YSQL Architecture: Implementing Distributed SQL in YugabyteDB
October 25, 2018
In this post, we will look at the architecture of YSQL, the PostgreSQL-compatible distributed SQL API in YugabyteDB. We will also touch on the current state of the project and the next steps in progress. Here is a quick overview:
- YugabyteDB has a common distributed storage engine that powers both SQL and NoSQL
- For supporting NoSQL apps, YugabyteDB is designed for low latency, sub-millisecond reads and massive write scalability. It can handle millions of requests and many TBs of data per node with linear scalability and high resilience.
- For supporting SQL, YugabyteDB is designed to support the ANSI SQL specification while being able to scale out and tolerate failures. Currently we are focused on PostgreSQL compatibility.
Since the distributed storage engine is common to SQL and NoSQL, you get the best of both worlds. Yugabyte SQL (YSQL) workloads should easily be able to achieve massive scale with high performance. Let us dive right into the details and take a look at how this is done.
YugabyteDB Basics
YugabyteDB is architected for fault tolerance, read and write scalability, and high performance. YugabyteDB clusters can support millions of read/write requests per second and handle many TBs of data per node. YugabyteDB is currently being used in production to store and serve business critical data by many customers for use-cases that require the capabilities mentioned above.
Let us look in brief at how YugabyteDB achieves this at its core storage layer, before we dive into the details of its distributed SQL implementation.
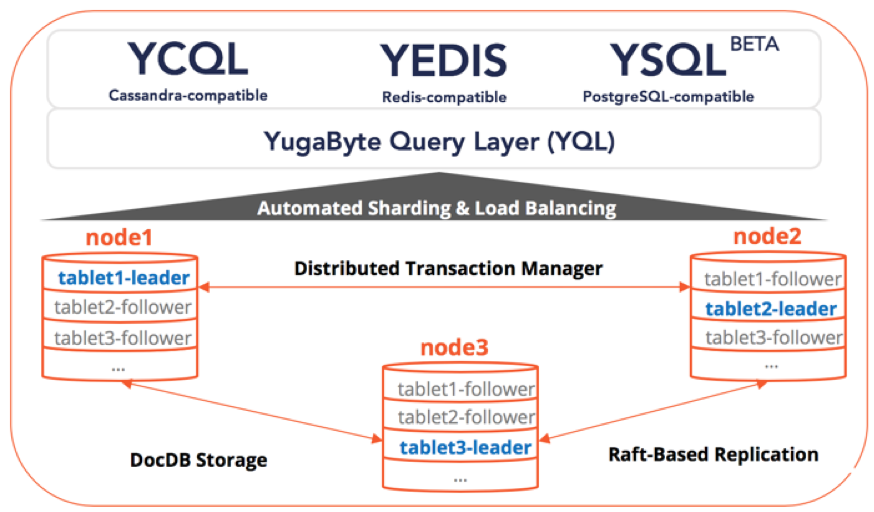
User tables are implicitly managed as multiple shards by the system. These shards are referred to as tablets.
⇨ Read more about automatic sharding of tables in YugabyteDB.
Replication of data in YugabyteDB is achieved at the level of tablets. Each tablet comprises of a set of tablet-peers – each of which stores one copy of the data belonging to the tablet. These tablet-peers form a Raft group to elect a leader and replicate data, ensuring consistency of data.
⇨ Read more about data replication in YugabyteDB with Raft consensus.
YugabyteDB internally uses DocDB as a persistent “key to object/document” store on each node. DocDB is YugaByte’s Log Structured Merge tree (LSM) based storage engine, that supports efficient, fine-grained attribute updates and lookups while handling many terabytes of data per node. Once data is replicated via Raft across a majority of the tablet-peers, it is applied to each tablet peer’s local DocDB.
⇨ Read more about DocDB features and architecture.
YugabyteDB supports a pluggable query layer called YQL (Yugabyte Query Layer). The YQL layer implements the server-side of multiple protocols/APIs that YugabyteDB supports. Currently, YugabyteDB natively supports Apache Cassandra and Redis wire-protocols for production usage, and this post talks about the PostgreSQL implementation which is currently in beta.
⇨ Read more about the query layer in YugabyteDB.
Distributed ACID transactions are transactions modifying multiple rows in more than one shard. YugabyteDB supports distributed transactions, enabling features such as strongly consistent secondary indexes and multi-table/row ACID operations in the YSQL context by forming the nucleus of full distributed ACID transactions in Postgres. The transactions support in YugabyteDB is designed to scale out linearly on demand.
⇨ Read more about distributed transactions in YugabyteDB.
Implementing YSQL, YugabyteDB’s Distributed SQL API
YSQL uses a good portion, in particular the upper-half, of the open source PostgreSQL 10.4 codebase (but integrated in a way to be able to easily rebase to newer versions, see the FAQ section). YugabyteDB is written in C++, which easily interoperates with the PostgreSQL codebase written in C. This means that it is possible to support most of the SQL functionality sooner by re-using an existing, mature codebase compared to reimplementing it from scratch.
A YugabyteDB cluster scales out PostgreSQL data as described in the sections below. This will result in the upper half of PostgreSQL (which is stateless and consists of components such as the query parser, rewriter, planner and optimizer) running on multiple nodes and storing data in a distributed fashion. This is shown in the architecture diagram below. Note that typically, a cluster with replication factor 3 can survive one node failure automatically and has at least 3 nodes.
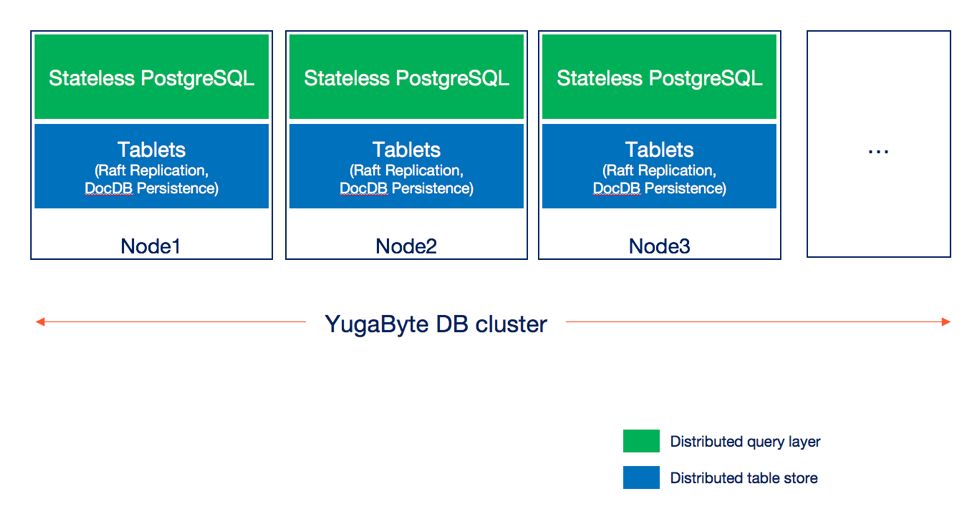
Note that both the stateless PostgreSQL query layer as well as the table store are both distributed in nature, which means they can scale out on demand by just adding nodes and are fault-tolerant. The core table store is common to both the SQL and NoSQL API, and has already been proven to scale to many terabytes of data per node while retaining high performance.
For the current beta available in YugabyteDB 1.1 release, YSQL uses a single PostgreSQL node as its query parser/router irrespective of the number of YB-TServers (aka the YugabyteDB data nodes) in the cluster. We will moving this PostgreSQL query parsing and routing logic to the YB-TServer process in a near-term beta release so that the architecture matches the one shown in the figure above.
Handling DDL statements
DDL (or Data Definition Language) is the subset of SQL statements that define (or alter) the database structure or schema. Examples of such statements are CREATE, ALTER and DROP table statements. In this section, we will look at how YugabyteDB handles SQL DDL statements.
In PostgreSQL, DDL statements are handled by the “stateless” of the Rewriter and Planner to determine what table structures to create on disk, while the Executor actually creates these requisite file and directory structures.
In YSQL, this same DDL statement is still handled by the Rewriter and Planner, but instead of the Executor creating local files, it creates a distributed DocDB table. This is shown in the figure below.
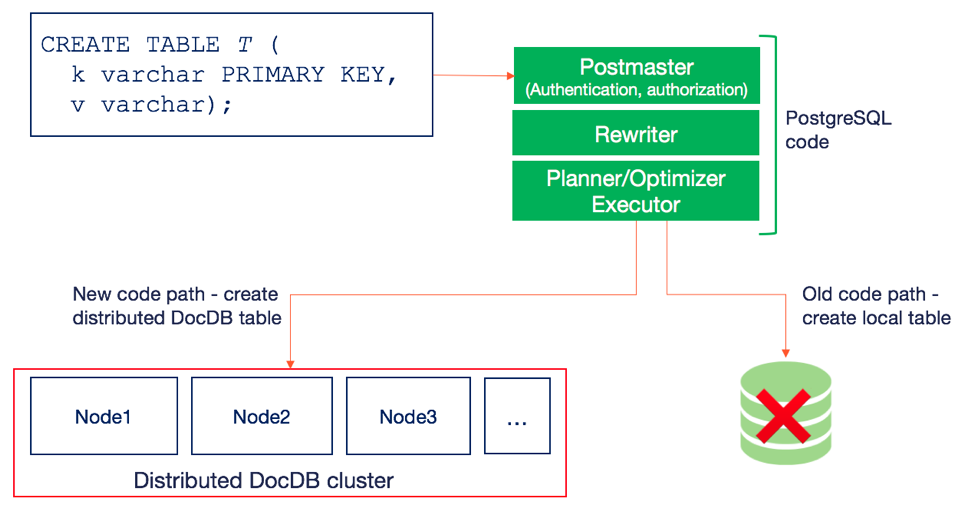
Note that the distributed DocDB table has the following properties:
- Automatic sharding to enable linear scale out.
- Data replicated across nodes using a global transaction manager and Raft consensus. This enables fault tolerance with strong consistency.
- Document oriented storage.
- Very high performance storage engine.
- Handles high data density.
Handling DML statements
DML (or Data Manipulation Language) is the subset of SQL that is used to perform CRUD operations on data. Common examples of such statements include INSERT, UPDATE, DELETE, SELECT and others.
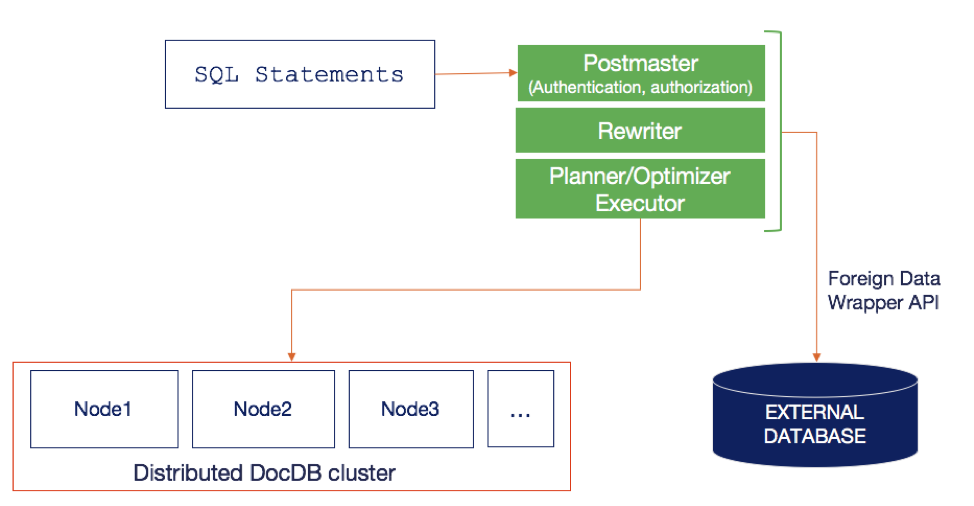
As before with DDL statements, the DML statements are also handled by the stateless upper half of the PostgreSQL database. At the execution layer, instead of writing to memory buffers and using components such as the WAL Writer and the BG Writer to persist to disk, YugabyteDB uses FDW (Foreign Data Wrappers) as a table storage API. Note that this is merely an API abstraction to enable rebasing this implementation on top of a more generic table storage API which is in the works for PostgreSQL version 12. This is shown in the figure below.
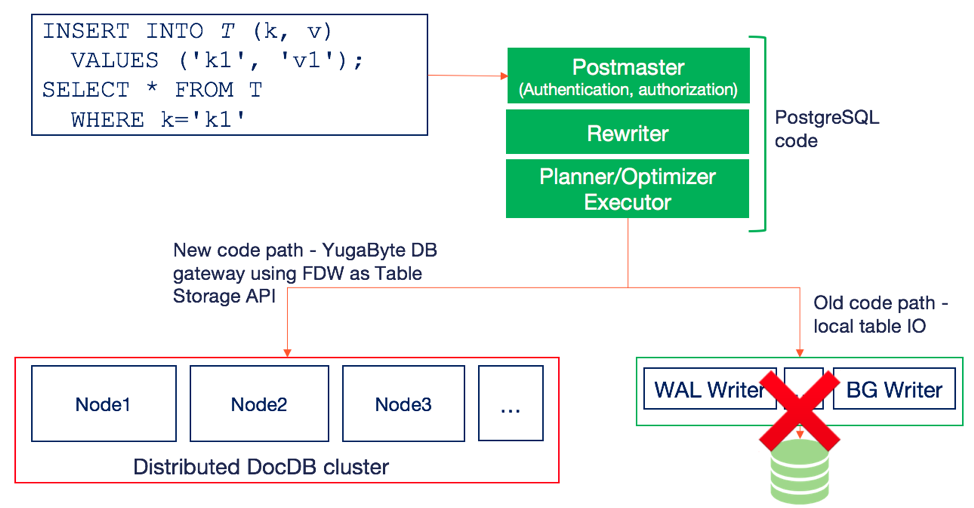
The write shown above, which inserts a single row, end up inserting a document at the distributed DocDB table store, which replicates the data using Raft consensus. A SELECT query trying to read this row will read this document which will subsequently get converted into a PostgreSQL row. Thus, the distributed DocDB table store becomes a new data source for the distributed PostgreSQL query engine.
Frequently Asked Questions
Here are some of the frequently asked questions in the context of YSQL.
PostgreSQL feature-set support
YugabyteDB was designed to support the entire SQL spec. We are re-using the open-source Postgres codebase as is in order to provide a high degree of support and to accelerate time to implement a wide array of features. We eventually expect to support most PostgreSQL features, such as:
- All data types
- Built-in functions and expressions
- Various kinds of JOINS
- Constraints – primary key, foreign key, unique value, not null and check constraints
- Secondary indexes including multi-column and covering indexes
- Distributed transactions
- Views
- Stored procedures
- Triggers
Keeping up with new PostgreSQL features
In order to design and implement the ideal architecture for a scale-out SQL database, we started out with PostgreSQL version 10.4 and extended it. But we have used the foreign data wrapper library of PostgreSQL as the internal data access layer and have closely documented the hooks needed into PostgreSQL. We plan to work with the open-source community in leveraging the External Storage APIs feature which is being worked on (in PostgreSQL v12, planned release in Q3 2019) in order to make our distributed SQL implementation an extension/plugin to PostgreSQL. This will make it easy to keep in sync with new features additions to PostgreSQL without full re-implementations.
Support for cloud native distributed SQL deployments
Distributed SQL tables in YugabyteDB can be deployed in a variety of cloud native deployment scenarios such as:
- Kubernetes deployments in StatefulSets
- Multi-zone deployments in public clouds
- Multi-region and multi-DC deployments in public or private clouds
- Multi-cloud and hybrid cloud deployments
Note that YugabyteDB already supports the above the for the NoSQL APIs (YCQL and YEDIS).
Support for external tables
This distributed PostgreSQL implementation will work with external tables. Support for external tables using foreign data wrappers is a much-loved feature of PostgreSQL. Although we are using the foreign data wrapper API as a layer of encapsulation in the regular code-path, this would not affect importing and querying external tables. A diagram of this this works is shown below.
Next Steps
YSQL is currently in beta. We continue to harden the API with extensive tests while also adding more coverage of the PostgreSQL language. We expect to make YSQL generally available next year at which point it will be ready for production deployments. Feedback on how we can do better in our journey to bring distributed SQL to the masses is always appreciated. Try YSQL using the links below and give us feedback through GitHub or Community Forum.
What’s Next?
- Read the next blog in the YSQL series on the need for distributed SQL and its coexistence with transactional NoSQL.
- Install YugabyteDB and try out YSQL from our docs.
- Compare YugabyteDB to databases like Amazon DynamoDB, Apache Cassandra, MongoDB and Azure Cosmos DB.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.

")
