The Rise of Streaming Data: The Right Architecture to Transform Analytics, Disaster Recovery, and IoT
January 4, 2024
When planning your real-time data architecture, a fundamental decision is choosing between streaming or batch processing. This choice is crucial since it determines the data movement pattern – batch/micro-batch or streaming – which influences the design of the systems that process your data and the applications that rely on them.
Batch/Micro-batch Patterns
If you’ve worked with data warehouses or are doing analytical work, you’re probably familiar with the concept of batch or micro-batch patterns. Both involve moving data sets either on demand or according to a schedule. Batch patterns are often used for backup and restore (i.e. making sure that you can recover your data after a data loss). Another use is import / export, where data is pulled from one system or database and then imported into another. The most common use for a batch/micro-batch pattern is extract, transform, and load (ETL) or extract, load, and transform (ELT).
Streaming Patterns
The second pattern for a real-time data architecture, which has gained prominence over the last decade and a half, is streaming. What characterizes a streaming pattern is the continuous flow of data generated, which can come from one (or many) data sources. Some common reasons to use a streaming pattern include data replication (both physical and logical), change data capture, and real-time analysis from the Internet of Things (IoT), where devices constantly emit data that needs to be collected and processed.

Think of streaming data as a flowing current of water. You have to manage the entirety of it in real time…as it flows. In batch processing, data is collected—much like water in a bucket—stored and then moved for processing/analysis.
Why is Streaming Data Important?
Streaming data is extremely important, primarily due to three key use cases.
- Disaster recovery and migration. Many customers want to maintain a secondary environment for failover purposes, and they want this environment to remain synced with the primary up until the last point of change. In other words, they don’t want to lose any transactions; their recovery point objective (RPO) is zero or near zero. To achieve this, their source and replica systems must be in sync.
- Microservices application development. This use case is applicable when customers want more of an event-driven and decoupled pub/sub architecture. This development approach enables applications to process changes as events occur and process them in real-time or near real-time, rather than retrieving data on-demand from databases or data systems as directed by the user. It’s particularly effective for real-time dashboard applications.
- Near-real-time analytics and decision support. Traditional enterprise data systems, which aggregate data daily from source OLTP systems into data warehouses/data marts, are no longer sufficient. Businesses now require up-to-date information, often to the minute. For example, in an order application for a retail business, immediate awareness of low stock levels is necessary to replenish supplies promptly and maintain a great customer experience. The need for immediacy also feeds into analytic tools, dashboards, and alerting/notification systems. Real-time decision support is vital to swiftly make smart, informed decisions that can drive business strategies or revamp critical processes.
>>>Learn More: Real-Time Decision-Making: How Event Streaming is Changing the Game>>>
Architectures that Support Streaming Data
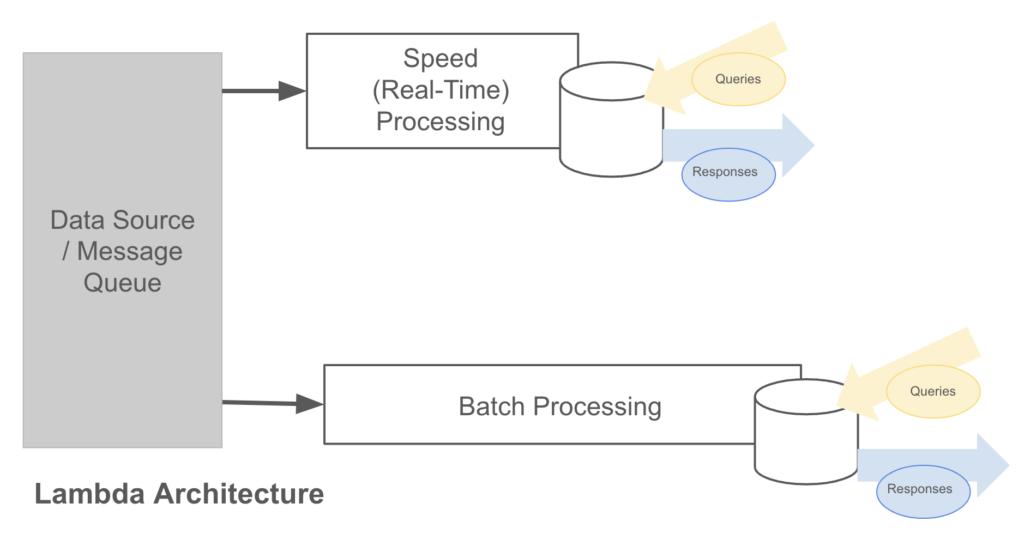
Traditional batch processing architectures no longer meet customer needs, so data architectures have evolved to support streaming data. In the past 10 to 15 years, there has been significant progress in this area. A notable development was the Lambda architecture pattern, which introduced two distinct data flow tiers: one for batch data and the other for real-time data flows.
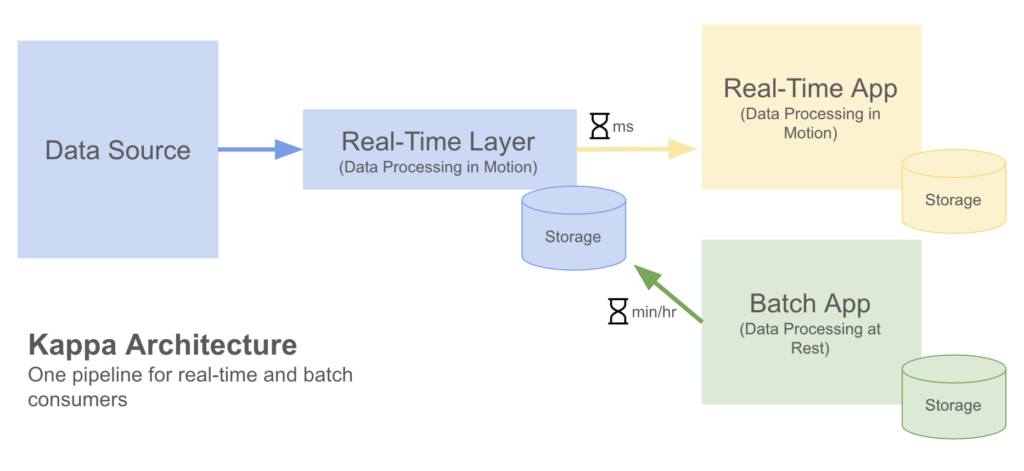
A newer and increasingly popular architecture model is the Kappa architecture. This architecture utilizes a single data source with a real-time data layer to process data in motion. From this, real-time needs are addressed by drawing directly from the data stream. Additionally, batch applications may either receive data downstream or extract it from storage.
YugabyteDB’s Support For Streaming Data Patterns
So how does YugabyteDB, fit into this? Well, as you know, YugabyteDB is a distributed transactional database that is runtime compatible with PostgreSQL. A lot of our customers use it as the system of record for their transactional applications.
The Yugabyte database aligns well with streaming data processes because its distributed, high-performance architecture aligns well with the high demands of streaming data architectures. Systems of record often need to monitor data engagement frequency, determine the current state of information, and track the speed of data changes. And YugabyteDB can readily meet those needs.
>>>Learn More: Unlocking the Power of Event Streaming with YugabyteDB: Real-World Use Cases>>>
In terms of the Internet of Things (IoT), most devices need a place to store the data they emit. It is often captured through a gateway architecture, pushed through some sort of messaging queue or messaging bus, and stored in a database. YugabyteDB is an ideal storage solution for that.
YugabyteDB also excels in handling high-throughput transactional workloads, where customers are looking to exponentially scale up their transaction processing in a distributed manner with low latency. Their goal? To ensure high resilience while capturing valuable analytics and metrics from rapidly changing data.
YugabyteDB supports streaming data through its change data capture (CDC) feature. Much like an IoT device that emits data as that data changes, YugabyteDB can emit data as changes occur in the database. Downstream systems can then consume this data.
The advantage of YugabyteDB lies in the separation of concerns inherent in a decoupled architecture.
Integrating a busy analytics system directly with a transactional database could hinder its performance and affect critical operations like order posting or transaction handling. By decoupling analytics, processing can occur elsewhere, while still providing the benefit of near real-time analytics in response to data changes. This approach enables YugabyteDB to offer both transactional efficiency and analytical decision-making while acting as a resilient system of reference. Essentially, it allows users to enjoy the best of both worlds within a streaming architecture.


