Implementing Multi-Agent AI with YugabyteDB Vector
October 6, 2025
In today’s digital payments world with UPI (Unified Payment Interface), instant bank transfers, and round-the-clock transactions, fraudsters move faster than ever. Traditional fraud detection systems, which rely on fixed rules, struggle to keep pace with ever-changing tactics.
Banks and fintech companies are grappling with tough challenges, including:
- Fake identities and devices
- Synthetic fraud
- Rapid-fire fraud
- Regulatory hurdles
To combat this, BFSI (Banking, Financial Services, and Insurance), particularly banks and fintechs, need smarter, real-time tools to identify and avoid these threats, while keeping their platforms online and trustworthy.
Traditional RAG (Retrieval Augmented Generation) helps by bringing context from past fraud cases, policies, and transaction history. But a single agent is not enough. Fraud detection is multi-faceted and requires multi-agent collaboration, each with specialized expertise.
This blog examines the growing challenges of fraud in today’s UPI and digital payments ecosystem, highlights the key risks banks and fintechs face, and explains how Retrieval-Augmented Generation can provide valuable context from past cases and policies. It also explores the benefits of multi-agent collaboration using YugabyteDB Vector’s A2A (Agent-to-Agent) Orchestration, which involves specialized agents working together to deliver smarter, real-time fraud detection.
Why YugabyteDB Vector Is Essential for Multi-Agent Fraud AI
Most vector databases were built for single-node-based workloads. BFSI needs scale, uptime, and compliance.
YugabyteDB with pgvector provides:
- A distributed, scale-out vector search: embeddings for billions of transactions across clusters
- Hybrid SQL and ANN (Approximate Nearest Neighbour): combine semantic similarity with structured constraints (WHERE merchant_category = ‘shopping’ AND amount > 5000)
- Regulator-ready foundations: ACID (atomicity, consistency, isolation, and durability), audit logs, high availability with zero downtime
- Parallelism for agents: Different agents, like Retriever, FraudDetection, and Compliance, all query the same resilient cluster
Core AI Components and Their Benefits
The AI components below highlight that fraud detection in banking isn’t powered by just one model. Instead, it’s a multi-layered system where each model or agent has a special role, and together they create a stronger, more reliable defense against fraud.
YugabyteDB Vector (pgvector + Distributed SQL)
- Role: Acts as the scalable backbone for storing structured data, embeddings, and transaction history.
- Benefit: Supports hybrid queries (SQL + vector search) across billions of transactions.
Why it matters: Delivers resilient, globally distributed, real-time analytics that power the multi-agent fraud pipeline end-to-end.
Embedding Model (e.g. OpenAI text-embedding-3-small / MiniLM / BERT)
- Role: Generates dense vector embeddings for transactions, policies, and advisories.
- Benefit: Enables semantic search and retrieval in YugabyteDB Vector (pgvector + HNSW).
Why it matters: Detects fraud patterns beyond keywords (e.g., linking “donation scams” with “charity fraud”).
Writer Agent (e.g. Claude 3.5 Sonnet / GPT-4o)
- Role: Creates concise, human-readable fraud narratives, reason codes, and ops logs.
- Benefit: Provides analysts with clarity instead of raw or cryptic scores.
Why it matters: Speeds up decision-making and improves fraud review accuracy.
ComplianceBot (e.g. Claude 3.5 Sonnet / GPT-4o with system tuning)
- Role: Validates draft reports against RBI, AML, and KYC guidelines.
- Benefit: Ensures reports are audit-ready and compliant with regulatory requirements.
Why it matters: Reduces audit exceptions and translates technical findings into regulator-approved language.
FraudDetectionBot (Rules + Machine Learning (ML ) Model + Optional LLM)
- Role: Detects anomalies like velocity spikes, device/IP mismatches.
- Benefit: Maintains high precision and low latency (<200ms) scoring.
Why it matters: Enables real-time fraud detection at production scale.
Three High-Impact Multi-Agent Use Cases
- Real-Time Card and UPI Payment Checks
To keep your money safe and maintain trust, a multi-agent system decides whether to approve or decline card and UPI payments in under 150 milliseconds, with clear reasoning. Here’s how it works:- The first agent pulls up your past transactions and device details
- The second spots red flags like sudden spending spikes or unusual locations
- The third agent scores the risk
- A fourth logs the decision for audits
- The final one ensures everything follows RBI and network rules
This setup identifies risks like multiple payments in minutes, new devices, or high-risk merchants. Using smart data searches, it detects more fraud, avoids blocking valid payments, keeps things fast, and maintains clear records.
- Stopping Account Takeovers in Mobile Banking
To protect your mobile banking or wallet account, the multi-agent system detects hackers trying to take over your account through stolen passwords, SIM card swaps, or session hijacks in under 30 seconds.- One agent gathers your login and device data
- Another checks for risks like a new device or odd login locations
- A third scores the threat
- Another logs the details
- The final agent ensures compliance with regulations
The system monitors for signs such as a sudden device change or a failed two-factor authentication. By using data like your login history it prevents fraudsters from accessing your money.
- Preventing QR Code and UPI Payment Scams
To stop scams where fraudsters trick you into sending money, the system spots suspicious payment requests.- One agent collects data
- Another looks for odd behavior, like sending a large amount to a new contact at an unusual time
- A third scores the risk
- Another logs the action
- A final agent checks regulatory compliance
Warning signs include first-time recipients, late-night transfers, or links from chat apps. The system pauses risky payments and displays a warning, helping you reduce scams, increase your trust in alerts, and protect your money.
Architecture: A2A (Agent to Agent) Orchestration with YugabyteDB Vector
At the heart of the multi-agent system sits YugabyteDB Vector (pgvector + HNSW (Hierarchical Navigable Small Words)), purpose-built for BFSI fraud detection:
- Distributed storage of embeddings – Stores fraud transaction and entity embeddings across a geo-distributed, fault-tolerant SQL cluster
- Hybrid SQL + Vector search – Combines semantic similarity with structured constraints (e.g., WHERE merchant_category = ‘Shopping’ AND amount > 5000) to detect fraud in a real-world context
- Regulator-ready foundation – Unlike standalone vector stores, YugabyteDB provides ACID consistency, auditability, and HA (RPO=0) — critical for banking and payments
The A2A Server orchestrates tasks via HTTP, and agents pull/push results asynchronously as shown in Figure 1.

The diagram below (Figure 2) illustrates how React UI, A2A Orchestration Server, Agents, LLM APIs, and YugabyteDB pgvector fit together into the BFSI multi-agent fraud detection system.

The table below outlines the various technical components utilized in developing this A2A solution with YugabyteDB.
| Layer | Tech.Stack | Purpose |
|---|---|---|
| Front End | React JS/HTML | The Financial Analyst opens the query window to query the transaction |
| A2A – Orchestration Server | Node JS | Breaks the query into tasks |
| Agents | Node JS | Poll the tasks and call the LLM API (e.g. Claude API) |
| Vector Storage | YugabyteDB | Everything (tasks, scores, narratives) is stored in YugabyteDB for audit and replay. |
Fraud Detection Workflows with Multiple Agents
At the heart of this system sits YugabyteDB Vector (pgvector + HNSW) with multi-agent orchestration:
- Client → A2A Server → POST /ask
- Retriever Agent → vector search for past cases, patterns
- FraudDetectionBot → detect velocity/device/IP anomalies
- RiskScoringBot → numeric score (e.g., 0.82 with rationale)
- Writer Agent → draft narrative for ops + auditors
- ComplianceBot → align with RBI/AML/KYC mandates
One of the unsung heroes of any multi-agent system is the data contract, the structured messages that agents pass back and forth.
Think of this as a set of agreed-upon rules for how each agent speaks to the others. Without it, you end up with messy text, unclear decisions, and no way to trace what actually happened. In banking and payments, with stringent regulatory requirements, this is non-negotiable.
Learn what is a vector database and why it matters for AI and ML applications in this detailed blog.
What does a task look like?
When the A2A server sends work to an agent, it doesn’t just say, “go figure this out.” It sends a well-structured task object. Imagine it like an assignment slip with:
- A unique ID so we can trace it later
- The type of job (retrieve, detect, score, write, review)
- The agent role it is meant for
- The actual input (e.g., “Investigate TxnID=123 at 02:07, ₹5000, Device X”)
This means that if you ever need to replay what happened, you can reconstruct the whole chain step by step.
What does an agent reply with?
Agents also respond in a structured format, not free-form text. For example:
- FraudDetectionBot might say: “Here are the signals: 5 txns in 2 minutes (velocity spike), and a geo jump from India to Singapore.”
- RiskScoringBot might reply: “Overall risk = 0.82. Rationale: velocity spike + geo jump. Block threshold = 0.80.”
- Writer Agent turns this into something a fraud analyst can read: “TxnID=123 looks suspicious. Risk=0.82 due to unusual velocity and location change.”
- ComplianceBot makes sure the wording lines up with policy: “Soft block recommended under RBI Circular XX/2023, with KYC re-verification in 24h.”
Task Object (Server → Agent)
Each task assigned to an agent is a JSON envelope as shown below.
{
"id": "task-uuid",
"parent_id": "question-uuid",
"type": "RAG_RETRIEVE | FRAUD_DETECT | RISK_SCORE | RAG_WRITE | COMPLIANCE_REVIEW",
"role": "retriever | fraud | risk | writer | compliance",
"input": {
"query": "Investigate TxnID=123 at 02:07, ₹5000, Device X",
"context": ["doc1", "doc2"],
"signals": []
}
}- id → unique task ID for traceability
- parent_id → ties sub-tasks to the original user query
- type → standard action type so the server can route correctly
- role → which agent should handle it
- input → structured payload, role-specific
This ensures that even if the Writer or FraudDetectionBot is re-tried, the payload is consistent.
Agent Completion (Agent → Server)
Agents only reply with structured output. Example:
FraudDetectionBot output:
{
"output": {
"signals": [
{"name": "velocity_spike", "weight": 0.35, "evidence": "5 txns in 2 mins"},
{"name": "geo_jump", "weight": 0.20, "evidence": "India → Singapore in 5 mins"}
]
}
}Every agent adds evidence, confidence, and citations where possible. This turns the pipeline into something auditors can trust, as each decision is reproducible.
Why are the LLM Pieces Important?
- They explain the math and anomalies in plain English
- They make decisions auditable by citing documents and policies
- They provide a compliance safety net so that fraud reports don’t just say “block it” but actually align with regulatory wording
Together, embeddings + ML signals + LLM explanations create a workflow that is both fast enough for fraud detection and clear enough for regulators.
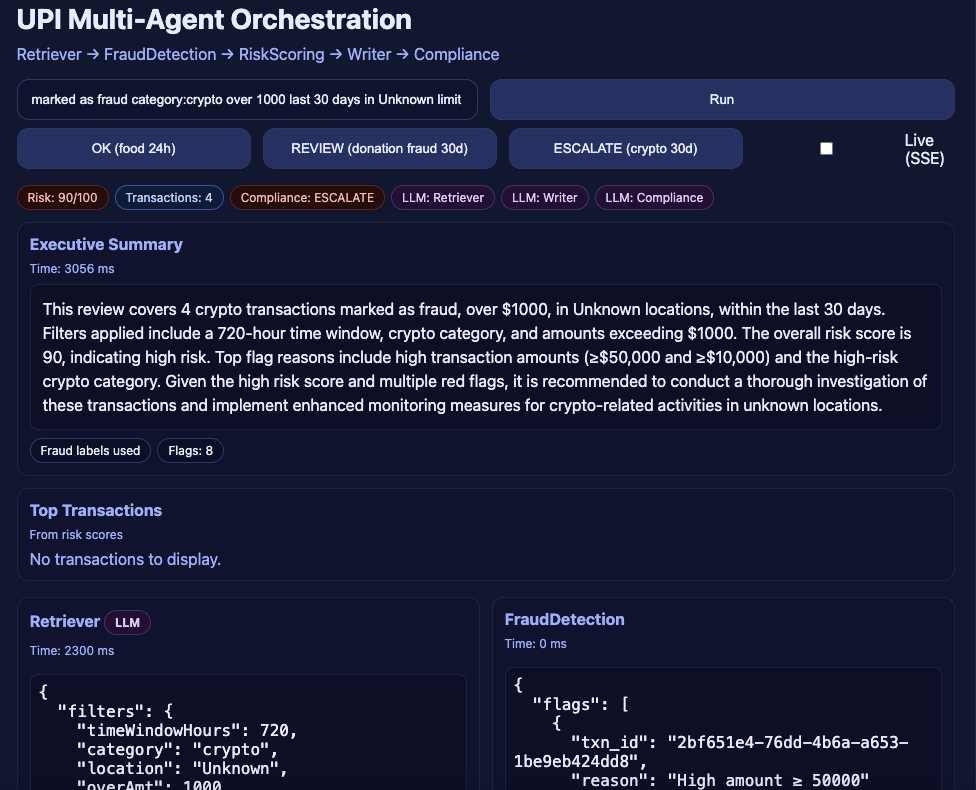
The purpose of the web app (screenshot below) is to demonstrate and operationalize a multi-agent AI system for fraud and compliance in UPI payments.
Instead of being just a backend pipeline, the web app gives you:
- A front-end interface where you can type natural language queries like
“marked as fraud category: crypto over 1000 last 30 days in Unknown limit 5”
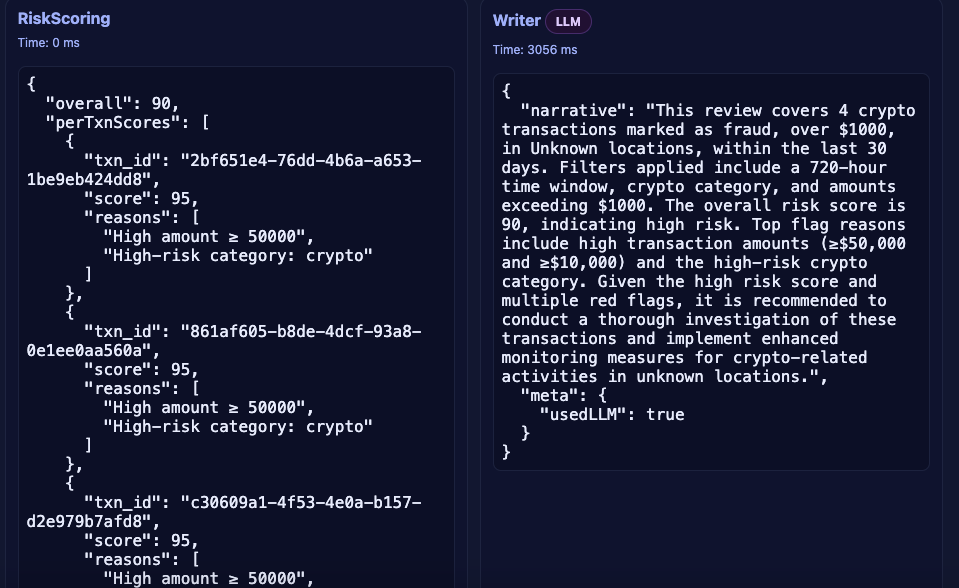
and instantly see how the agents work together - Transparency of the pipeline: it shows step-by-step outputs from
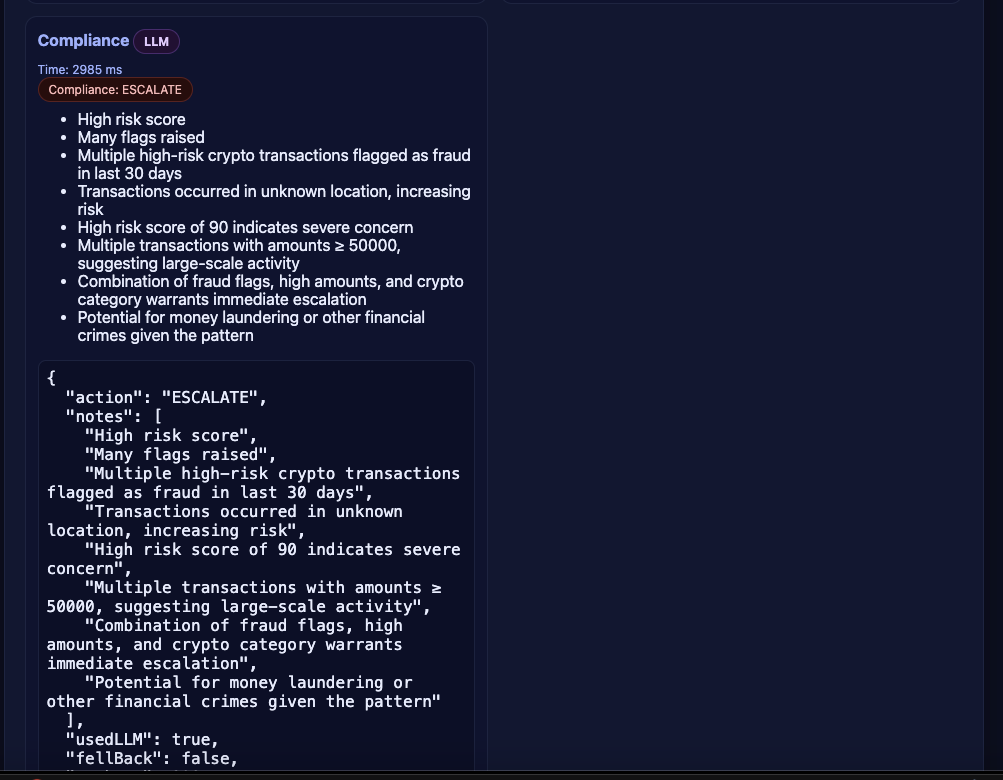
Retriever → FraudDetection → RiskScoring → Writer → Compliance, so you can understand why a transaction is flagged and how a risk score was calculated - Executive summaries and narratives: the Writer agent produces human-readable explanations, and Compliance ensures those narratives match regulatory language
- Interactive demos for BFSI teams: presets (OK, REVIEW, ESCALATE) let fraud teams and regulators see how the same orchestration handles low, medium, and high-risk scenarios
- Experimentation platform: you can tweak queries, thresholds, or weights and watch how the orchestration adapts. This makes it a sandbox for testing fraud rules, vector search performance, and LLM compliance review — all backed by YugabyteDB Vector
Setup/Implementation
- YugabyteDB pgvector Extension: Enables efficient vector operations.
- Follow the steps below to install YugabyteDB 2.25 or 2025.1 on your operating system:
- Follow this GitHub Link to set up this agent and complete the execution
Conclusion
Fraud in BFSI and payments is too complex for a single model or static rule engine. It requires a chain of specialized agents, focused on retrieval, anomaly detection, scoring, explanation, and compliance, working together seamlessly.
By orchestrating Retriever → FraudDetectionBot → RiskScoringBot → Writer: ComplianceBot with YugabyteDB Vector, BFSI organizations achieve:
- Scalable detection at banking scale
- Quantified risk for automation
- End-to-end explainability
YugabyteDB Vector is the backbone of a multi-Agentic-AI system, combining distributed SQL with pgvector ANN to deliver the speed, reliability, and compliance that BFSI-grade fraud detection demands.
Want to know how to build GenAI apps on a PostgreSQL-compatible database? Download our solution brief to discover basic AI concepts, architectural considerations, plus access to hands-on tutorials that demonstrate how to build your first GenAI application on various platforms.


