How a Fortune 500 Retailer Weathered a Regional Cloud Outage with YugabyteDB
August 16, 2023
In February 2021, Texas faced a snow-pocalypse that knocked out power for over 4.5 million homes and businesses. One of our largest retail customers’ public cloud data center was affected for four days, with even their backup generators failing.
This Fortune 500 retailer, with big box wholesale, discount department, and grocery stores, as well as a substantial ecommerce site, managed to prevent application downtime thanks to YugabyteDB. By geo-distributing its YugabyteDB cluster, the company maintained application availability during this massive regional failure. In this blog post, we’ll discuss how they achieved sustained availability.
The Power of Flexible Geo-Distributed Topologies to Build a Multi-Region Architecture
One of the less talked about benefits of the Yugabyte database is its flexibility of deployment. There are many different ways to set up a geo-distributed topology with YugabyteDB. You can run it on bare metal servers, virtual machines, or container technologies—like Kubernetes—either in your own data center or in the cloud.
Clusters can be spread across availability zones, regions, or even cloud providers. By default our clusters replicate data using synchronous replication, but you can also set asynchronous replication, read replicas, or xCluster replication.

Depending on your workloads, you can use our SQL API (YSQL), feature-compatible with PostgresSQL, or the NoSQL API (YCQL), wire-compatible with Cassandra.
These options meet users’ specific use cases and deployment needs. In the case of our retailer, they had two clusters, both with stringent requirements for the database to serve low latencies and be highly redundant across regions.
The Retailer’s Database Requirements
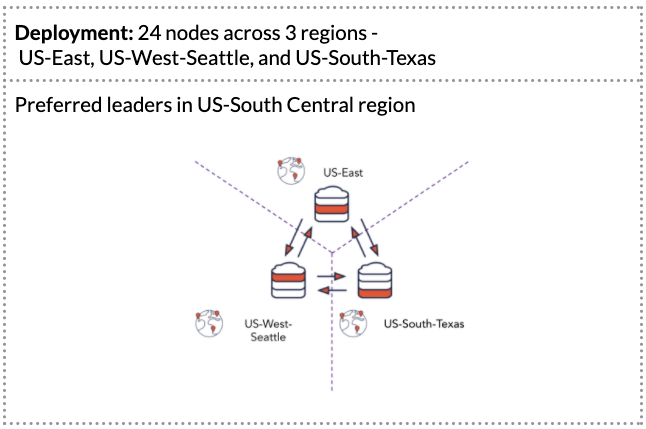
Displayed above is the retailer’s Cluster X which, at the time, had 24 nodes spread across multiple regions. The setup has a replication factor (RF) of 3, with 8 nodes in each region. This use case calls for low latency batch inserts of data overnight (e.g., product updates). The core requirements for this use case are zero downtime, handling massive concurrency and parallelism, as well as the ability to scale linearly.
We used the concept of preferred leader regions to move all of the main reads and writes to US-South. The remaining regions—US-West and US-East—are used for high availability.
A second production cluster—Cluster Y—has a similar configuration. The same regions are used with a total of 18 nodes, 6 in each region. Each node has 16 cores for a total of 288 cores. Combined, these two clusters run 42 nodes comprising 672 total cores. US-South was again used as the preferred leader region, serving reads and writes.
This use case serves downstream systems in the retailer’s systems portfolio with a requirement to serve single-digit low latency on a per-region basis. We implemented follower reads to meet this requirement. These allow you to read off of the local nodes without having to go to the preferred leader region. This provides more read IOPS with low latency, but they might have slightly stale yet timeline-consistent data (i.e., no out-of order-data is possible).
Given these configurations, both workloads are true multi-region cloud native deployments with the ability to scale up and down based on consumer demand. When the application tier scales, the backend scales along with it. This provides protection from any natural disaster that would cause the application to lose connection to its preferred leader region.
How YugabyteDB Remained Resilient and Highly Available During Texas Snowstorm
Had this retailer used the common multi-AZ deployment within the US-South region they would have faced significant problems. The two workloads mentioned above (Cluster X and Cluster Y) are crucial microservices in their application landscape. Cluster X acts as the system of record for their product catalog of 1.6 billion products. Cluster Y handles product mapping for 250k transactions per second at very low latency.
As Texas started to freeze over, electrical blackouts hit the state at an unprecedented rate. Companies with data centers in central Texas experienced connectivity issues, forcing them to scramble to make their data available to users.
When our retailer lost all their nodes in Texas without warning, their YugabyteDB cluster stayed up thanks to a design that allowed for immediate adaption. The database’s core features of strong consistency, rebalancing, and auto-sharding enabled this rapid response.
Let’s explore how YugabyteDB handled this crisis.
Sharding data
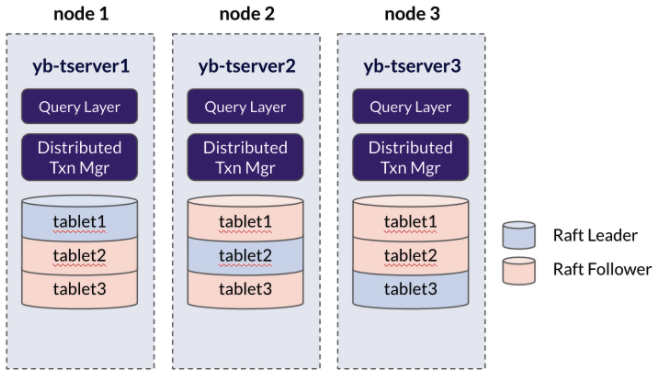
Tables in YugabyteDB break down into multiple sets of rows according to a specific sharding strategy. These shards—or tablets in YugabyteDB —are automatically distributed across the nodes in the cluster. Each shard/tablet replicates across the cluster a certain number of times based on the value that is set for the replication factor.
This replication factor directly correlates to the fault tolerance of the system. In the scenario visualized below, a cluster with 3 nodes and an RF of 3 can easily overcome the loss of a single node.
Maintaining Data Consistency
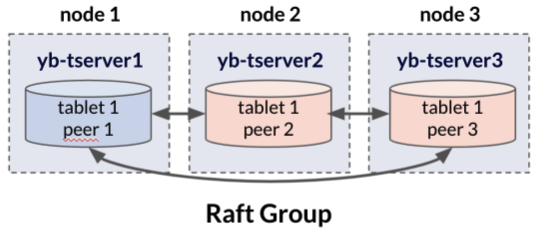
The Raft protocol is the consensus protocol that YugabyteDB uses to ensure ACID compliance across the cluster. Replicated tablets organize into a set of tablet-peers. They also form a strongly consistent Raft group composed of as many tablet-peers as the replication factor (i.e., if your replication factor is RF=3 then your Raft group will have 3 tablet-peers). The tablet-peers are hosted on different YB-Tservers, and—through the Raft protocol—perform actions such as leader election, failure detection, and replication of write-ahead logs.
Upon start-up, one of the tablet-peers is automatically elected as the tablet leader. This tablet leader is in the main tablet in the tablet-peer group. It serves all reads and writes for those specific rows.
Tablet followers are the remaining tablet-peers of the Raft group. Tablet followers replicate data and are available as hot standbys that can quickly take over if the leader fails. Although only the tablet leader can process reads and writes, YugabyteDB offers the ability to read from tablet followers for use cases that relax consistency guarantees in exchange for lower latencies.
Efficient Failover
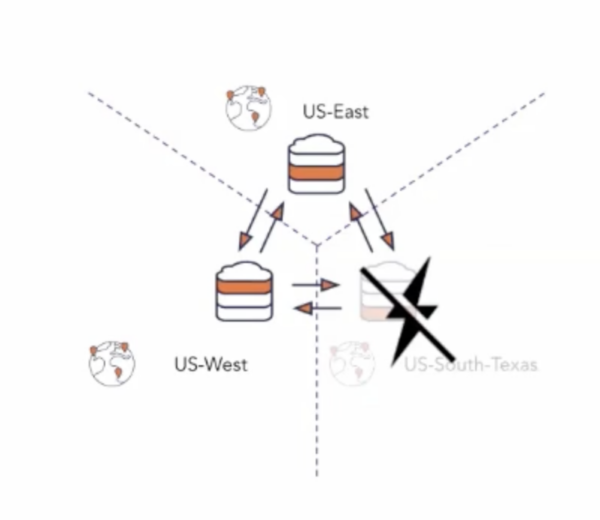
The retailer required that tablet leaders in the US-South region, serve both reads and writes across all tablets/shards. However, Cluster Y required low latency local reads. As a result, both US-West and US-East serve follower reads for local users.
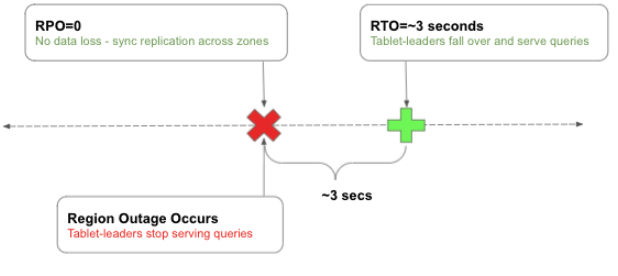
During the Texas power failure, traffic automatically rebalanced to US-East and US-West. The Yugabyte database automatically handled tablet leader re-election in approximately three seconds using the Raft protocol. YugabyteDB did all the heavy lifting.
In this case, it used the YCQL API’s smart capability to connect to additional regions—no human intervention was required. This yielded an RPO (Recovery Point Objective) of 0. This meant that no data was lost since safe copies were kept in the other regions. The time to rebalance and reconnect the connections was less than 10 seconds, with three seconds for re-establishing the leaders of the lost shards and the rest for re-establishing connections.
The retailer’s data placement policy made US-West the new preferred leader region, and its tablets became the new tablet-leaders. There was no data loss in the failover since the data existed in all three regions at the time of the outage (i.e., the cluster had a RF=3).
Once the downed nodes were back online, YugabyteDB automatically detected stale data in the newly-back-online nodes. The database then remotely bootstrapped the nodes with the correct data copy and started taking connections specific to Texas.
The Aftermath of the Winter Storm
This natural disaster was literally a worst-case scenario come to life for a global retailer. However, being proactive meant that our customer was prepared. By adopting YugabyteDB, their service remained resilient and available, even though all tablet-leaders were in a single region.
YugabyteDB handles sharding, replication, and failover transparently and performs all of the heavy lifting on your behalf. No human intervention is required to reshard or rebalance the database, resulting in considerable DevOps gains for the customer.
The retail industry, especially eCommerce, has brutal repercussions for downtime. Estimates show that revenue loss is approximately 10% of annual income per hour. Thanks to YugabyteDB’s continuous availability, with immediate hands-free failover, our customer avoided financial or reputational damage. Even when the retailer lost their preferred leader region, their application remained operational. Impressively, the YugabyteDB cluster self-healed when the nodes were restored, offering significant DevOps benefits.

Learn more about how this retailer architected their highly available and resilient data layer.


