Streaming Changes From YugabyteDB to Downstream Databases
May 19, 2022
In this blog post, we will stream data to downstream databases leveraging YugabyteDB’s Change Data Capture (CDC) feature introduced in YugabyteDB 2.13. This will publish the changes to Kafka and then stream those changes to databases like MySQL, PostgreSQL, and Elasticsearch.
YugabyteDB CDC Downstream Databases Topology
The diagram below represents how data will flow from YugabyteDB to Kafka and then further to the sink databases.
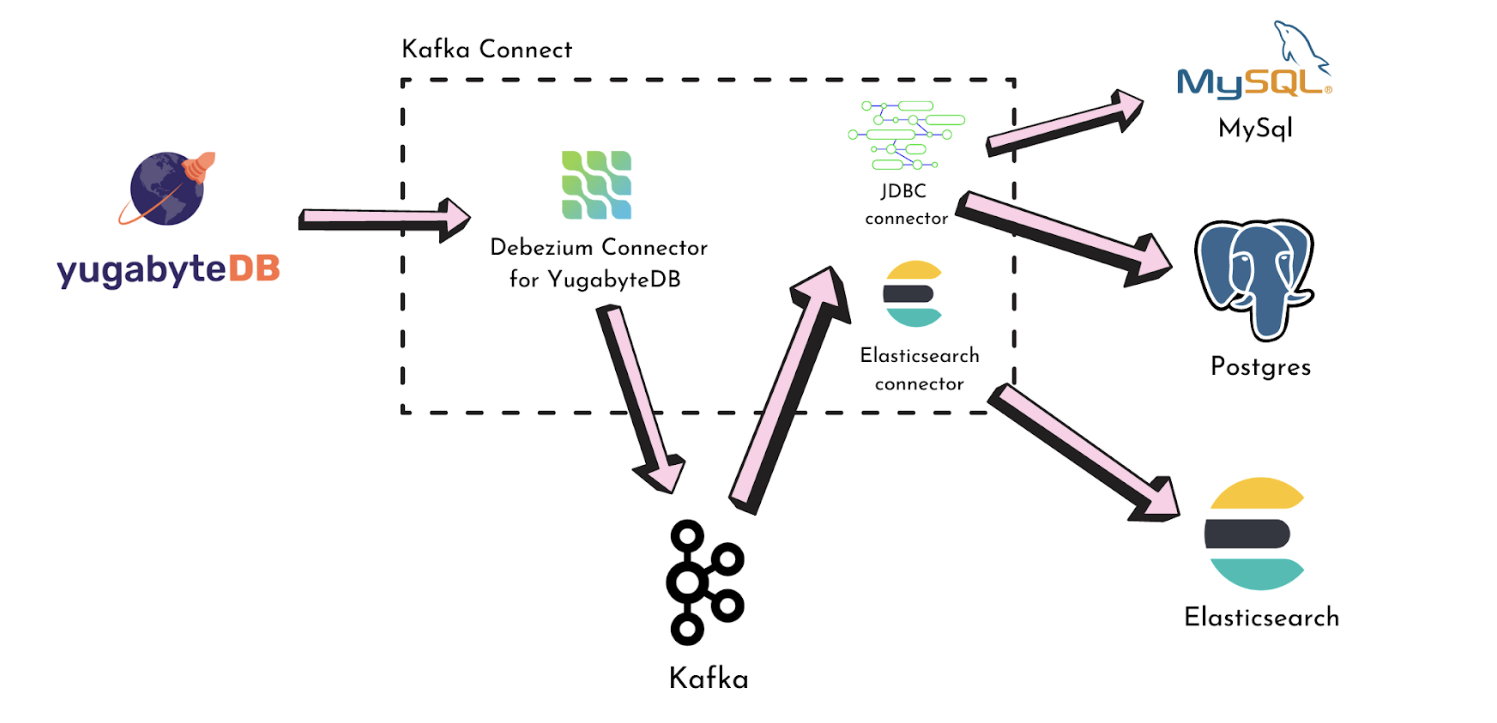
Specifically, the Debezium Connector for YugabyteDB continuously captures the changes from YugabyteDB and publishes them to a separate Kafka topic for each table. Finally, the JDBC Sink connector reads the data from the topics and puts them into the sink depending on how it is configured.
YugabyteDB CDC Downstream Databases Example
In this example, we will deploy all the connectors to a single Kafka Connect instance that will write and read from Kafka in order to further push data to downstream sinks.
- For starters, clone the repository from GitHub:
git clone git@github.com:vaibhav-yb/yb-dbz-blog.git
- Navigate to the cloned repository and start the Docker containers using the
docker-compose-init.yamlfile:cd yb-dbz-blog && docker-compose -f docker-compose-init.yaml up -d --force-recreate
Now that all the components have started, we will begin to deploy the required connectors.
- Next, login to ysqlsh:
docker exec -it yb-tserver sh -c 'exec bin/ysqlsh -h yb-tserver'
Create a table:
CREATE TABLE demo (id INT PRIMARY KEY, name TEXT, email VARCHAR(100));
- Create a stream ID:
docker exec -it yb-master sh -c 'exec bin/yb-admin --master_addresses yb-master create_change_data_stream ysql.yugabyte'
Copy the stream ID the above command is producing.
- Now you can deploy the plugin. But make sure to change the stream ID in the following command:
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d '{ "name": "ybconnector", "config": { "tasks.max":"1", "connector.class": "io.debezium.connector.yugabytedb.YugabyteDBConnector", "database.hostname":"yb-tserver", "database.master.addresses":"yb-master:7100", "database.port":"5433", "database.user": "yugabyte", "database.password":"yugabyte", "database.dbname":"yugabyte", "database.server.name": "dbserver1", "snapshot.mode":"never", "database.streamid":"7be2f4e5ac87488fb34e324135d28cad", "table.include.list":"public.demo" } }'
Deploying the PostgreSQL sink connector
- Next, deploy the sink connector for PostgreSQL:
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d @jdbc-sink-pg.json
The above deployed JSON file has the following content
{
"name": "jdbc-sink-pg",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "dbserver1.public.demo",
"dialect.name": "PostgreSqlDatabaseDialect",
"table.name.format": "demo",
"connection.url": "jdbc:postgresql://pg:5432/postgres?user=postgres&password=postgres&sslMode=require",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.connector.yugabytedb.transforms.YBExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false",
"auto.create": "true",
"insert.mode": "upsert",
"pk.fields": "id",
"pk.mode": "record_key",
"delete.enabled": "true",
"auto.evolve":"true"
}
}- The above JSON file is trying to set up a connector with the given configuration properties:
name: The logical name given to the sink connector.connector.class: The connector to use. We are using a JDBC sink connector in this example.topics: The topics to read the data from.dialect.name: The dialect to follow. This varies depending on the sink database being used.table.name.format: The name of the table in the sink database.transforms.unwrap.type: The transformer we need to use in order to make the Kafka message interpretable by the JDBC sink connector.auto.create: The ability to create a table in the sink database if it does not exist already.insert.mode: One of the various insert modes that the JDBC sink connector supports.pk.fields: Comma-separated list of columns that together make up the primary key.
You can read more about the JDBC Sink connector and its configuration options here.
Deploying the MySQL sink connector
- Next, deploy the sink connector for MySQL:
- Now this is a tricky step since you will need to create the target tables before deploying the sink connector.
- First, connect to mysql (Password:
debezium):docker exec -it mysql sh -c 'mysql -u root -p'
- Execute the following commands:
GRANT ALL PRIVILEGES ON *.* TO 'mysqluser'@'%' WITH GRANT OPTION; FLUSH PRIVILEGES; CREATE DATABASE test_api; USE test_api; CREATE TABLE demo (id INT PRIMARY KEY, name TEXT, email VARCHAR(100));
- Execute the following commands:
- Deploy the connector configuration:
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d @jdbc-sink-mysql.json
- Deploy the connector configuration:
Deploying the Elasticsearch sink connector
- Now deploy the sink connector for Elasticsearch:
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d @elastic-sink.json
Replicating data across all sinks with YugabyteDB
- You can now insert data into YugabyteDB and it will start replicating across all the sinks you have just configured. In your ysqlsh, execute the following commands:
INSERT INTO demo VALUES (1, 'Vaibhav', 'foo@bar.com'); INSERT INTO demo VALUES (2, 'Vaibhav', 'demo@yugabyte.com');
- Now go to your sinks one by one to confirm if the data is replicated:
PostgreSQL
You will need to connect to the PostgreSQL database first:
docker run --network=yb-dbz-blog_default -it --rm --name postgresqlterm --link pg:postgresql --rm postgres:11.2 sh -c 'exec psql -h pg -p "$POSTGRES_PORT_5432_TCP_PORT" -U postgres'
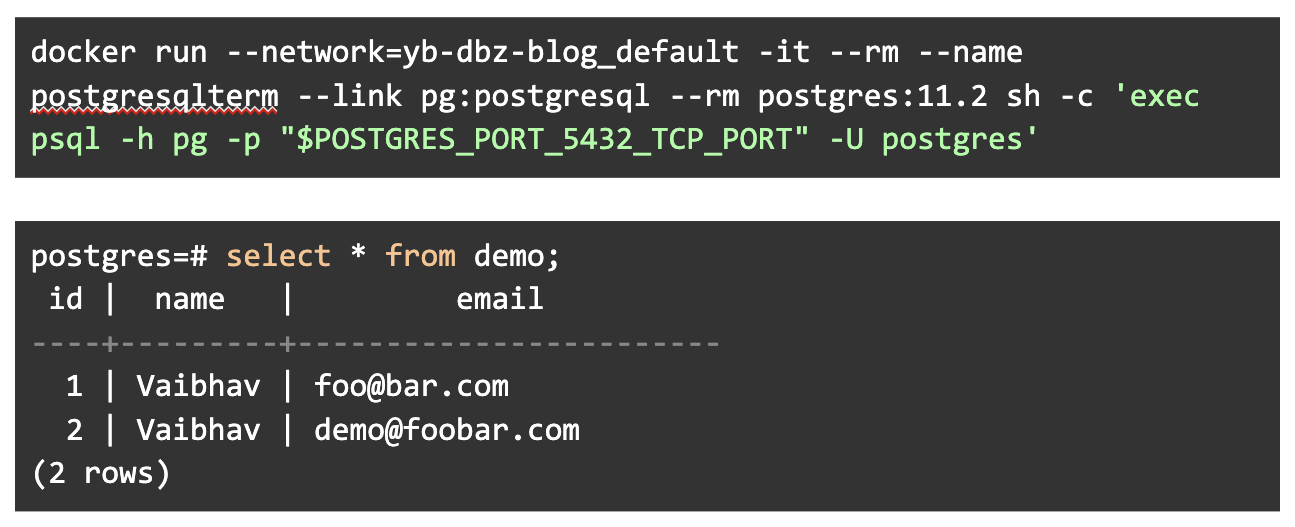
Then just check the data in PostgreSQL:
select * from demo;
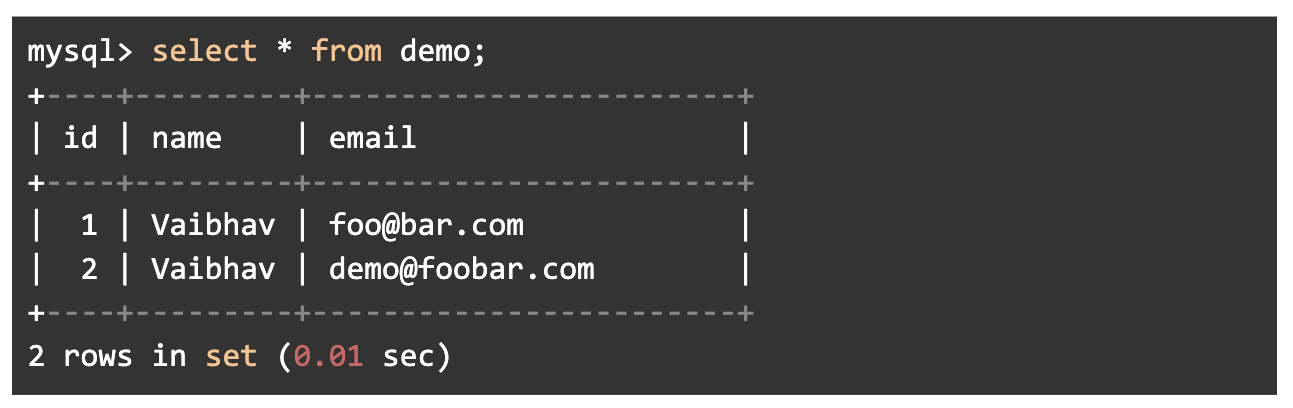
MySQL
select * from demo;
Elasticsearch
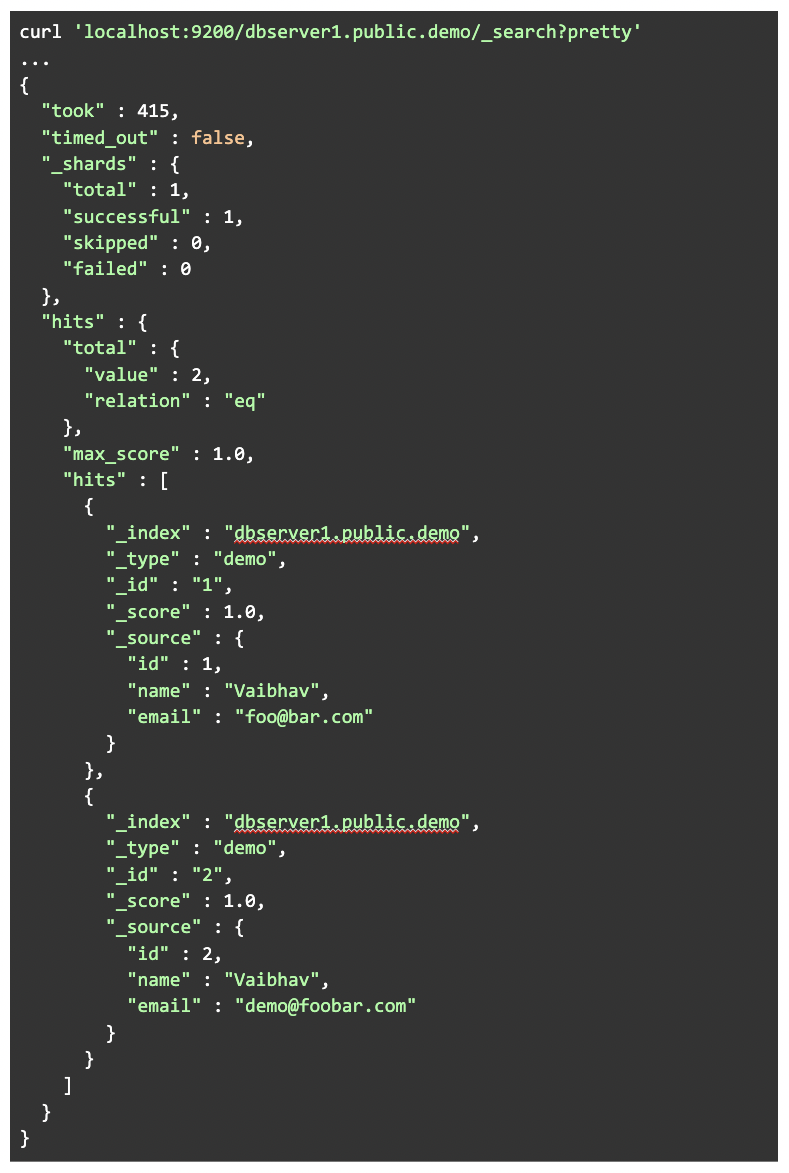
To check the data in ElasticSearch, execute:
curl 'localhost:9200/dbserver1.public.demo/_searcg?pretty'
Conclusion
In this post, we set up a complex pipeline to keep YugabyteDB in sync with other databases as well as an Elasticsearch instance. The identifiers and the names are kept the same across all the instances in order to maintain consistency and proper understanding.
Head over to Change Data Capture (CDC) to learn more about YugabyteDB CDC downstream databases. You can also join the YugabyteDB Community Slack channel for a deeper discussion with over 5,500 developers, engineers, and architects.

")
