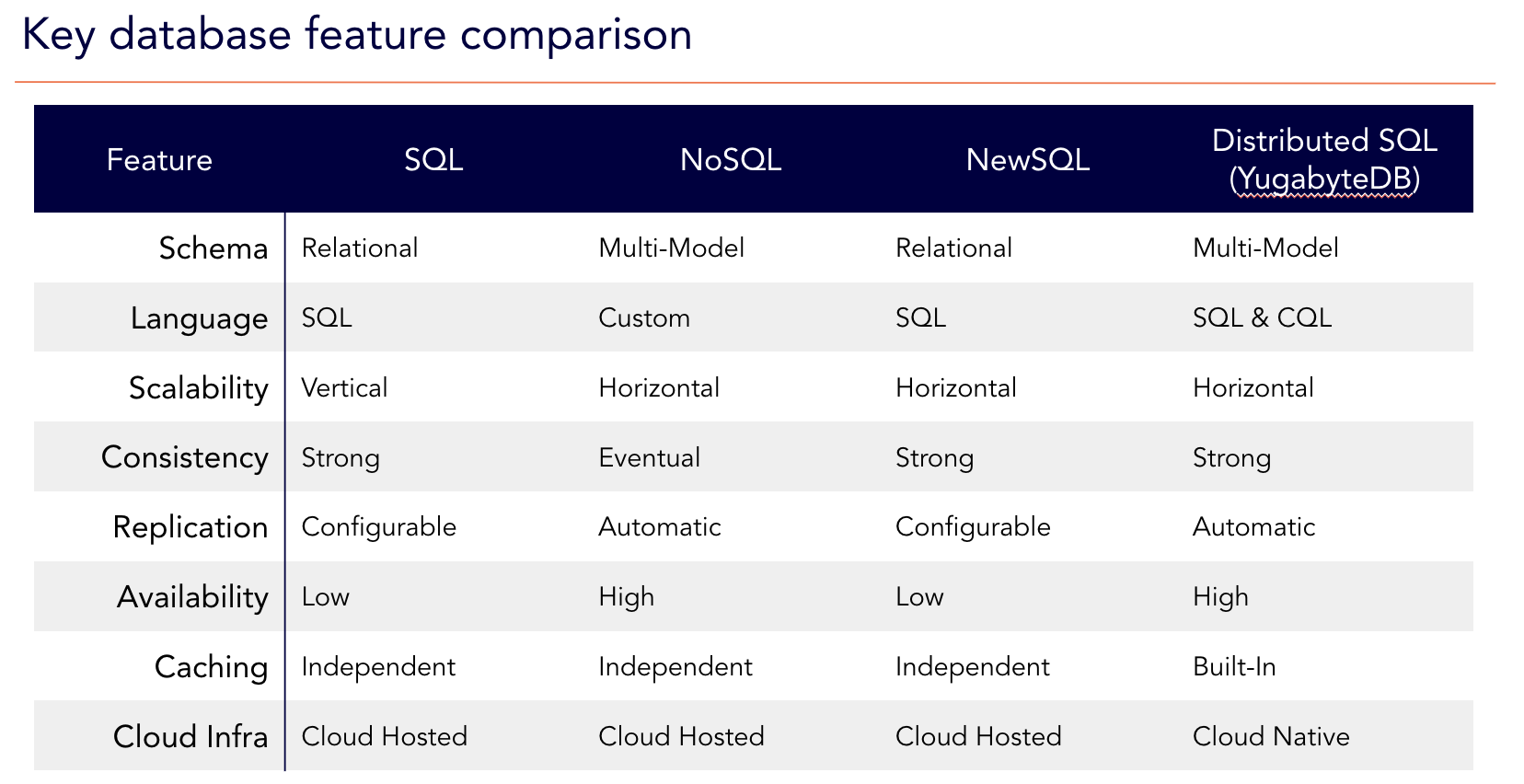
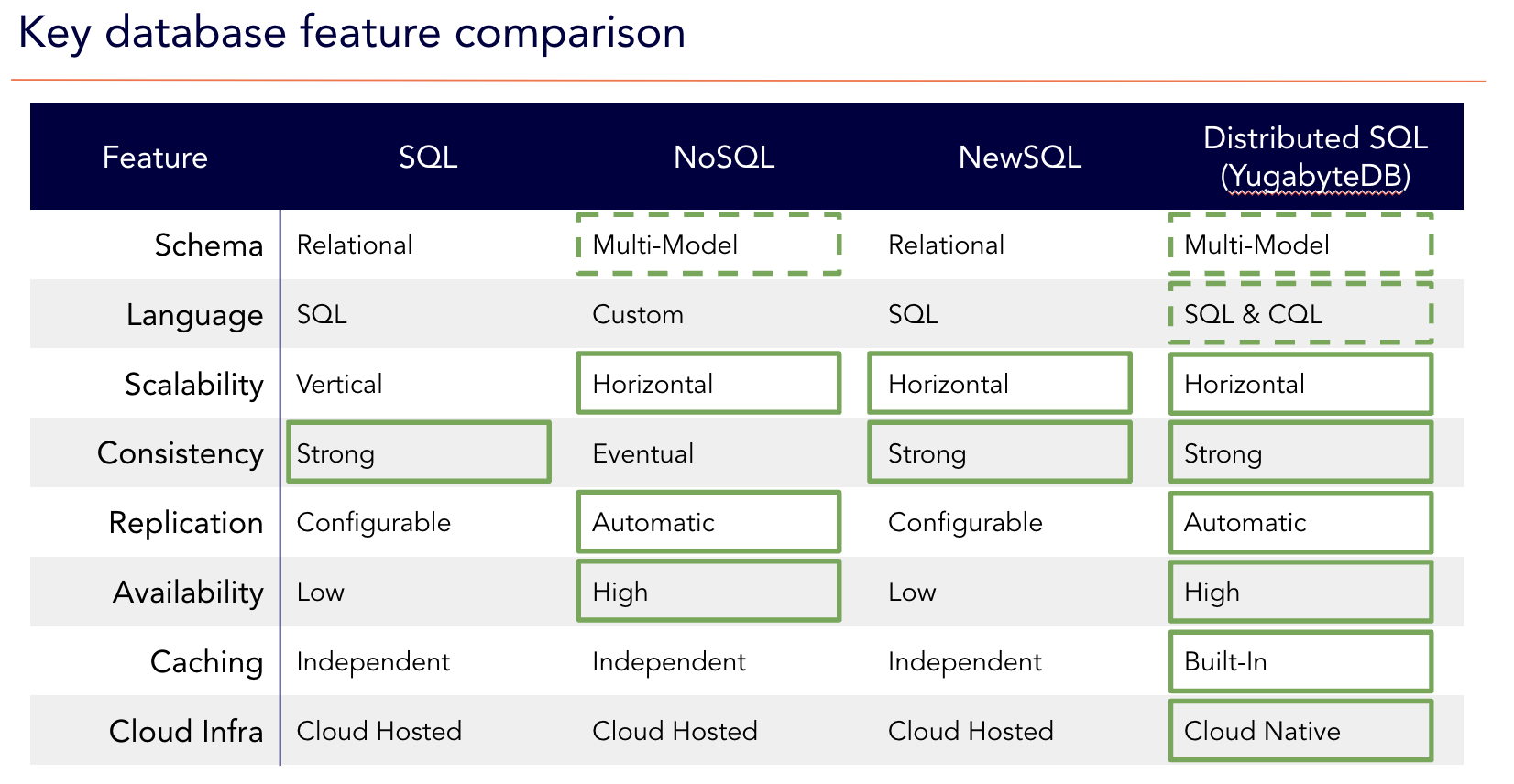
Note: The features listed in the distributed SQL column are for the YugabyteDB database. For example, Yugabyte’s distributed SQL database has a multi-model approach thanks to a flexible query layer. So it can support both Postgres (YSQL) and Cassandra (YCQL) equivalent APIs, making it easy to support SQL and NoSQL applications.
Once we highlight the “best” features in each row (i.e. solid boxes), and the more flexible options (i.e. dashed boxes) it is clear that distributed SQL combines the best of SQL and NoSQL and supports the needs of today’s cloud native applications.
Distributed SQL vs. NewSQL: 5 Times Distributed SQL May Be the Best Choice
So now, let’s move away from the architectural differences between distributed SQL, NoSQL, and NewSQL and focus on the “why.” The answer to the question, “Why should I use distributed SQL?” can be found in five challenges that companies face as they work to align their data layer to their cloud, application, and database modernization initiatives.
- Transactional application growth
Applications are designed to be used (and hopefully become popular), but we never know if or when exponential growth will happen. It could happen overnight, or it could take months. However, there is one constant—at some point, the application will outgrow its server. Success demands scalability.Application growth is difficult to manage on legacy, monolithic databases that run on a single write node backed by increasingly-specialized, high-cost hardware. As your app usage increases, you’ll face painful vertical hardware scaling efforts to support increased write volumes. You’ll need to find/buy/deploy bigger machines with more compute, more memory, and more disk space. Then you will have to manually migrate the database instance to this new machine.Horizontal scalability is built into the DNA of distributed SQL. It’s a core feature. Operations teams can effortlessly scale writes, maintain strongly consistent reads, and add storage and connections by simply adding nodes to their cluster. No specialized hardware is needed. The database recognizes the new node and automatically rebalances the data load to best use all available resources.
Even better, this scalability has no impact on performance. Because data distribution is at the architecture’s core, you can maintain low latency and high performance levels.
So if your server cannot keep up with application usage and you don’t want to rewrite or update the app, now may be a great time to consider a distributed SQL database.
- Always-On Business
Today, you have to be always on and always available. Availability and resiliency are not nice-to-haves but must-haves. Outages happen. It’s impossible to design a cloud service that can avoid all calamities, and downtime can have a massive impact on your business.“Two-thirds of outage incidents were more than $100,000, while the rest of the reported outages cost $1 million or more.” — 2020 Global Data Survey of Data Center and IT Managers
So in today’s cloud-centric world, how can you survive an outage with zero impact to your customers and operations team? Almost all databases use replication to ensure they remain highly available even during outages. But many legacy SQL database systems still rely on older replication models (asynchronous replication) and manual processes to cut over to standby configurations when the active system fails. Hands on keyboards are needed to bring those standby systems up and reconcile all final transactions to ensure complete data consistency. NewSQL, being based on the same underlying architecture, has the same limitations and issues.
With distributed SQL databases, like YugabyteDB, critical services remain available during node, zone, region, and data center failures. These databases maintain continuous availability during infrastructure failures; they heal themselves. They keep going by re-replicating data automatically, enabling fast failover. Additionally, there is zero downtime during maintenance tasks such as software upgrades, security patching, and distributed backups.
So if you want the peace of mind that comes with knowing you’ll survive almost any outage while maintaining high performance and low latency levels, all with zero impact on your operations team, now may be the time to consider a distributed SQL database.
- App Mobility
You probably use several cloud platforms as you digitally transform, innovate, and modernize. You are not alone. The shift to the cloud has accelerated over the past few years, partly due to COVID-19 and the demand for hybrid work environments. It is estimated that 82% of all companies have embraced a multi-cloud strategy. With multiple clouds, you need the freedom to move applications into the environment that makes the most sense—either from a cost or performance perspective. Here’s where it gets tricky. Apps can be easily moved, but the data becomes a significant anchor if it’s tied to a specific database.A distributed SQL database can significantly help with this. Being cloud and platform agnostic, it can run in many different environments—across clouds, virtual machines (VMs), containers, and bare metal. Because it acts as a single, unified data store across environments, the data layer appears as a simple, single logical database to the application.So if you want the freedom to move applications across clouds or other environments, now may be the ideal time to consider a distributed SQL database.
- Next-gen Edge Computing.
Edge computing is a hot area. Data enters your organization from many different places—smart devices, connected vehicles, intelligent POS systems, and building/machine sensors—all operating in real time. Many operate from remote, hostile, or nontraditional locations. For many companies the key to reducing response times and network costs is to have a:- Powerful edge computing architecture that distributes compute power and puts data storage closer to where the data reside
- Set of new stateful edge applications that exploit smart devices, mobile phones, and network gateways to perform tasks and provide services locally on behalf of the cloud.
However, combining the vision of edge with legacy databases is not easy. Early forays into edge computing simply collected data and moved it back to the central data center. Here the monolithic database stored it and then fed it into a data warehouse for analysis and insights.
As the need to store and process data closer to the source of the data increased, having to stand up siloed databases at every edge location (not to mention managing the governance and security policies for each) became an operational nightmare.
Here a distributed SQL database has the advantage over legacy solutions due to its horizontal scalability, continuous availability, and multi-cloud deployment options. Additionally, YugabyteDB offers a level of operational simplicity with its fully managed DBaaS offering so you can manage your database from one central location instead of multiple dispersed locations.
So if you need to deliver stateful apps at the edge for fast responses, now may be the best time to consider a distributed SQL database.
- Microservices and Kubernetes
Kubernetes is the de facto platform of choice for orchestrating containerized applications. Many companies are actively migrating their applications to Kubernetes to help them be more flexible, move faster, and provide choice in terms of underlying infrastructure. Most, however, have still not containerized their data layer. And deploying a stateful application, like a database, on Kubernetes is not always easy.By leaving your data layer where it is, you’re operating with a big hole in your IT stack and putting a strain on resources. You have a flexible cloud infrastructure at the bottom and a new, proven approach to app development at the top. It’s your data layer that’s holding you back.A SQL database is one of the most complex workloads to run in Kubernetes. Given the changeable, agile nature of Kubernetes pods, they require an agile database that can handle and recover from all those changes. This is difficult with a monolithic database.
In contrast, a distributed SQL database has many Kubernetes-friendly features and can solve the challenges legacy databases struggle with. It has the self-healing and self-service capabilities that are key to handling the dynamic nature of a Kubernetes environment. It remains up and running even if a pod, node, or underlying infrastructure fails. The database cluster can detect the failure, handle it, and recover without any data loss of data or access by the application. a or access by the application.
In addition to being a distributed SQL database, YugabyteDB is 100% open source with solid community support. It aligns with the key requirements companies are looking for. It’s enterprise-ready, open source, built on open standards, and architected for cloud native applications.
>>Understanding how YugabyteDB Runs on Kubernetes>>
Discover More
- Distributed SQL vs. NewSQL
- Building a Data-Centric Business Ready for Any Future—Wells Fargo Fireside Chat with Nathaniel Dremel
- Expanding Modernization from Applications to Databases—Charles Schwab Fireside Chat with David Loomis
- YugabyteDB customer success stories
- Wells Fargo Executive Summit Chat: Saul Van Beurden and Bill Cook
- Evaluating NewSQL Databases Using Distributed SQL Criteria


