Announcing YugabyteDB 2.13: Breakthrough Developer Experience and Performance
March 24, 2022
We are thrilled to announce the general availability of YugabyteDB 2.13. This is a major release that delivers better control over where geo-distributed deployments store and access data. More specifically, it allows enterprises to lower data transfer costs, improve performance, and ensure compliance with regulatory requirements. This release also includes new features and integrations to enhance developer experience.
YugabyteDB offers a rich set of deployment and replication options in geo-distributed environments. It allows users to build enterprise-ready applications that match their business needs and locations. YugabyteDB 2.13 extends the geo-distribution capabilities of the database with new features that enhance performance, increase control over backups, and intelligently utilize local data for reads.
New features of YugabyteDB 2.13 align around three key pillars of improvement:
- Accelerating and Optimizing Database Performance
- Enhance Developer Experience
- Extend Security and Compliance
In the rest of this post, we’ll share more details of these features. We’ll also reveal how they can help you develop world-class distributed applications.
YugabyteDB 2.13: Accelerating and Optimizing Database Performance
Cloud computing systems with geo-distributed resources are critical to a new family of applications that are latency sensitive or bandwidth-intensive. Examples of these workloads include online video gaming, home Internet of Things (IoT), autonomous vehicles, warehouse robotics, and more.
But YugabyteDB has a long history of providing leading choices for seamless, geo-distributed applications. This modern database already supports Row-Level Geo-Partitioning, where individual rows are optimized for access from different regions. The policy-based data controls enable hosting the cloud services at the network edges to reduce the latency and bandwidth consumption. It also divides a table and all of its indexes into partitions, with each partition optimized for access from a different region. And finally, users can store data in a single cloud region and then expand to multiple cloud regions as needed, as explained here.
YugabyteDB 2.13 adds new improvements to further embrace geo-distributed workloads.
Keep your data AND backups within cloud regions
YugabyteDB distributes and stores data within geographic regions to help organizations with data domiciling regulations such as the GDPR in Europe. We expect additional legal jurisdictions to pass similar laws in the coming year. As a result, modern database management systems must deliver simple, native functionality to assist in meeting new compliance requirements.
With the 2.13 release, organizations can now control where database backups are located by explicitly limiting them to specific geographic regions. Based on the data locality defined during the table creation, each TServer writes files only to the backup destination that matches the region configured.
In addition to meeting these data domiciling requirements, keeping the data within cloud regions reduces cloud data transfer costs by avoiding cross-regional data copying.
Better performance for region-local transactions
A “transaction status” table tracks the status of transactions. This table, under the covers, is just another sharded table in the system. However, it does not use RocksDB and instead stores all its data in memory, backed by the Raft WAL.
In order to achieve Atomicity in the ACID, along with data operations, we make transaction status changes also atomic. Because this transaction status table stored as global, it could become a bottleneck for transactions on geo-partitioned data.
In the 2.13 release, the global transaction status table is now optimized for access from different regions. Since the transaction status table is also geo partitioned, it eliminates the need for a round-trip to remote regions and reduces query latency by keeping relevant metadata close to users. YugabyteDB automatically creates a transaction status table using the user’s table placement information. However, you can also create a transaction status table. To do so, use the create transaction status command followed by modify_table_placement_info to set the placement information for the newly created transaction status table.
Locality optimized reads
The 2.13 release introduces a new YSQL function that, given a tableoid, returns whether the table is local in the region or not. The new function allows the query execution engine to avoid visiting remote regions if all of the requested keys live in the local region, thus reducing the latency of the query.
![]()
Since every row in a table has a system column that stores the tableoid of the table it belongs to, this function can easily restrict a query to the local partition in the WHERE clause. In a geo-partitioned setup, if there are no WHERE clause restrictions on the partition key, note that every query on a partitioned table gets fanned out to all of its partitions or regions:
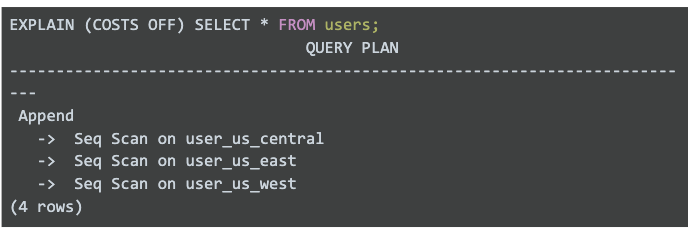
Assuming our client is in us-west, note that using yb_is_local_table in the WHERE clause causes YSQL to only scan the us_user_west_table.
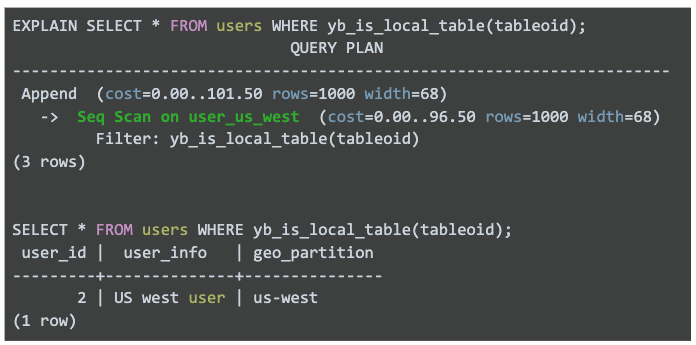
The function can also exist in join queries involving the following types of join queries:
- Join between geo partitioned and regular table
- Join between two geo partitioned tables
Materialized Views
A materialized view is a pre-computed data set derived from a query specification and stored for later use. Because the data is pre-computed, querying a materialized view directly is faster than executing a query against the base table of the view. They can also significantly improve the performance of workloads that have the characteristic of common and repeated queries. Please refer to documentation on how to use Materialized views.
Materialized views recompute in the background when the base tables change. Therefore, any incremental data changes from the base tables are automatically added to the materialized views. Materialized views return fresh data. If changes to base tables might invalidate the materialized view, then data reads directly from the base tables. If the changes to the base tables do not invalidate the materialized view, then the rest of the data reads from the materialized view and only the changes read from the base tables.
150K TPC-C Benchmark
YugabyteDB can now scale up to 1.91M tpmC with 150,000 warehouses, resulting in an efficiency score of 99.29%. This table shows YugabyteDB’s TPC-C performance benchmarking results.

YugabyteDB 2.13: Enhance Developer Experience
Yugabyte delivers the most developer-friendly database. The latest YugabyteDB 2.13 release continues this commitment with several new enhancements and capabilities to help developers accelerate their onboarding and leverage familiar, proven tools.
Quick Database access with YugabyteDB Cloud Shell
With the new YugabyteDB Cloud Shell, developers can connect to YugabyteDB using any modern browser. The Cloud Shell delivers a seamless user experience without compromising on data security.
Developers can experience the new cloud shell through self-paced courses in Yugabyte University as well as through hands-on tutorials in YugabyteDB.
Yugabyte University provides a free, engaging online curriculum for developers to learn YugabyteDB in a structured environment with opportunities for hands-on experience. If you are new to Yugabyte University, sign up today.
Change Data Capture (CDC)
Change data capture (CDC) allows multiple downstream apps and services to consume the continuous and never-ending stream(s) of changes to Yugabyte databases. Streams scale to any YugabyteDB cluster independent of its size. They also impact production traffic as little as possible.
Types of data changes captured include all the row changes (Inserts, Updates, Deletes) as well as metadata changes like the creation, modification and/or removal of database objects columns and tables using the DDL. Each CDC event is completely self-describing. An event’s key and value each contain a payload with the actual information and a schema that fully describes the structure of the information, along with the origin cluster information. Please follow the documentation to set up CDC.
How does CDC provide consistency semantics?
- Per-tablet ordered delivery guarantee – All changes for rows in the same tablet process in the order in which they happened.
- At-least once delivery – In case of failures that lead to message loss or take too long to recover from, messages retransmit to assure at-least-once delivery. More specifically, this means the potential for duplicated messages.
- No gaps in the change stream – There is a guarantee at all times that receiving any change implies all older changes have been received for a row.
Simplified Application Deployment
Developers have access to fully automated, integrated cloud-native development workflows that can be pre-configured with YugabyteDB using cloud-based developer environments, Gitpod and GitHub Codespaces.
- Use GitHub Codespaces to provision an instant development environment with a pre-configured YugabyteDB. Codespaces is a configurable cloud development environment accessible via a browser or through a local Visual Studio Code editor. Follow the steps on this page to set up a Codespaces environment with a pre-configured YugabyteDB.
- Use Gitpod workspaces to provision an instant development environment with a pre-configured YugabyteDB. Gitpod is a configurable ready-to-code cloud development environment accessible via a browser. Follow the steps on this page to set up a Gitpod workspace environment with a pre-configured YugabyteDB.
New Developer Tools
Support for MyBatis and Dapper ORM tools allows developers to leverage new .NET and Java persistence frameworks to simplify building applications with YugabyteDB.
- MyBatis: MyBatis is a first class persistence framework with support for custom SQL, stored procedures and advanced mappings. MyBatis eliminates almost all of the JDBC code and manual setting of parameters and retrieval of results.
- Dapper: Dapper is an object–relational mapping product for the Microsoft .NET platform: it provides a framework for mapping an object-oriented domain model to a traditional relational database. Its purpose is to relieve the developer from a significant portion of relational data persistence-related programming tasks.
YugabyteDB 2.13: Extend Security and Compliance
Yugabyte has successfully completed a System and Organization Controls (SOC)® 2 examination in accordance with the American Institute of Certified Public Accountants Security, Availability, and Confidentiality Trust Services Categories and applicable Criteria. More specifically, this accreditation confirms Yugabyte’s commitment to providing detailed information and assurance about security controls as they relate to our SaaS system.
Security Partnerships
Yugabyte 2.13 also includes the enhanced security and improved manageability capabilities built through Yugabyte’s deep partnerships.
- HashiCorp Vault: Use industry-favorite Hashicorp Vault with YugabyteDB to enjoy a centralized, cloud-agnostic key management system (KMS) with secure access to secrets.
- Imperva Cloud Data Protection: Utilize out-of-the-box support to simplify monitoring and tracking of data in YugabyteDB for audits and vulnerability detection.
What’s Coming – Roadmap
At Yugabyte, we strive to be fully transparent with our customers and user community. To that end, we always share our product roadmap, which contains numerous planned database features. Additionally, the Yugabyte team continually looks for ways to unlock even greater database performance. Below are some notable features planned for upcoming releases. However, please note that the current roadmap is subject to change as we finalize our planning for the next releases.
- Database-level multi-tenancy – Multi-tenancy support which isolates tenants on a per-database level.
- Faster Bulk-Data Loading – Improvements to make it easier and faster to get large amounts of data into YugabyteDB.
- Support for pessimistic locking – Pessimistic locking is desirable to have the database wait for existing transactions (that might otherwise conflict) to complete before making progress.
- Upgrade to PostgreSQL 13 – Support latest version of PostgreSQL to provide the latest features, extensions, performance, community fixes, and more.
- xCluster Replication – Atomicity of replicated transactions
- xCluster Replication – Support for manual propagation of DDLs
- Migration Engine – Simplify migration from PostgreSQL, MySQL, or Oracle to YugabyteDB.
Get Started
We’re thrilled to be able to deliver these enterprise-grade features in the newest version of our flagship product – YugabyteDB 2.13. We invite you to learn more and try it out:
- YugabyteDB 2.13 is available to download. You can install the release in just a few minutes.
- Finally, join us in Slack for interactions with the broader YugabyteDB community and real-time discussions with our engineering teams.
NOTE: Following YugabyteDB release versioning standards, YugabyteDB 2.13 is a preview release. Many of these features are now generally available in our latest stable release, YugabyteDB 2.14.


