Reads in YugabyteDB – Tuning Consistency, Latency and Fault Tolerance
June 17, 2021
Introduction
YugabyteDB is built primarily to be a CP database per the CAP theorem. It supports two interfaces – YSQL for SQL workloads and YCQL for Cassandra-like workloads. In this blog, we will primarily talk about the YCQL interface. When an application interacts with the database using the YCQL interface, the writes are always consistent and reads are consistent by default. When this level of consistency is not required, YugabyteDB supports two other types of reads:
1. Follower reads support spreading the read workload across all replicas that host the data.
2. Observer reads are accomplished by adding another set of replicas called read replicas. These replicas get their data replicated to them asynchronously. This has a couple of advantages. First, the read workload can be completely offloaded from the primary cluster. Second, the read replicas are created as a separate cluster which can be located in a completely different region potentially closer to the consumers of that data. This means low latency access to far off users as well as potentially tuning this Read Replica cluster to be more suitable to support analytics workloads.
A Yugabyte universe can have one primary cluster and a number of read replica clusters. With both follower reads and observer (read replica) reads, stale reads are possible with an upper bound on the amount of staleness. Also, both reads are guaranteed to be timeline-consistent. From an application perspective, you need to set the consistency level to ONE to get either of these types of reads. You also need to set the application’s local datacenter to the read replica cluster’s region for observer reads. The following demo takes you on a tour of how all this works.
Demo
The following script assumes that you have downloaded YugabyteDB and set it up as described here. I use a workload generator developed by Yugabyte as the client application.
A note on terminology used in the following sections – YugabyteDB organizes database nodes into zones and regions whereas Cassandra organizes nodes into racks and datacenters. I’ll use the term “region” when talking from the YugabyteDB perspective and “datacenter” when talking from the application perspective.
We will start by setting up a 3 node primary cluster in cloud c, region r and zones z1, z2 and z3.

With the following command, we tell the masters that we will have 3 replicas for each tablet distributed across these three zones.
./bin/yb-admin -master_addresses 127.0.0.1:7100,127.0.0.2:7100,127.0.0.3:7100 modify_placement_info c.r.z1,c.r.z2,c.r.z3 3 live
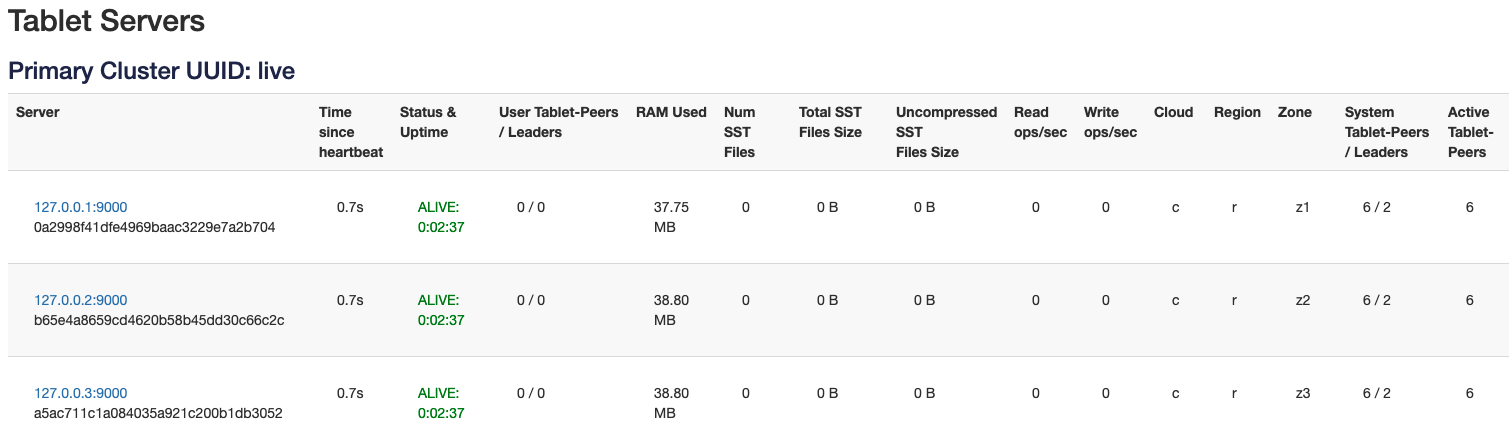
Now, let’s run the sample application and start a YCQL workload.

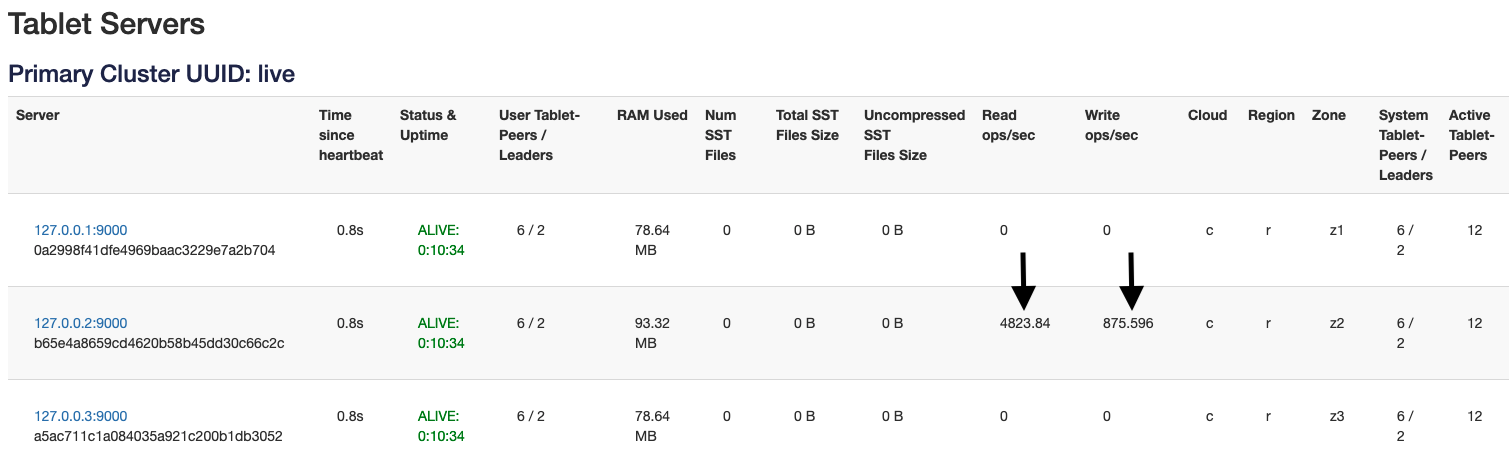
As you can see in the picture above, with a default workload both reads and writes go to the tablet leader. In the sample app command above I’m explicitly restricting the number of keys to be written (and read) to only 1 so that we can follow the reads/writes that are happening on a single tablet. If we used multiple keys, then, since different nodes are likely to have leaders for these keys it would be a bit more difficult to illustrate the point I am trying to make.
Now we will change the sample app command line to allow follower reads. Specifying --local_reads below essentially changes the consistency level to ONE (as shown in code here). The option --with_local_dc specifies the datacenter the application is in. When this option is specified, the read traffic is routed to the same region (as shown in the code here).
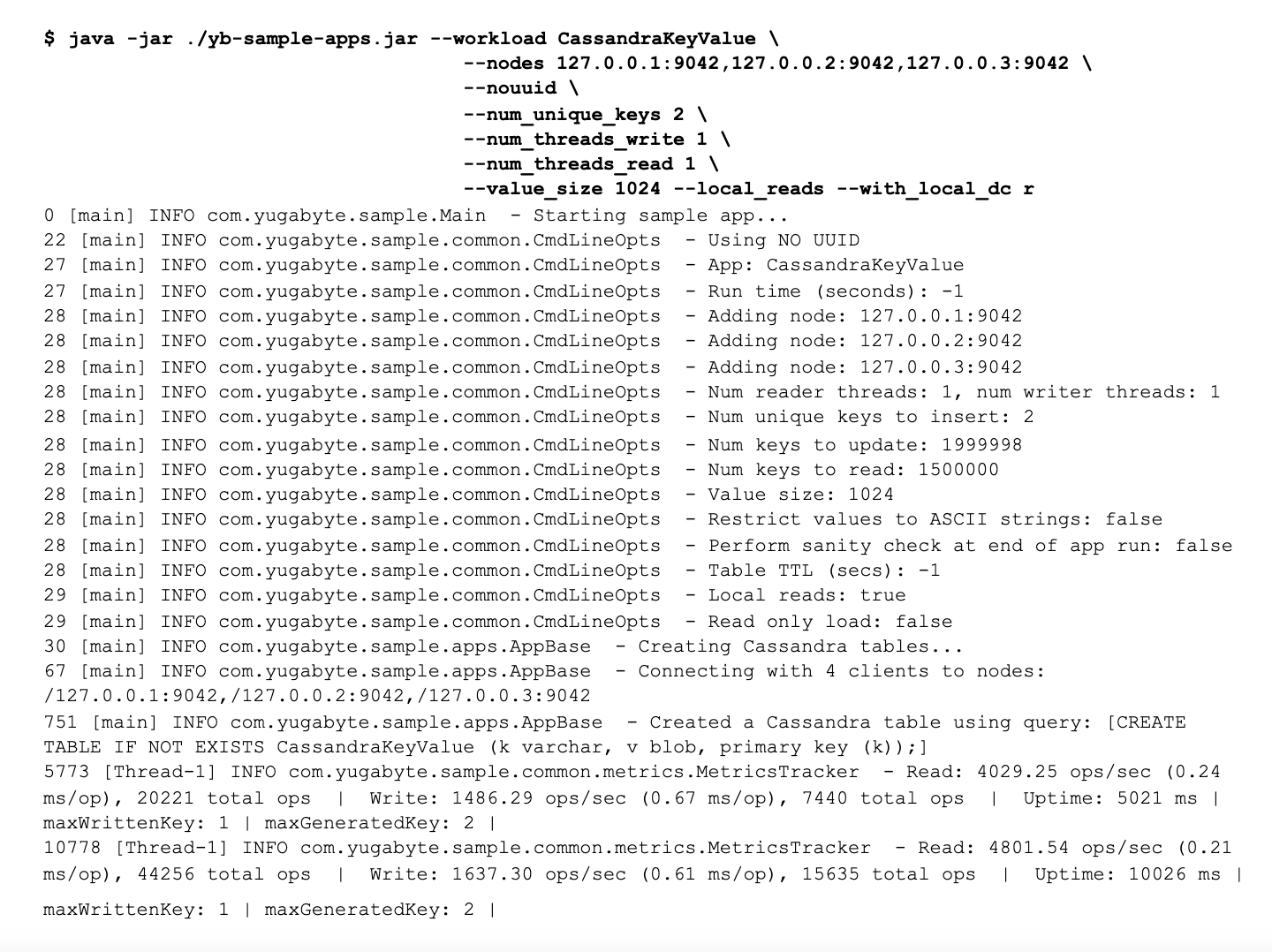
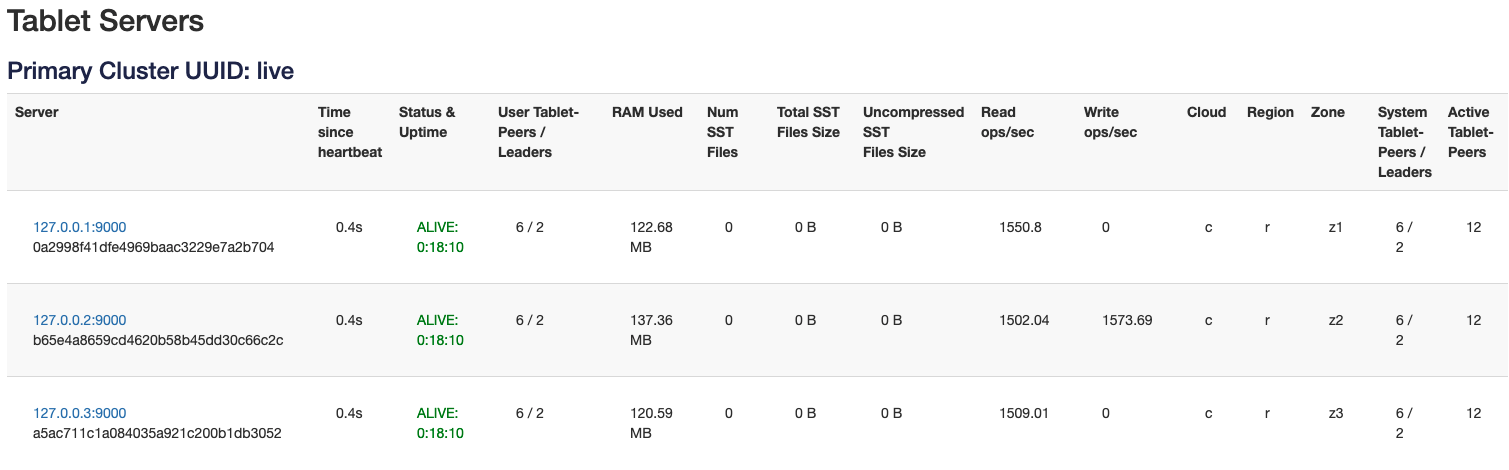
As you can see, now the reads are spread out across all the replicas for that tablet. Now let’s show you how to work with observer reads using read replicas.
The following commands add three new nodes and add them to a read replica cluster in region ‘r2’.

With this setup we’re now able to direct our CL.ONE reads to either the primary cluster (follower reads) in region ‘r’ or read replica cluster (observer reads) in region ‘r2’.

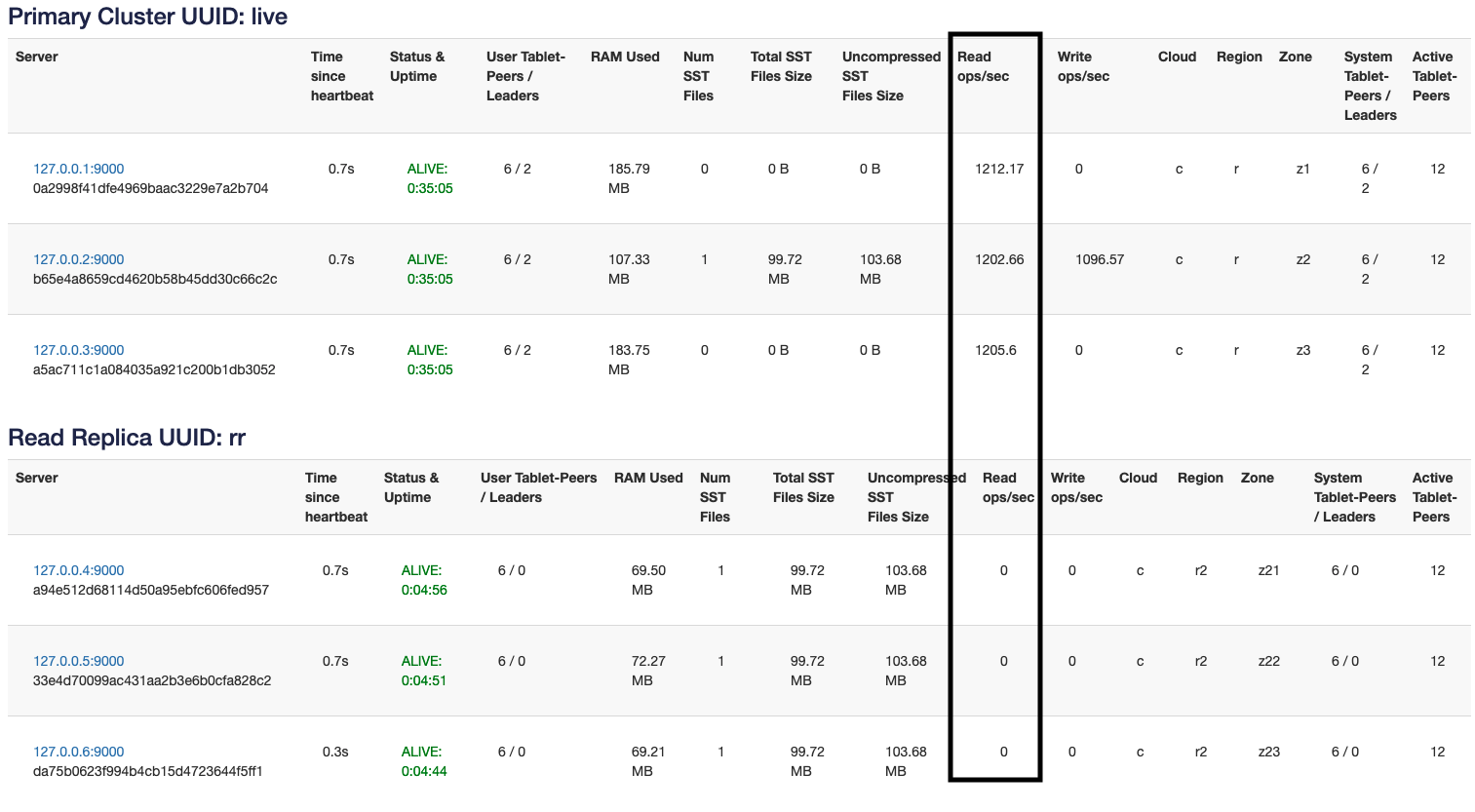

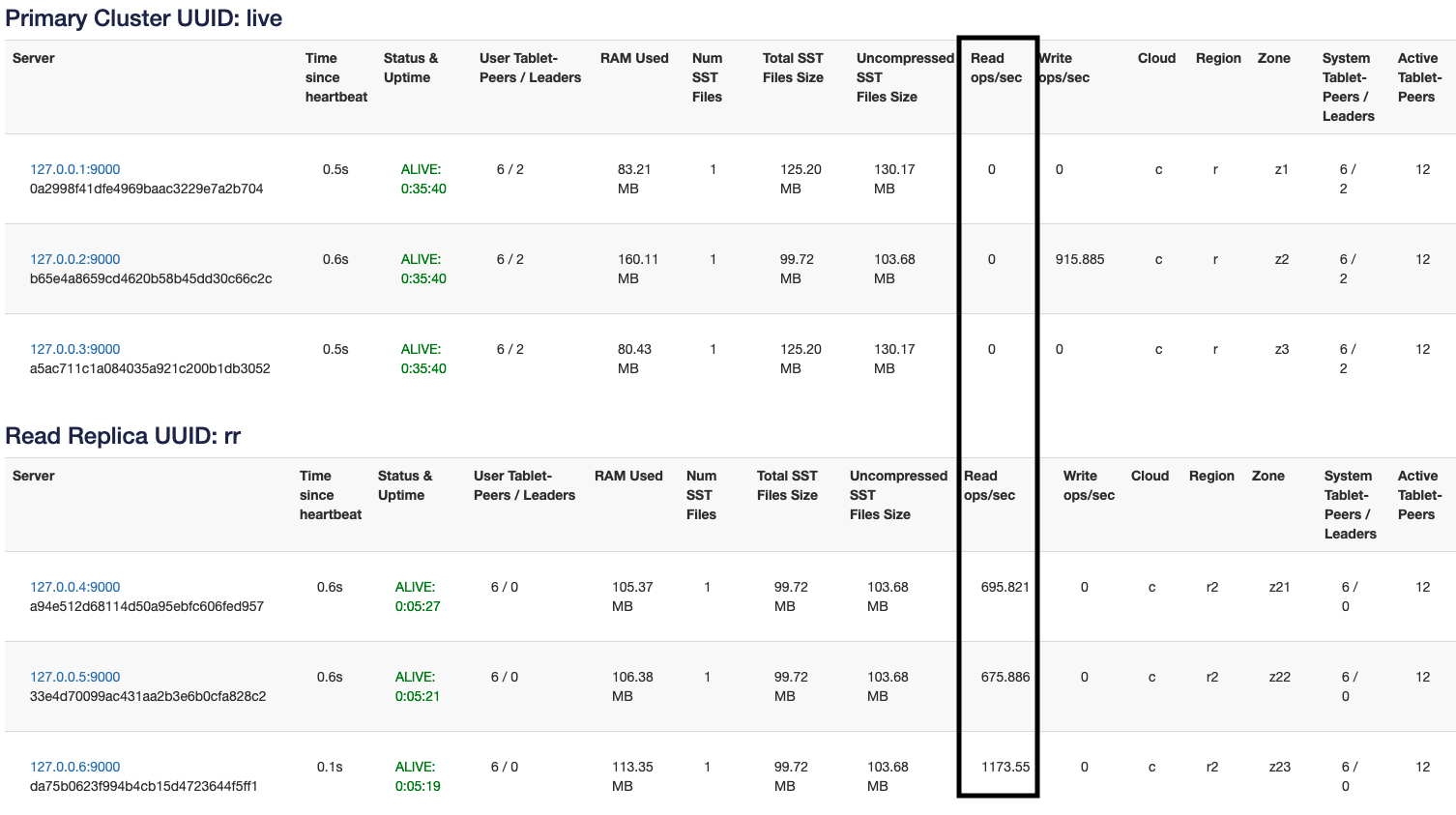
Fault Tolerance
In the default (strong) consistency mode, the only real way to tolerate more failures is to increase the number of replicas. If you want to tolerate k failures, you need 2k+1 replicas in the RAFT group. However, follower reads and observer reads can provide Cassandra CL.ONE style fault tolerance. An important GFlag to keep in mind is max_stale_read_bound_time_ms. This controls how far behind the followers are allowed to get before they redirect reads back to the RAFT leader. The default for this is 60s. For “write once, read many times” kind of workloads it might make sense to increase this to a higher value. Let’s continue our demonstration by stopping nodes and seeing how follower/observer reads behave.
I’ll start by starting a read only workload.

And stop a node in the Read Replica cluster using the following command.
./bin/yb-ctl stop_node 6
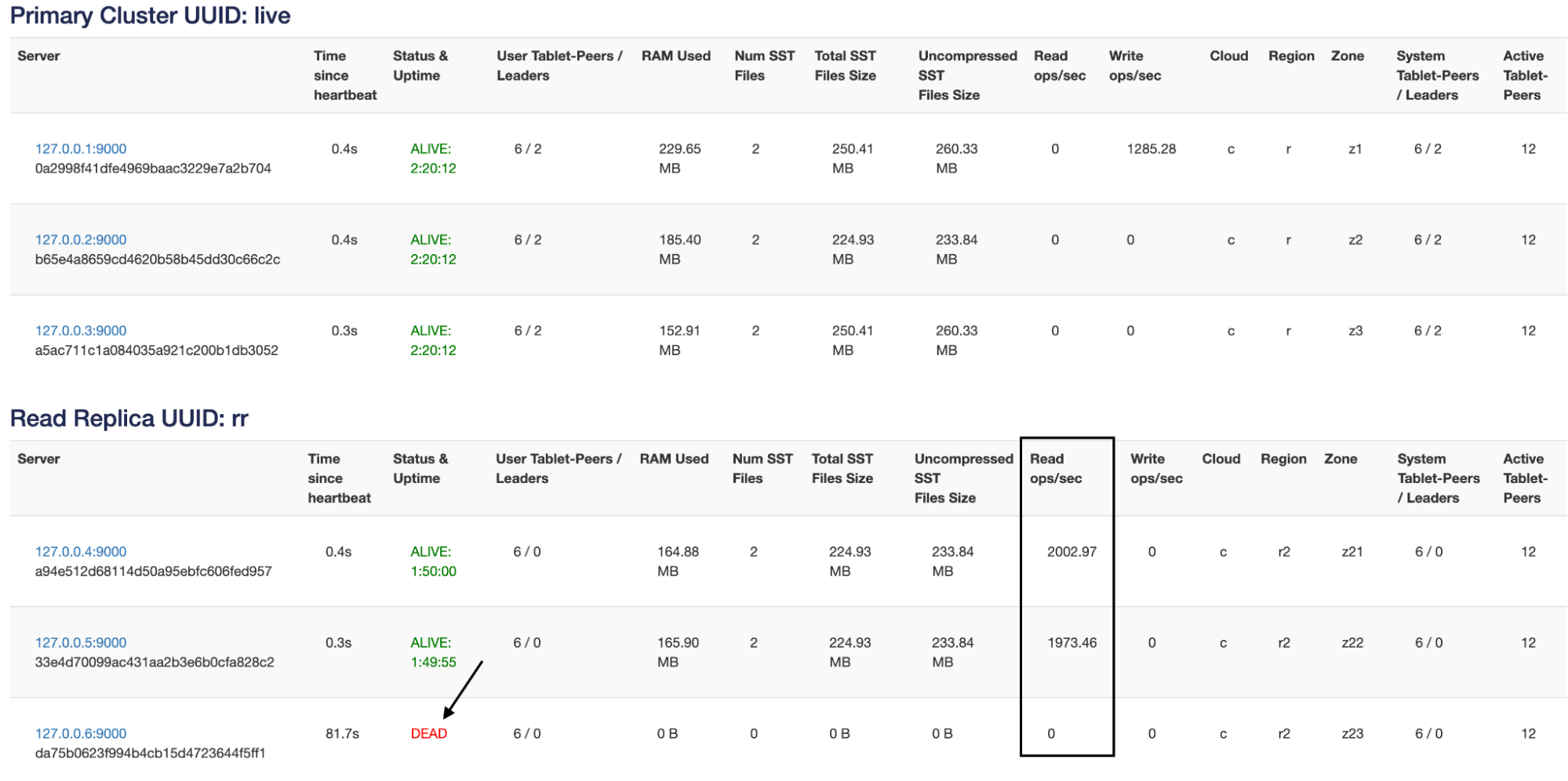
Killing one node just redistributes the load onto the two remaining nodes. Let’s kill one more node in the read replica cluster.
./bin/yb-ctl stop_node 5
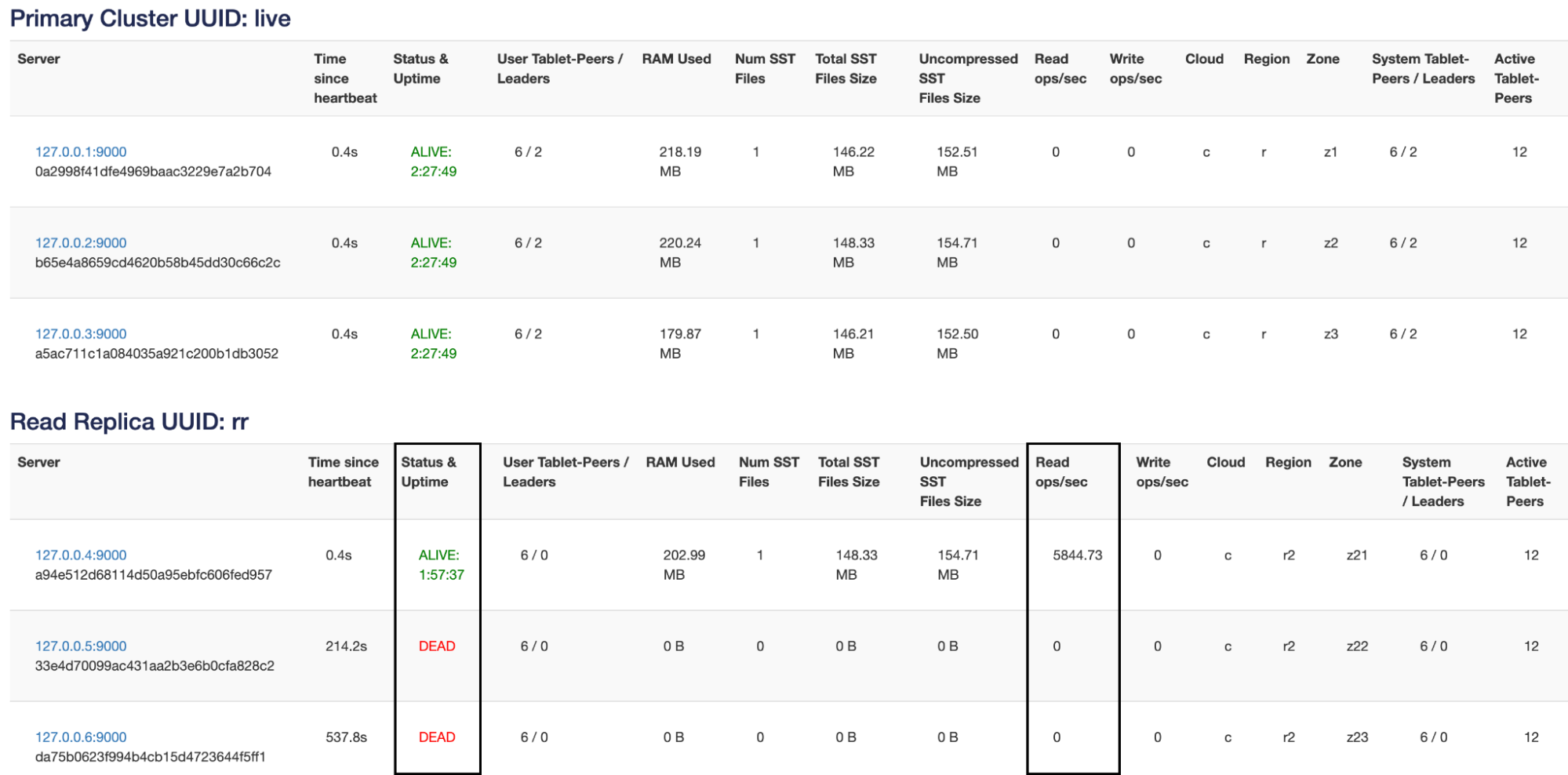
Now, if I kill the last read replica in this cluster, the reads revert back to the primary cluster and become follower reads as shown below.
./bin/yb-ctl stop_node 4
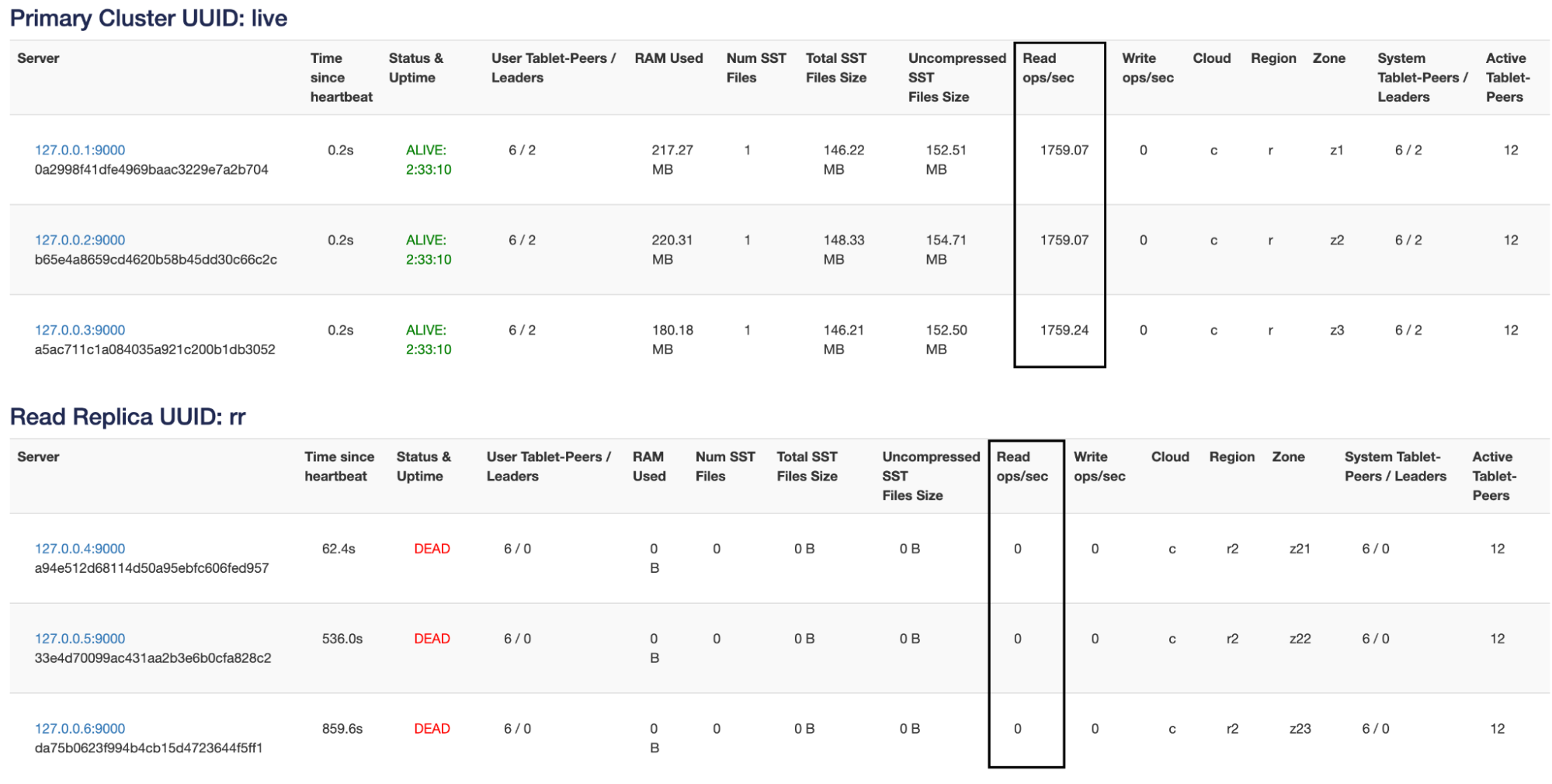
This behavior differs from standard Cassandra behavior. The YCQL interface only honors consistency level ONE. All other consistency levels are converted to QUORUM including LOCAL_ONE. When a local datacenter is specified by the application along with consistency level ONE, read traffic is localized to that region as long as that region has live replicas. If the application’s local datacenter has no replicas, the read traffic is routed to the primary region. Also different semantics apply once the switch happens from observer reads to follower reads as discussed above.
Let’s continue killing nodes and see FT behavior under the follower reads scenario.
./bin/yb-ctl stop_node 3
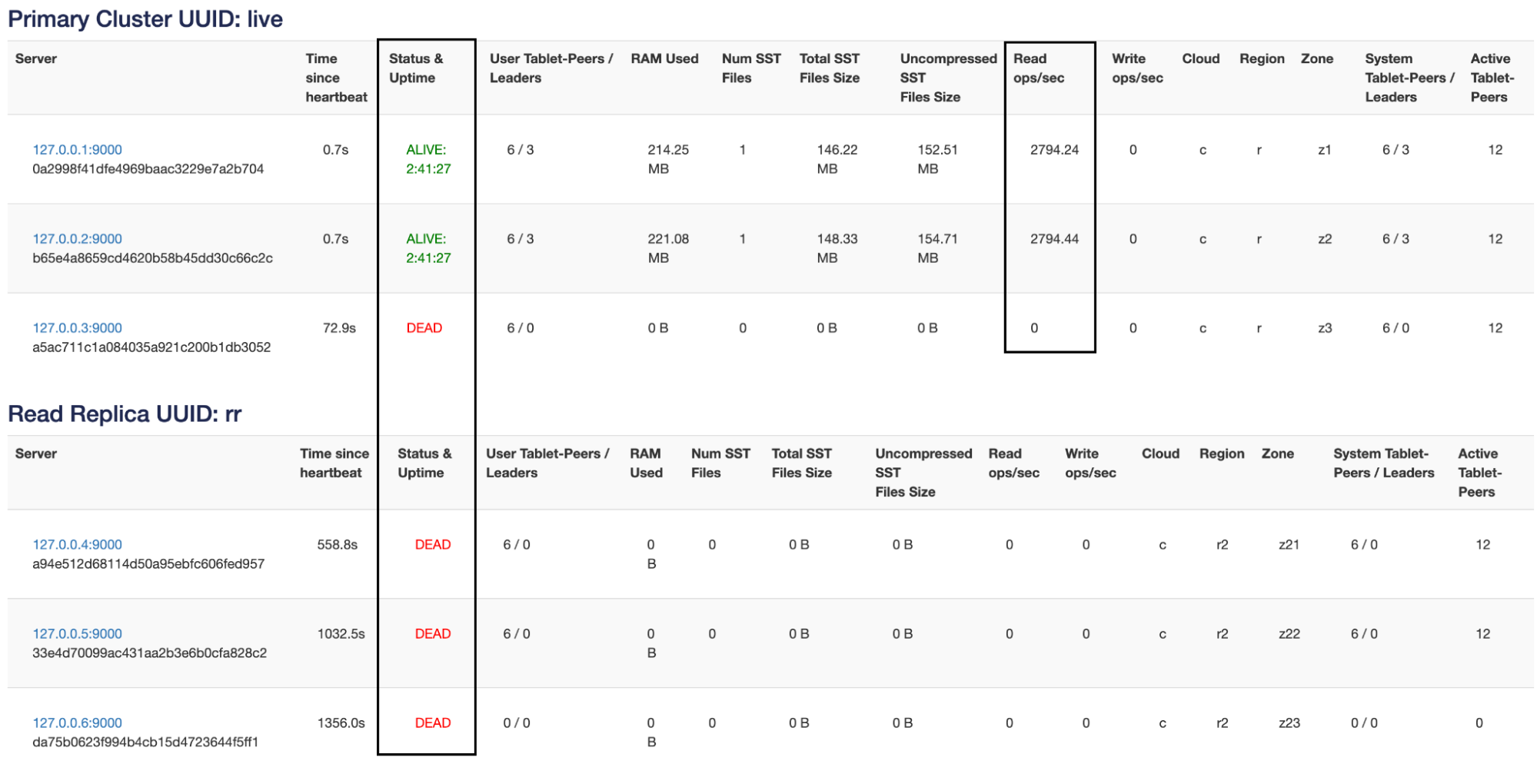
As we can see in the screenshot above, when we kill the third node, its read load gets rebalanced on to the remaining nodes.
./bin/yb-ctl stop_node 2
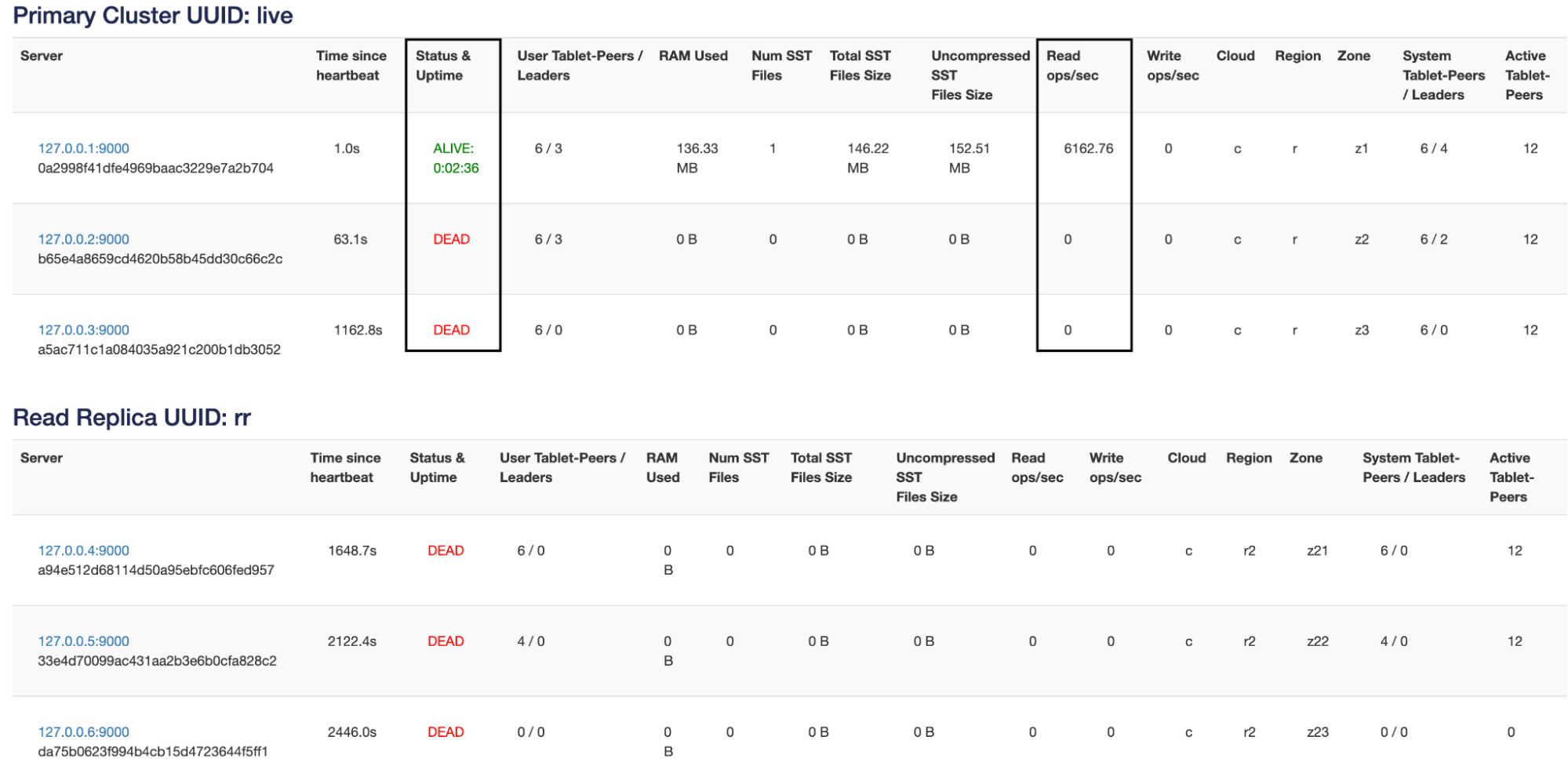
From the above screenshot we can see that the entire read load has now moved to the one node that is still up.
Conclusion
YugabyteDB provides consistent reads by default, but when the use case doesn’t need high consistency you have the option of using either follower reads or observer reads. Both provide slightly stale but timeline-consistent data access to increase performance and fault tolerance for those use cases.
Ready to start exploring YugabyteDB features? Getting up and running locally on your laptop is fast. Visit our quickstart page to get started.


