Java Development: How Applications Litter Beyond the Heap
July 13, 2022
In Java development, garbage collection is a routine task. Applications generate garbage all the time. And that garbage is meticulously cleaned out by CMS, G1, Azul C4 and other types of collectors. Basically, our applications are born to bring value to this world, but nothing is perfect—including our applications that leave litter in the Java heap.
However, the story doesn’t end with the Java heap. In fact, it only starts there. Let’s take the example of a basic Java application that uses a relational database—such as PostgreSQL—and solid state drives (SSDs) as a storage device. From here, we’ll explore how our applications generate garbage beyond the boundaries of the Java heap.
Filling up PostgreSQL with dead tuples
In Java development, when your application executes a DELETE or UPDATE statement against a PostgreSQL database, a deleted record is not removed immediately nor an existing record updated in its place. Instead, the deleted record is marked as a dead tuple and will remain in storage. The updated record is, in fact, a brand new record. PostgreSQL inserts it by copying the previous version of the record and updating requested columns. The previous version of that updated record gets deleted and, as with the DELETE operation, marked as a dead tuple.
There is a good reason why the database engine keeps old versions of the deleted and updated records in its storage. For starters, your application can run a bunch of transactions against PostgreSQL in parallel. Some of those transactions do start earlier than the others. But if a transaction deletes a record that still might be of interest to a few transactions started earlier, then the record needs to remain in the database (at least until the point in time when all earlier started transactions finish). This is how PostgreSQL implements MVCC (multi-version concurrency protocol).
Vacuuming
It’s clear that PostgreSQL can’t and doesn’t want to keep the dead tuples forever. This is why the database has its own garbage collection process called vacuuming. There are two types of VACUUM – the plain and full one. The plain VACUUM works in parallel with your application workloads and doesn’t block your queries. This type of vacuuming marks the space occupied by dead tuples as free. It also makes it available for new data that your application will add to the same table later.
The plain VACUUM doesn’t return the space to the operating system so that it can be reused by other tables or third-party applications (except in some corner cases when a page includes only dead tuples and the page is at the end of a table).
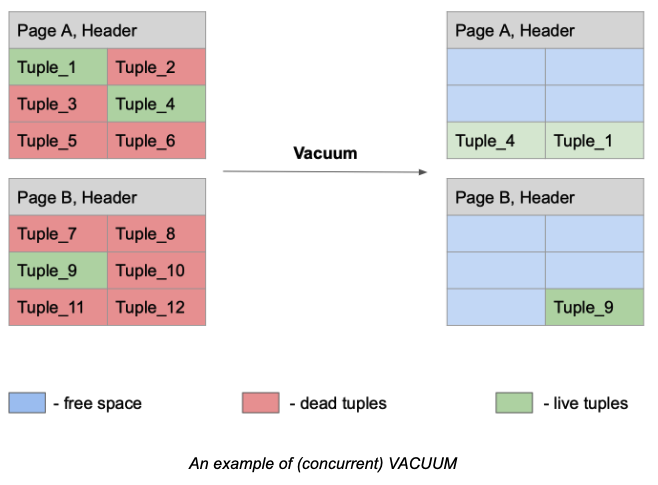
By contrast, the full VACUUM does reclaim the free space to the operating system, but it blocks application workloads. You can think of it as Java’s “stop-the-world” garbage collection pause. It’s only in PostgreSQL that such a pause can last for hours (or days). Thus, database admins try their best to prevent the full VACUUM from happening at all.
Now let’s stop here and move down to the next level: SSDs.
Generating stale data in SSDs
If you thought garbage collection is just for software then… surprise, surprise! Some hardware devices also need to perform garbage collection routines. SSDs do garbage collection all the time!
In Java development, whenever your application deletes or updates any data on disk – through PostgreSQL as discussed above or directly via the Java File API – then the application generates garbage on SSDs.
An SSD stores data in pages (usually between 4KB and 16KB in size) and groups them in blocks. While your data can be written or read at the page level, the stale (deleted) data can be erased only at the block level. The erasure requires more voltage than for reading/writing operations. It’s also hard to target that voltage at the page level without impacting the adjacent cells.
So, if your Java application updates a file, then an updated segment will be written to an empty page in a different block. The segment with the old data will be marked as stale and garbage collected later. First, a garbage collector in SSDs traverses blocks of pages with stale data and moves good data to other blocks (similar to the compaction phase in Java’s G1 collector). Second, the collector erases blocks that have only stale data left and makes those blocks available to future data.
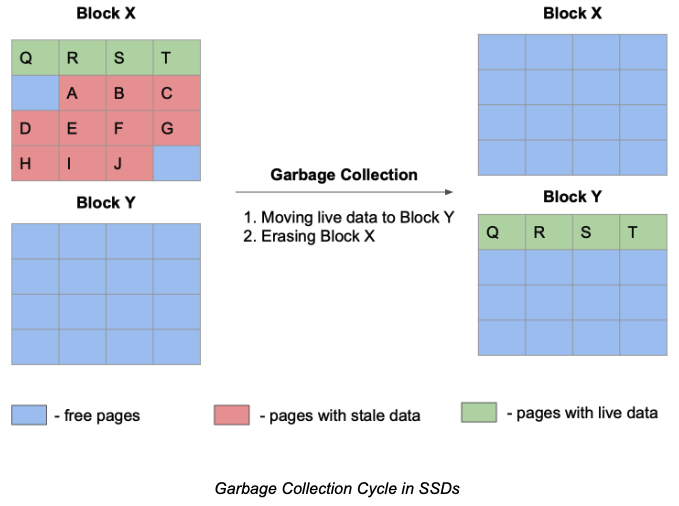
Curious how SSD manufacturers prevent or minimize the number of “stop-the-world” pauses? There is a concept of SSD over-provisioning. This is when each device comes with an extra space that is unavailable to your applications. That space is a sort of a safe buffer that allows applications to continue writing or modifying data while the garbage collector erases stale data concurrently.
Conclusion
So, next time someone asks you to explain the internals of garbage collection in Java development, go ahead and surprise them by expanding the topic to include databases and hardware.
On a serious note, garbage collection is a widespread technique that is used far beyond the Java ecosystem. If implemented properly, garbage collection can simplify the architecture of software and hardware without performance impact. Java, PostgreSQL, and SSDs are all good examples of products that successfully take advantage of garbage collection and still remain among the top products in their categories.
Got questions? Join the YugabyteDB community Slack channel for a deeper discussion with nearly 6,000 developers, engineers, and architects.


