PostgreSQL Timestamps and Timezones: What You Need to Know—and What You Don’t
January 27, 2022
Anecdotal reports indicate that some PostgreSQL programmers are daunted by the date and time data types, and by how operations that use values of these data types might be affected by the session’s timezone setting. Even experienced developers struggle when they first embark on a critical project that relies on this functionality. YugabyteDB’s YSQL subsystem gives the application developer the same experience as PostgreSQL. So some YSQL users will find the topic challenging, too.
I recently completed a careful and exhaustive study of the topic so that I could write it all up in YugabyteDB’s YSQL documentation. You can check out the result here.
I had no choice but to aim for total understanding—complete in breadth and depth. The exercise left me with these two high-level conclusions:
- PostgreSQL, and therefore YugabyteDB, give you sufficient functionality to let you straightforwardly and correctly meet any requirement that might be set in the date-time space.
- They also provide far more functionality than a correct implementation will need—which surplus serves only to give you enough rope to hang yourself.
If your aim is to write a brand new database application, then you need to understand only what is sufficient for this—and it’s a remarkably small fraction of everything that there is to know in this space. This subsection gives you the links to the accounts of that minimal subset of functionality.
But if you have to maintain an extant application whose developers are long gone, and that has little or no developer-oriented documentation, then you will have to study the whole topic. I hope that my write-up will complement the PostgreSQL documentation and help you with your task.
This is the first of a two part blog post series. It deals with the basic business of representing moments (when things happen) against the background that, for example, different participants in a live international conference call see that their clocks read different times when the call starts and ends from what other participants see. The relevant data types here are time, date, and timestamp—where the latter has a without time zone and a with time zone variant. I’ll use, hereinafter, the short spellings (plain) timestamp and timestamptz, respectively, for these—and timestamp[tz] to denote either one of these.
The second part deals with durations (how long things last). The relevant data type here is interval. When you subtract one timestamp[tz] value from another, you get an interval value. And when you add (or subtract) an interval value to (or from) a timestamp[tz] value, you get a timestamp[tz] value. This sounds as if it couldn’t be simpler. But it turns out that the rules here are complex and confusing.
Why are moments so hard to deal with?
Even as recently as just a couple of decades ago, it was rare to hold conference calls between widely geographically dispersed participants. The convener had to rely on their own calculations to work out what local time in “Your Country” a local time in “My Country” corresponded to. This was tricky when some countries were to the convener’s east, others were to their west, and when the effect could even bring a change in the local date on top of the change in the local time.
The difficulty was compounded when the meeting was a couple of weeks hence and when, by then, some of the invitees might have seen a Daylight Savings Time “fall-back” moment, others (in the other hemisphere) might have seen a “spring-forward” moment, and yet others might have seen no such change. In my experience, mistakes were always made; and some of the invitees could be guaranteed to show up at the wrong time. It was bad enough among colleagues with jobs in software. But it was a nightmare with calls between even just two geographically separated family members. This reflects the fact that the underlying notions are quite simply hard to grasp and even harder to apply correctly in specific scenarios.
Read the subsection “Conceptual background” in the YSQL date-time documentation for an account of these notions:
- Absolute time and the UTC Time Standard
- Wall-clock-time and local time
- Timezones and the offset from the UTC Time Standard
- The strange history of timezones
- Two ways of conceiving of time (calendar-time and clock-time)
These days, and especially since March 2020, virtual gatherings are commonplace. These meetings take place not just among work colleagues; friends and families meet like this too. Moreover, participants are often in different timezones, scattered around the world. People now take it for granted that scheduling such meetings is easy. Typically the meeting convener just sends an invitation, using their favorite calendar application, simply by setting the meeting start and end times as their own local clock will show them. The participants receive their invitations, using their own favorite calendar applications, and each sees the meeting times as their own local clock will show them.
How do modern calendar applications implement their date-time magic?
Such applications allow users of browsers and dedicated interfaces on personal computers, tablets, smartphones, and even watches, to access a central calendar (typically hosted on a Cloud platform) that supports either a single user or a community of users. A calendar application, then, is tautologically a database application (with a small “d”). And a standardized protocol allows a user of one such calendar database to send or receive invitations to or from users in many other calendar databases—no matter how they might be implemented.
Of course, one natural implementation scheme is to use a SQL database like PostgreSQL or YugabyteDB. Both of these offer the application developer the identical SQL features that expose simple, declarative, schemes that turn date-time magic into automagic. Here is the minimal, sufficient, feature set:
- The timestamp data types—both with time zone and without. Notice that timestamptz values represent absolute times and plain timestamp values represent local times.
- The ability to set the session timezone.
- The ability to transform from a timestamptz value to a plain timestamp value, or vice versa—either implicitly, respecting the session’s timezone setting, or explicitly using the at time zone operator.
- The ability to transform between text values, or number values, and timestamp[tz] values: in the to-date-time direction using make_timestamptz(), make_timestamp(), or to_timestamp(); and in the to text direction using to_char().
Notice that the two spellings, “time zone” and “timezone” (with and without a space), are both used in SQL statements. The YSQL documentation uses the spelling without a space in prose as the term of art for the underlying concept. I’ll do the same in this blog post and its partner.
Before saying more about the mechanisms, I’ll give you a straightforward example of the declarative automagic at work. It simply displays a pair of absolute moments as they are observed as local moments in different timezones.
set timezone = 'America/New_York'; with utc_times as ( select '2021-03-10 18:00 UTC'::timestamptz as t1, '2021-03-20 18:00 UTC'::timestamptz as t2), la_times as ( select 'Los Angeles' as place, t1 at time zone 'America/Los_Angeles' as t1, t2 at time zone 'America/Los_Angeles' as t2 from utc_times), amsterdam_times as ( select 'Amsterdam' as place, t1 at time zone 'Europe/Amsterdam' as t1, t2 at time zone 'Europe/Amsterdam' as t2 from utc_times), kathmandu_times as ( select 'Kathmandu' as place, t1 at time zone 'Asia/Kathmandu' as t1, t2 at time zone 'Asia/Kathmandu' as t2 from utc_times), auckland_times as ( select 'Auckland' as place, t1 at time zone 'Pacific/Auckland' as t1, t2 at time zone 'Pacific/Auckland' as t2 from utc_times) select place, t1::text, t2::text from la_times union all select place, t1::text, t2::text from amsterdam_times union all select place, t1::text, t2::text from kathmandu_times union all select place, t1::text, t2::text from auckland_times order by place;
This is the result:
place | t1 | t2 -------------+---------------------+--------------------- Amsterdam | 2021-03-10 19:00:00 | 2021-03-20 19:00:00 Auckland | 2021-03-11 07:00:00 | 2021-03-21 07:00:00 Kathmandu | 2021-03-10 23:45:00 | 2021-03-20 23:45:00 Los Angeles | 2021-03-10 10:00:00 | 2021-03-20 11:00:00
As it happens, the result is independent of the session’s timezone setting. The set timezone statement (without a space) is included in the example just to contrast its spelling with that of the at time zone operator (with a space). (There’s also a set time zone statement, where the argument is not preceded by the equals sign. How confusing is that!)
The query result (above) lines up with what your general knowledge tells you.
- Amsterdam is to the east of the Greenwich Meridian. It observes Daylight Savings Time. But its 2021 “spring-forward” moment is 28-March, so both t1 and t2 happen to be in its winter time. That’s why each is one hour later than UTC.
- Auckland is very close to 180° away from the Greenwich Meridian—so it’s up to you whether you think that this is to the east or to the west of the line. If you go west, then the local time gets later and later until you reach twelve hours later (by the sun) in New Zealand. If you go east, then the local time gets earlier and earlier—but then you cross the International Date Line and jump to the next (i.e. later) day. Then the local time gets earlier and earlier again so that when you reach New Zealand you see that it’s twelve hours later than UTC (by the sun), of course—just as it is when you go the other way. Auckland observes Daylight Savings Time. The clock change date in 2021 is 4-April. Because it’s in the southern hemisphere, this is a “fall-back” moment, so both t1 and t2 are in its summer time. That’s why 18:00 UTC becomes 07:00 the next day for both t1 and t2.
- Kathmandu is further to the east, again, of Amsterdam. It also is one of the few places whose timezone offset with respect to UTC isn’t a whole number of hours. Moreover, it does not observe Daylight Savings Time. That’s why each of t1 and t2 is five and three quarter hours later than UTC—as is the case on every day in the year.
- Los Angeles is to the west of the Greenwich Meridian. It observes Daylight Savings Time. The clock change date in 2021 is 14-March, Because it’s in the northern hemisphere, this is a “spring-forward” moment, so t1 is in its winter time and t2 is in its summer time. That’s why 18:00 UTC becomes 10:00 for t1 and 11:00 for t2.
Repeat the select statement after changing the date part of t2 in the utc_times common table expression to, say 2021-04-10. This is after the Daylight Savings Time clock change date in all places. Leave the value of t1 unchanged so that its date part stays at 2021-03-10—that is, before the Daylight Savings Time clock change date in all places. Here is the new result:
place | t1 | t2 -------------+---------------------+--------------------- Amsterdam | 2021-03-10 19:00:00 | 2021-04-10 20:00:00 Auckland | 2021-03-11 07:00:00 | 2021-04-11 06:00:00 Kathmandu | 2021-03-10 23:45:00 | 2021-04-10 23:45:00 Los Angeles | 2021-03-10 10:00:00 | 2021-04-10 11:00:00
Notice how the time of the later date for each of Amsterdam and Los Angeles has sprung forward; and the time of the later date in Auckland has fallen back.
The outcomes that these two results show are a perfect illustration of what I mean by declarative automagic. The select statement has no explicit calculations. It simply defines two absolute moments of interest. And then it declares that it wants to see these through the local eyes of folks in Amsterdam, Auckland, Kathmandu, and Los Angeles.
If you’re impatient to see the SQL that a multi-user calendar application would use, look at the YSQL documentation subsection A minimal simulation of a calendar application. It assumes that the calendar application has a preference setting for the timezone that the user is in (or wants to pretend they’re in). The application uses this to set the session’s timezone.
The tz timezone database
Read about the tz database in Wikipedia. It’s also known as the IANA time zone database. It has the organizational backing of ICANN—in other words, it’s a standards-backed, freely downloadable resource. It provides the facts that PostgreSQL uses to implement its date-time functionality; and a small projection of its facts is exposed in the pg_timezone_names view’s columns: name, abbrev, utc_offset, and is_dst.
The content of the tz database changes as the conventions that countries follow change (like whether Daylight Savings Time is observed and, if so, when summer time starts and ends). Successive PostgreSQL versions aim to stay current with the tz database. But the YSQL system, based on Version 11.2, presently uses an out-of-date snapshot. However, the differences between that and current PostgreSQL are very few and probably won’t trouble you. I make lots of references to the tz database in my documentation.
Avoiding pitfalls when you specify the timezone
The outcomes of various SQL operations change if the session’s timezone setting is changed. The YSQL documentation section Scenarios that are sensitive to the UTC offset identifies, and explains, these. Notice the title’s wording: it says UTC offset rather than timezone—and it does this to be precise and accurate. It’s easy to see what I’m getting at. If the question is “What time is it in Los Angeles when it’s seven in the morning in Auckland?”, then the answer is given by calculating what the Aukland time is in UTC and then calculating what that UTC time is in Los Angeles.
The first step needs to know what the UTC offset is (as an interval value) of Auckland on the day in question; and the second step needs to know what the UTC offset is of Los Angeles then. The two sets of query results that are presented in the previous section of this post show vividly that the answer is different on different dates. The reason, of course, is that each of the timezones Europe/Amsterdam, Pacific/Auckland and America/Los_Angeles denotes a different UTC offset in that timezone’s summer time than it does in its winter time.
Under almost all circumstances, you want to specify the timezone and to let the underlying system use that level of indirection to look up what the UTC offset is at the moment at which the operation is to take place.
Here’s a telling example of the critical importance of using the timezone level of indirection so that the system can map this correctly to UTC offset at any moment of interest. Look at the Wikipedia article Standard Time in the United States. It discusses the radical change in thinking that the advent of rail travel, in the continental US states, brought towards the end of the nineteenth century.
First create this trivial formatting function (simply to reduce the clutter in the historical_timezone_changes() function.
drop function if exists fmt(timestamptz) cascade; create function fmt(t in timestamptz) returns text language plpgsql as $body$ begin return ' '||to_char(t, 'yyyy hh24:mi:ss TZH:TZM'); end; $body$;
Now create and execute the historical_timezone_changes() table function to demonstrate what the Wikipedia article describes.
drop function if exists historical_timezone_changes() cascade;
create function historical_timezone_changes()
returns table(x text)
language plpgsql
as $body$
declare
zones constant text[] not null := array[
'Europe/London',
'America/New_York',
'America/Chicago',
'America/Denver',
'America/Los_Angeles',
'Pacific/Honolulu'];
z text not null := zones[1];
-- I recommend using the set_timezone() wrapper.
-- See this post’s section "The set_timezone() and at_timezone()
-- user-defined subprograms" below.
stmt constant text := $set timezone = '%s'$;
begin
foreach z in array zones loop
execute format(stmt, z);
x := current_setting('timezone'); return next;
x := fmt('1883-11-18 16:00:00 UTC'::timestamptz); return next;
x := fmt('1883-11-18 20:00:00 UTC'::timestamptz); return next;
x := fmt('1946-11-18 20:00:00 UTC'::timestamptz); return next;
x := fmt('2021-11-18 20:00:00 UTC'::timestamptz); return next;
x := ''; return next;
end loop;
end;
$body$;
select x from historical_timezone_changes();This is the result:
Europe/London 1883 16:00:00 +00:00 1883 20:00:00 +00:00 1946 20:00:00 +00:00 2021 20:00:00 +00:00 America/New_York 1883 11:03:58 -04:56 1883 15:00:00 -05:00 1946 15:00:00 -05:00 2021 15:00:00 -05:00 America/Chicago 1883 10:09:24 -05:50 1883 14:00:00 -06:00 1946 14:00:00 -06:00 2021 14:00:00 -06:00 America/Denver 1883 09:00:04 -06:59 1883 13:00:00 -07:00 1946 13:00:00 -07:00 2021 13:00:00 -07:00 America/Los_Angeles 1883 08:07:02 -07:52 1883 12:00:00 -08:00 1946 12:00:00 -08:00 2021 12:00:00 -08:00 Pacific/Honolulu 1883 05:28:34 -10:31 1883 09:28:34 -10:31 1946 09:30:00 -10:30 2021 10:00:00 -10:00
The results show that New York, Chicago, Denver, and Los Angeles all had chaotic UTC offsets, and correspondingly chaotic local times with respect to each other, up until 18-November-1813. Then, during that day, each of these areas made a drastic change so that from then on, the regimes became what we are used to today. They had to do this so that they could design intelligible train timetables for journeys that crossed the boundaries between these timezones.
There was, of course, no such drama in London because it lies on the Greenwich Meridian and therefore tautologically has always had a UTC offset of zero. Meanwhile, Hawaii didn’t make any changes until some time later. And then it wasn’t until 1947 that it finally settled on what we are used to today. (The article doesn’t talk about Hawaii. You can find out more about timezone and clock changes in Honolulu here.) By the way, several of these places made experimental temporary changes to their Daylight Savings rules during the Second World War.
The moral of this tale is simple: you must have a very good reason indeed to specify the UTC offset explicitly as an interval value. If you really believe that you do, then you must record your reasoning clearly in external code documentation or in comments. Otherwise, always specify the UTC offset indirectly and rely on the system to use the current information from the tz database to convert from the name of a timezone to the offset that was in force on the date of interest—no matter how far into the past it might be. Of course, the tz database isn’t clairvoyant: who knows what future changes might be made?
You can see from this article that the topic of whether or not to change the clock twice a year is hotly debated and subject to bureaucratic legislation. Some people want to continue to do this while others want to stop the practice. And among those who want to stop it, some want always to be on winter time and others want always to be on summer time. The only way to future-proof your code so that it will continue to give currently correct results no matter what rule changes are made is always to persist data as timestamptz values and to let the system—kept current with the tz database—work its magic according to the rules that it presently embodies.
The extended_timezone_names view and its cousins
See the YSQL documentation section The extended_timezone_names view. This describes how to create a user-defined view that adds extra columns to the native pg_timezone_names view to expose other interesting facts from the current tz database.
To create the extended_timezone_names view, download and install the companion code kit for the YSQL date-time documentation as this page describes. It’s done in a heartbeat. It contains a recent download from the public tz database. For trying the code examples in this post, just install it as your usual test user. If you want to use parts of it in a real application, just selectively install what you need—probably in a dedicated common location on your database.
The extended_timezone_names view restricts the content to only those rows where the current tz database agrees with the implemented system. In other words, rows with the same unique key (the timezone name) in both sources that disagree on one, or more, of the other facts are eliminated; and, of course, rows that are present in one source but absent in the other are also not represented in extended_timezone_names. If you rely on the extended_timezone_names view rather than the native pg_timezone_names view, then you’ll be insulated from the fact that the within-database implementation might lag the current tz database by using only those facts where they agree.
Try this:
select (select count(*) from pg_timezone_names) as "pg count", (select count(*) from extended_timezone_names) as "extended count";
Using YugabyteDB Version YB-2.9, it returns, respectively, 593 and 578—showing that extended_timezone_names eliminates fifteen rows from pg_timezone_names. The same query using PostgreSQL Version 14.1 returns, respectively, 595 and 591—showing that only four rows have been eliminated here.
Notice that the extended_timezone_names view has a column status. The obvious select distinct query shows that the list of values is Canonical, Alias, and Deprecated. Try this:
with
c1 as (
select
(
abbrev, std_abbrev, dst_abbrev, utc_offset,
std_offset, dst_offset, is_dst, country_code
) as r1
from extended_timezone_names
where name = 'America/Los_Angeles' and status = 'Canonical'),
c2 as (
select
(
abbrev, std_abbrev, dst_abbrev, utc_offset,
std_offset, dst_offset, is_dst, country_code
) as r2
from extended_timezone_names
where name = 'US/Pacific' and status = 'Deprecated')
select (
(select r1 from c1) = (select r2 from c2)
)::text;It returns true—showing that most of the facts about the America/Los_Angeles and the US/Pacific timezones are the same. The predicates on status are for self-documentation. They show that America/Los_Angeles is Canonical and that US/Pacific is Deprecated. Notice that the comparison excludes the columns lat_long and region_coverage. Ad hoc queries will show you that the facts are defined for the Canonical timezone and are null for the Deprecated timezone. So not only is US/Pacific an old-fashioned name; also, not all facts are available for it.
The set_timezone() and at_timezone() user-defined subprograms
Try this:
deallocate all;
prepare stmt as
select to_char('2021-01-01 12:00:00 UTC'::timestamptz, 'hh24:mi TZH:TZM');
set timezone = 'America/New_York';
execute stmt;This is the result:
07:00 -05:00
This is, so far, unremarkable. New York has a UTC offset of minus five hours in its winter time, so twelve noon UTC is seven in the morning there. Now try this:
set timezone = 'America1New_York'; execute stmt;
The only difference, here, is that the forward slash in America/New_York is replaced with the digit 1. This mimics a simple typo that the code author might fail to notice. You might think that the set timezone attempt would fail. In fact, if you try the exclamation point, ! ,in place of the proper forward slash, then you do get the 22023 error (“invalid value for parameter… “). But using the digit 1 doesn’t cause an error. This is the new result:
11:00 -01:00
You might think that this is a straight bug. I certainly did when I first stumbled on it. Internet search shows that many developers have been confused by this, too. But your searches lead you eventually to understand that this functionality is intended.
If the supplied text literal for set timezone isn’t found in pg_timezone_names (see the YSQL documentation section Rules for resolving a string that’s intended to identify a UTC offset) then an attempt is made to parse it as POSIX syntax. See the appendix B.5. POSIX Time Zone Specifications in the PostgreSQL documentation. The YSQL documentation covers this in the subsection Directly using POSIX syntax. Briefly, the POSIX syntax, if you exploit its expressivity, allows you to specify the two UTC offset values, one for Standard Time and one for Summer Time, along with the “spring forward” and “fall back” moments. And it uses the opposite convention for the sign of the offset than does the rendering that the TZH:TZM template pattern for to_char() uses.
Any candidate text literal for set timezone that has, for example, just one embedded digit is taken to be legal POSIX syntax, and the remaining characters, in this example at least, are taken to be free-form commenting. So the embedded 1 in the example above is taken to denote a UTC offset of minus one hour! This is a vivid example of what I mean, in this post’s introduction, by “[providing you with] far more functionality than a correct implementation will need—which surplus serves only to give you enough rope to hang yourself”.
The YSQL documentation section Recommended practice for specifying the UTC offset shows the code to create the procedure set_timezone(). This is a wrapper for the set timezone statement that ensures that this is invoked safely with respect to the POSIX risk that the previous paragraph describes and with respect to other risks too. It has two overloads—one with a text formal parameter and one with an interval formal parameter. The second one is provided only as a fallback in case you are convinced, beyond all doubt, that your use case calls for specifying the UTC offset explicitly. I’ll say no more about it here. The first overload checks that the value of the actual text argument is found exactly once in the approved_timezone_names user-created view. Loosely stated, this view restricts the rows from the extended_timezone_names user-created view to just those that have Canonical status. Follow the link to the YSQL documentation to see the actual definition.
The “Recommended practice for specifying the UTC offset” section also shows the code to create the function at_timezone(). This is a wrapper for the functionality of the at time zone operator that enforces the same safety criteria as does the set_timezone() procedure. Just like the operator that it wraps, it can convert a timestamptz value to a plain timestamp value or a plain timestamp value to a timestamptz value in the regime of a UTC offset that is specified indirectly by using a timezone name. This is the recommended approach unless here too you are convinced, beyond all doubt, that your use case calls for specifying the UTC offset explicitly. It therefore has four overloads corresponding to the combinations of plain timestamp or timestamptz with text or interval.
If you downloaded and installed the companion code kit, then you’ll see that you already have set_timezone() and at_timezone() ready to use.
How to decide which moment data type to use
I recommend always using timestamptz to persist values and using date, time, or plain timestamp only as stepping stones for converting from timestamptz to text for display or from text user input to timestamptz for persistence.
The following accounts of these four moment data types, and the subsequent code examples, will show you why I make this recommendation. This picture shows how the four moment data types are related. The internal representations are of no interest. All that matters is the semantics that values of each of these data types represent.
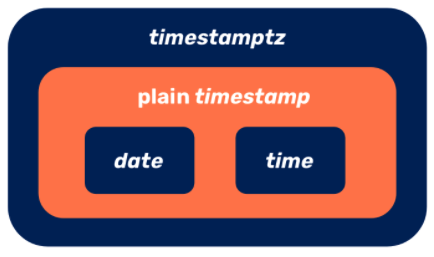
date
The date data type records just the year (as an int value that accommodates a bigger range than timestamp[tz]) the month (as an int value in [1, 12]), and the day-in-month (as an int value in [1, 31]) of a moment. The value knows nothing of timezones, and operations on date values are insensitive to the reigning timezone. Of course, when a date value is assigned, the underlying facts from the tz database are consulted to ensure that the value is legal with respect to how many days different months have and how, for February, this is affected by leap years.
time
The time data type records just the hour (as an int value in [0, 23]), the minute (as an int value in [0, 59]), and the seconds (as a double precision value with six decimal digits of precision in [0, 59.999999]), of a moment. Here too, the value knows nothing of timezones, and operations on time values are insensitive to the reigning timezone.
plain timestamp
A plain timestamp value is, quite simply, a date value together with a time value combined into a single value. And as is the case for date values and time values, a plain timestamp value knows nothing of timezones, and operations on such values are insensitive to the reigning timezone.
timestamptz
Developers are frequently confused about the difference (more exactly, the lack of difference) between what plain timestamp and timestamptz values actually record. The semantic expressivity of a timestamptz datum is identical to that of a plain timestamp datum. The difference between the two data types is entirely in their metadata. This is most vividly shown by the two built-in functions make_timestamp() and make_timestamptz()—and by what happens when you observe values created by these with different reigning timezones. Try this:
drop table if exists t cascade;
create table t(k int primary key, ts timestamp, tstz timestamptz);
call set_timezone('Asia/Kathmandu');
insert into t(k, ts, tstz) values
(
1,
make_timestamp (2021, 6, 15, 15, 0, 0.0),
make_timestamptz(2021, 6, 15, 15, 0, 0.0, 'UTC')
),
(
2,
make_timestamp (2021, 6, 15, 15, 0, 0.0),
make_timestamptz(2021, 6, 15, 15, 0, 0.0, 'America/Los_Angeles')
),
(
3,
make_timestamp (2021, 6, 15, 15, 0, 0.0),
make_timestamptz(2021, 6, 15, 15, 0, 0.0, 'America/New_York')
);
deallocate all;
prepare stmt as select k, ts::text, tstz::text from t order by k;Each of make_timestamp()’s six parameters (year, month, mday, hour, min, and sec) is mandatory. Each of these parameters is mandatory, too, for make_timestamptz(). But it has a seventh, optional, text parameter, timezone. If no actual argument for timezone is provided, then the session’s current timezone setting is used.
Execute stmt when the session’s timezone setting is UTC:
call set_timezone('UTC');
execute stmt;This is the result:
k | ts | tstz ---+---------------------+----------------------- 1 | 2021-06-15 15:00:00 | 2021-06-15 15:00:00+00 2 | 2021-06-15 15:00:00 | 2021-06-15 22:00:00+00 3 | 2021-06-15 15:00:00 | 2021-06-15 19:00:00+00
If you use a different timezone name than Asia/Kathmandu in the setup script above (just before the insert statement), then you’ll see that this setting has no effect on the result—because, by definition, setting a plain timestamp value is insensitive to the reigning timezone and, in this example, the timestamp for setting each timestamptz value is specified explicitly (and differently for each row).
Now inspect the outcome using two different timezone settings: This is the result using Asia/Kathmandu:
k | ts | tstz ---+---------------------+-------------------------- 1 | 2021-06-15 15:00:00 | 2021-06-15 20:45:00+05:45 2 | 2021-06-15 15:00:00 | 2021-06-16 03:45:00+05:45 3 | 2021-06-15 15:00:00 | 2021-06-16 00:45:00+05:45
And this is the result using Pacific/Auckland:
k | ts | tstz ---+---------------------+----------------------- 1 | 2021-06-15 15:00:00 | 2021-06-16 03:00:00+12 2 | 2021-06-15 15:00:00 | 2021-06-16 10:00:00+12 3 | 2021-06-15 15:00:00 | 2021-06-16 07:00:00+12
Here’s how to understand the results—and, in particular, how they can depend on the reigning timezone when the actual persisted datum for a timestamptz value does not record the timezone that reigned when it was set.
- When a timestamptz value is set, the system computes the local time in UTC to which this corresponds and records this, using the same format as is used to record a plain timestamp value. The system knows to do this computation because the metadata of the timestamptz data type tells it to do this.
- When an existing timestamptz value is displayed as a text value, the system computes the local time of the recorded value in the reigning timezone and adds this timezone name’s current abbreviation (or the UTC offset to which this corresponds) at the moment in question, if the conversion to text asks for this. The reigning timezone will either be the session’s current timezone setting (as is the case in the example above) or what the at time zone operator specifies if the timestamptz value is converted first to a plain timestamp value and thence to a text value. Here too, the system knows to do this computation because the metadata of the timestamptz data type tells it to do this.
If you want to observe a persisted timestamptz value (or the value of a PL/pgSQL timestamptz variable), then you can compare it with a known timestamptz value. Or you can use extract(epoch… ) as the code below shows. It returns the number of seconds (as a double precision value with a precision of six-decimal digits) since the start of the so-called Unix epoch. You can see when this is by going in the reverse direction with the double precision overload of to_timestamp():
call set_timezone('UTC');
with c as (select to_timestamp(0::double precision) as t)
select
pg_typeof(t) as "Data type",
t::text as "When"
from c;This is the result:
Data type | When --------------------------+------------------------ timestamp with time zone | 1970-01-01 00:00:00+00
First create a pair of helper functions:
drop function if exists e(timestamp) cascade;
create function e(t in timestamp)
returns text
language plpgsql
as $body$
begin
return to_char(extract(epoch from t), '99,999,999,999');
end;
$body$;
drop function if exists e(timestamptz) cascade;
create function e(t in timestamptz)
returns text
language plpgsql
as $body$
begin
return to_char(extract(epoch from t), '99,999,999,999');
end;
$body$;Doing this conveniently demonstrates that the two data types, plain timestamp and timestamptz, are overload distinguishable. Now do this:
deallocate all;
prepare stmt as
select k, e(ts) as "seconds from ts", e(tstz) as "seconds from tstz" from t order by k;
call set_timezone('UTC');
execute stmt;This is the result:
k | seconds from ts | seconds from tstz ---+-----------------+------------------- 1 | 1,623,769,200 | 1,623,769,200 2 | 1,623,769,200 | 1,623,794,400 3 | 1,623,769,200 | 1,623,783,600
Notice that the extracted value, 1,623,769,200 seconds, is the same in each row for the plain timestamp value, ts, and also for the k=1 row for the timestamptz value, tstz. The fact that the extracted seconds from the tstz value in the k=2 and k=3 rows reflects the fact that these were converted to UTC with reigning timezones other than UTC. If you re-execute stmt with different session timezone settings, then you always see the same results.
The property of extract(epoch… ) for a timestamptz actual argument that the result is not affected by the reigning timezone is explained in the YSQL documentation subsection Demonstrating the rule for displaying a timestamptz value in a timezone-insensitive way (in the “timestamptz data type” section.
The YSQL documentation section Sensitivity of converting between timestamptz and plain timestamp to the UTC offset explains the notions that the demonstration above illustrates from a different, but complementary, point of view.
Typecasting between values of the four moment data types and between these and text values
The YSQL documentation section Typecasting between values of different date-time datatypes addresses the first part of this topic. The Summary table shows which typecasts are legal, and what the semantics for each legal typecast is. It also shows which typecasts are illegal. The rules line up with common sense. Create these helper functions to make the actual tests easier to write and to read:
drop function if exists date_value() cascade;
create function date_value()
returns date
language sql
as $body$
select make_date(2021, 6, 1);
$body$;
drop function if exists time_value() cascade;
create function time_value()
returns time
language sql
as $body$
select make_time(12, 13, 42.123456);
$body$;
drop function if exists plain_timestamp_value() cascade;
create function plain_timestamp_value()
returns timestamp
language sql
as $body$
select make_timestamp(2021, 6, 1, 12, 13, 19.123456);
$body$;There are six typecasts to test: from each of date, time, and plain timestamp to each of the other two data types. Create and execute the table function typecast_results() to execute these tests:
drop function if exists typecast_results() cascade;
create function typecast_results()
returns table(z text)
language plpgsql
as $body$
begin
-- From date
begin
z := (date_value()::time)::text; return next;
-- cannot cast type date
-- to time without time zone
exception when cannot_coerce then null; end;
z := (date_value()::timestamp)::text; return next;
-- From time
begin
z := (time_value()::date)::text; return next;
-- cannot cast type time without time zone
-- to date
exception when cannot_coerce then null; end;
begin
z := (time_value()::timestamp)::text; return next;
-- cannot cast type time without time zone
-- to timestamp without time zone
exception when cannot_coerce then null; end;
-- From plain timestamp
z := (plain_timestamp_value()::date)::text; return next;
z := (plain_timestamp_value()::time)::text; return next;
end;
$body$;
select z from typecast_results();The bare statements show what’s legal. And the exception handlers show what’s illegal and what the error messages are. These are the results:
2021-06-01 00:00:00 2021-06-01 12:13:19.123456
In summary:
- Typecasting a date value to a plain timestamp value sets the target’s time component to midnight.
- Typecasting a plain timestamp value to a date value sets the target to the source’s date component and ignores its time component.
- Typecasting a plain timestamp value to a time value sets the target to the source’s time component and ignores its date component.
You can test the typecasts from/to date values and time values to/from timestamptz values by implementing a timestamptz_value() function, by replacing timestamp_value() with timestamptz_value(), and by changing ::timestamp to ::timestamptz. The function then runs without error. You can understand the result values by understanding that the conversion to/from timestamptz values goes via plain timestamp values.
You can bring the same thinking to bear when you bring in text sources or targets. See the YSQL documentation section Typecasting between date-time values and text values.
Example: recording an event at the moment it happens and viewing it as you want to see it
I’ve already recommended that you must always persist moments as timestamptz values. If you want to record the moment that a row is inserted into a table, you can use the transaction_timestamp() function because, as its name implies, it records the start moment of the transaction to which the insert belongs. (You can’t discover the moment at which a transaction is committed.) The return data type is timestamptz—which is exactly what you want. As it happens, there are no functions that return the start moment of a transaction as any data type other than timestamptz.
Notice, however, that it’s probably better to use the clock_timestamp() function. This simply returns the wall clock time at the instant of invocation—not caring about when transactions, or statements, start. The application is probably interested in when the end user nominally hit “Save”. And no timestamptz value that’s read inside the database can be used as anything more than an approximate indication of the end user’s action. Network latencies between the end user’s browser and the database will doubtless dominate the measurement inaccuracy.
When, later, you want to see at what (approximate) moment the row was inserted, you can see it as the local time in any timezone of interest. To support one flavor of this, you need to record not only the timestamptz value for the row’s insertion; you need also to record the session’s timezone name at that moment.
Create the table thus:
drop table if exists events cascade;
create table events(
what text primary key,
created_tstz timestamptz not null default transaction_timestamp(),
created_tzname text not null default current_setting('TimeZone'));Enforce the rule that, following the insert, the values of created_tstz and created_tzname cannot thereafter be changed. Create a trigger, thus:
drop function if exists trg_enforce_events_defaults_immutable() cascade;
create or replace function trg_enforce_events_defaults_immutable()
returns trigger
language plpgsql
as $body$
begin
assert false, 'Cannot update events.created_tstz or events.created_tzname';
return null;
end;
$body$;
create trigger enforce_events_defaults_immutable
after update
on events
for each row
when
(
(old.created_tstz is distinct from new.created_tstz ) or
(old.created_tzname is distinct from new.created_tzname)
)
execute procedure trg_enforce_events_defaults_immutable();You can test the trigger like this. (But wait until you’ve inserted at least one row.) The update attempt causes the intended error.
update events set created_tzname = 'UTC';
Prepare the query to compute the creation date value and time value as the local values in any nominated timezone of interest. One timezone is user-specified by stmt’s formal parameter and brings results identified with the aliases ending with here. The other timezone, created_tzname, is read from the table and brings results identified with the aliases ending with there.
deallocate all;
prepare stmt(text) as
with c as (
select
what,
at_timezone($1, created_tstz) as ts_here,
at_timezone(created_tzname, created_tstz) as ts_there
from events)
select
what,
to_char(ts_here::date, 'Day dd-Mon-yyyy' ) as "Date here",
to_char(ts_here::time, 'hh24:mi') as "Time here",
to_char(ts_there::date, 'Day dd-Mon-yyyy' ) as "Date there",
to_char(ts_there::time, 'hh24:mi') as "Time there"
from c
order by what;Notice that the approach here uses the at time zone operator to convert the persisted timestamptz values to local plain timestamp values in the timezones of interest and then to typecast these values both to date and to time to separate out these components for display (or for any other purpose). These typecasts are safe because each of the data types date, time, and plain timestamp knows nothing of timezones—so the conversions are insensitive to the session’s timezone setting.
Insert some rows, mimicking doing each insert at a different location:
call set_timezone('America/Los_Angeles');
insert into events(What) values('Arrived Los_Angeles');
call set_timezone('Europe/London');
insert into events(What) values('Arrived London');
call set_timezone('Asia/Kathmandu');
insert into events(What) values('Arrived Kathmandu');List the events where here is Los Angeles:
\x on
\t on
execute stmt('America/Los_Angeles');This is the result (when I tested this code):
what | Arrived Kathmandu Date here | Friday 14-Jan-2022 Time here | 12:10 Date there | Saturday 15-Jan-2022 Time there | 01:55 -----------+---------------------- what | Arrived London Date here | Friday 14-Jan-2022 Time here | 12:10 Date there | Friday 14-Jan-2022 Time there | 20:10 -----------+---------------------- what | Arrived Los_Angeles Date here | Friday 14-Jan-2022 Time here | 12:10 Date there | Friday 14-Jan-2022 Time there | 12:10
Re-execute stmt, setting here to any other timezone of interest—for example, each in turn of Europe/London and Asia/Kathmandu. This is the result for Kathmandu:
what | Arrived Kathmandu Date here | Saturday 15-Jan-2022 Time here | 01:55 Date there | Saturday 15-Jan-2022 Time there | 01:55 -----------+---------------------- what | Arrived London Date here | Saturday 15-Jan-2022 Time here | 01:55 Date there | Friday 14-Jan-2022 Time there | 20:10 -----------+---------------------- what | Arrived Los_Angeles Date here | Saturday 15-Jan-2022 Time here | 01:55 Date there | Friday 14-Jan-2022 Time there | 12:10
Conclusion
In this post, I’ve claimed (and backed this up with some examples) that PostgreSQL’s date-time apparatus, inherited by YSQL, is vast and complex. This is a direct consequence of inescapable facts of astronomy and the history of human convention. The size and complexity means that you can easily go wrong.
You can avoid going wrong by realizing that for new work you need only a small subset of the whole apparatus together with some user-defined utilities that enforce safety. I’ve shown you a couple in this post. I’ll show you more in my follow-up post on working with the interval data type.
I’ve heard many conference talks and read many blog posts about mistakes that SQL developers make. One howler that figures very high on the list is to store moment values as text—simply saying “no thanks” to the dedicated data types. This can be explained only by ignorance and superstitious fear of nominal complexity. The examples showed you that using the dedicated date-time data types supports declarative operations that rely on the facts from the tz database. You cannot implement such operations without accessing these facts. And I challenge you to reinvent the wheel that PostgreSQL and YSQL bring you. The effort would be enormous. And the likelihood that your own wheel would be squeaky, to say the least, is huge.
Another common mistake, albeit lower down on the list of conference speakers’ and bloggers’ rants, is to use plain timestamp to persist moment values rather than timestamptz. The explanation can only be the same: a superstitious belief that the timestamptz automagic is so hard to understand that you’re bound to slip up. But saying “no thanks” to timestamptz for persistence, even though you can convert from persisted plain timestamp values to ephemeral timestamptz values using the techniques like the at time zone operator that I’ve shown you, means that you’ll spend a large effort to make your code needlessly complex and to bring a high probability of bugs.
Using any software platform as it was designed to be used is always the key to success.
I’ll finish by reminding you that YugabyteDB’s YSQL subsystem uses PostgreSQL’s SQL processing C code as is. I’ve run all the code examples in this post, and all the code examples in the date-time section of the YSQL documentation, in both environments. With the tiny caveat that query results that depend on the content of the tz database might differ a little, as I explained, all the results from the code examples are the same in both YugabyteDB and PostgreSQL. I hope, therefore, that users of PostgreSQL will find this post interesting and will come to value the documentation that I wrote as a useful resource to complement the PostgreSQL documentation.
Check out Part 2 in this two-part blog series titled, How to Navigate the Interval Minefield. And if you haven’t already, you can take YugabyteDB for a spin by downloading the latest version of the open source.


