YugabyteDB 2.15: Discover Worry-Free Performance
July 1, 2022
Reports show that 89% of companies with above average customer experiences perform better financially than their competitors. A lot of factors influence customer experience. However, in today’s world where more and more of your customers interact with you and your company mainly through applications, online services or automated systems, the performance of those applications can make or break your business.
Database performance has a significant impact on that application’s overall performance. But performance is impacted by a wide range of variables, including the use of indexes, the organization of queries, and the modeling of data. Therefore, making minor adjustments to these key components has a large impact on performance.
Our recently released YugabyteDB 2.15 packs a number of updates to enhance both your customer’s experience and accelerate your data loading. Key updates include:
- Performance Advisor to set and maintain optimal database performance
- Faster bulk data import into YugabyteDB
- YSQL query enhancements: Smart Scan with Predicate Pushdown and Hybrid Scan combining both Discrete and Range Filters

We’ll break down the other main pillars and features of 2.15 in additional blogs so check back in for those. Now, let’s explore each of these features in a lot more detail.
YugabyteDB 2.15: Introducing Performance Advisor to optimize database performance
The YugabyteDB 2.15 release includes the new built-in Performance Advisor to help you quickly identify and address key database management challenges. The advisor covers a wide range of areas including SQL queries, cluster topology, and schema design.
With Performance Advisor, you can scan the YugabyteDB cluster for performance tuning recommendations. This also reduces the time and effort required by developers and YugabyteDB Managed administrators to diagnose performance issues of queries and quickly implement recommendations.
The new tool also optimizes resource efficiency and helps you improve database performance with intelligent index and schema suggestions. Let us see how these suggestions work.
Improve your indexing strategy with intelligent suggestions
Indexing is too often overlooked during the development process, but a good indexing strategy can be your best tool for improving database performance. The Performance Advisor in YugabyteDB Managed automatically analyzes queries experiencing poor performance and recommends indexes to remove. Additionally, the Performance Advisor suggests dropping unused indexes to improve write performance and increase storage space.
Indexes improve read performance, but a large number of indexes can negatively impact write performance since indexes must be updated during writes. If your schema already has several indexes, consider this tradeoff of read and write performance when deciding whether to create new indexes. Examine whether a query for such a schema can be modified to take advantage of existing indexes, as well as whether a query occurs often enough to justify the cost of a new index.
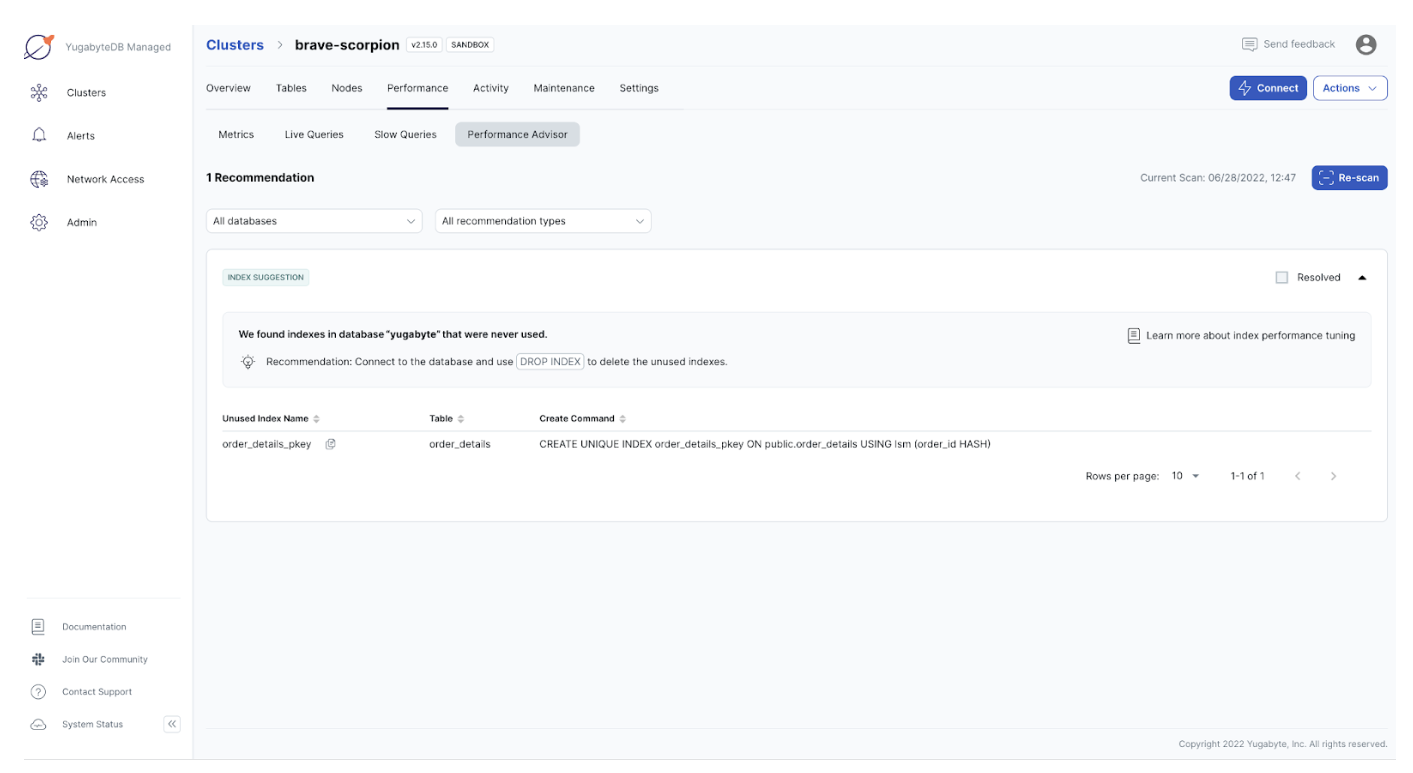
Performance Advisor uses the pg_stat_all_indexes view to determine unused indexes. Any index with an idx_scan of 0 is considered unused. So in order to fix the unused index performance issue, the Performance Advisor suggests connecting to the database and using DROP INDEX to delete the unused indexes.
Schema suggestions in YugabyteDB 2.15
Schema suggestions offer the opportunity to strategically identify data design issues in application development and production. Advisor scans for indexes that can benefit from using range sharding instead of the default hash sharding.
For example, range sharding is more efficient for queries that look up a range of rows based on column values that are less than, greater than, or that lie between some user specified values. With timestamp columns, most queries use the timestamp column to filter data from a range of timestamps.
The following example shows a query that filters the data using a specific time window. First, create an order_details table:
CREATE TABLE order_details ( order_id smallint NOT NULL, product_id smallint NOT NULL, unit_price real NOT NULL, order_updated timestamp NOT NULL, PRIMARY KEY (order_id) );
Then create an index on order_updated using range sharding:
CREATE INDEX ON order_details (order_updated asc);The following query finds the number of orders in a specific time window:
SELECT count(*) FROM order_details WHERE order_updated > '2018-05-01T15:14:10.386257' AND order_updated < '2018-05-01T15:16:10.386257';
In order to fix the above performance issue, the Performance Advisor suggests connecting to the database and using DROP INDEX to delete the indexes, and then recreate the indexes using range sharding.
Detecting hotspots by identifying connection, query, or CPU skew
The Performance Advisor scans node connections to determine whether some nodes load with more connections than others. Advisor flags any node handling 50% more connections than the other nodes in the past hour. Connections should distribute equally across all the nodes in the cluster. Unequal distribution of connections can result in hot nodes, causing higher resource use on those nodes. Similar to detecting a high number of connections to a node, the Performance Advisor also detects query load or CPU usage.
In addition to the Performance Advisor, YugabyteDB Managed provides full performance visibility by taking the pain out of database monitoring and diagnostics with real-time performance tracking, custom alerts and historical metrics. Using the real-time performance panel you can see live performance metrics for clusters, including operations, disk usage, connections, live, and slow queries. It also provides key database metrics around throughput, performance, and utilization metrics to analyze historical database performance down to small granularity.
YugabyteDB 2.15: Faster bulk data import into YugabyteDB
Sometimes, databases need to import large quantities of data in a single or a minimal number of steps. This is commonly known as bulk data import where the data source is typically one or more large files. But this process can be sometimes unacceptably slow. That’s why it’s necessary to minimize load time as best as possible
YugabyteDB 2.15 introduces numerous enhancements to dramatically reduce the import time and improve the performance. The updates include all of the following:
1. Flush write batches asynchronously
YSQL writes accumulate in the buffer and flush to the DocDB once the buffer is full. This allows for multiple buffers to be prepared and responses to be received asynchronously, which results in an additional degree of parallelism during copy. Below mentioned are a couple of tuning parameters, optimal values for these parameters based on the instance type and most scenarios should not require manual intervention. However, advanced users can tune them to get a better degree of parallelism and resource usage during copy operations.
- ysql_session_max_batch_size – Sets the maximum batch size for writes that YSQL can buffer before flushing to tablet servers
- ysql_max_in_flight_ops – Maximum number of in-flight operations allowed from YSQL to tablet servers
2. Implement new Packed Columns (new compact storage format)
Previously, a table row existed in DocDB in the following format:
<K1, C1>, <K1, C2>... <K1,Cn>.The new compact storage format stores a table row in the following format:
<K1,C1,C2…Cn>.With the new compact storage format, all columns in a table are stored as a single key-value pair in the underlying key-value DocDB storage. It reduces the space amplification by reducing the number of keys stored in the key-value store, resulting in improved performance during INSERT, UPDATE, and DELETE operations
This lower storage footprint allows not just for efficient insert/delete operations but accelerates bulk data loading as well. Secondary indexes respect the packed column format applied to tables.
Our micro-benchmark copy experiments showed that with large number of columns, various layers of DocDB spent a lot of time like constructing the DocDB KV pairs, enumerating locks for each one of them, individual memory allocation requests, serialization cost of individual KVs, duplication of the key values in RAFT and so on.
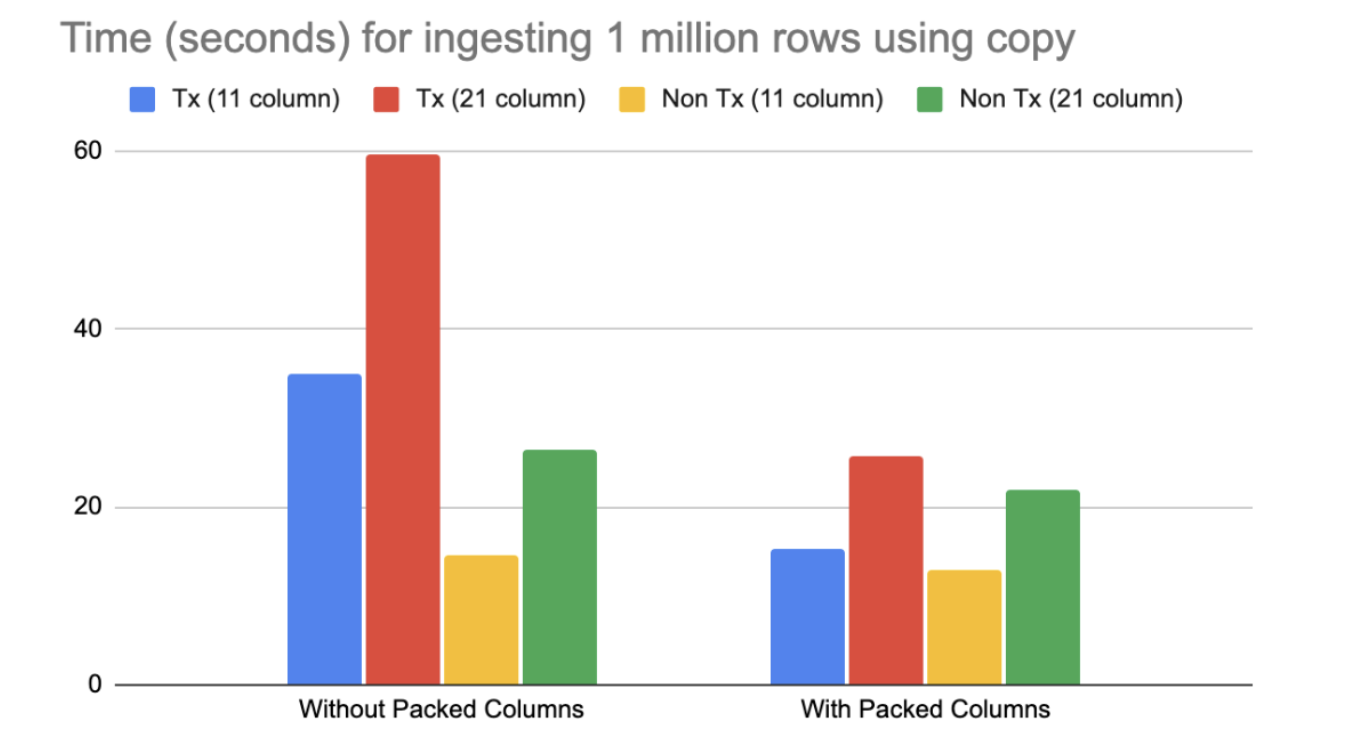
This is simple experiment of ingesting 1 million rows into a table of 11 columns vs 21 columns This data indicate that even with a 2x increase in the number of columns of a table, some of the costs grow beyond 2x, partly due to the structure of the algorithms and partly due to repeated hash map lookups (that grow non-linearly).
3. Accelerate inserts by skipping lookup of inserted keys
During bulk load (for example inserts by Copy command), YugabyteDB now skips the lookup of the key being to speed up the operation. This is similar to the upsert mode supported for YCQL.
4. Optimize memory allocation/deallocation in bulk insert/copy using Protobuf’s arena
Enhanced memory usage compared to before when running a bulk insert or copy command in the PostgreSQL backend would consume about 15 percent of CPU time on memory allocation / deallocation.
5. Eliminate serialization to the WAL format
When writing data to the RocksDB layer, optimizations were made to eliminate some unnecessary steps and wasted work for serializing to the WAL format.
6. Leverage batches to improve performance
YugabyteDB 2.15 batches the data and chooses an optimal batch size to increase the bulk data import performance. It would be problematic to import a large set of data as a single batch.
7. Disable transactional writes during bulk data loading for indexes
Added yb_disable_transactional_writes session to improve the latency performance of bulk data loading for index tables, such as when a COPY command is used that goes into the insert write path.
8. Use new COPY tuning parameters
In addition to all of the above optimizations, YugabyteDB 2.15 adds the following COPY tuning parameters to achieve faster ingestion:

9. Monitor status with COPY progress reporting
Whenever COPY is running, the pg_stat_progress_copy view will contain one row for each backend that is currently running a COPY command. The below query describes the reported information.
yugabyte=# SELECT relid::regclass, command, status, type, bytes_processed, bytes_total, tuples_processed, tuples_excluded FROM pg_stat_progress_copy; relid | command | status | type | bytes_processed | bytes_total | tuples_processed | tuples_excluded ----------+-----------+--------+------+-----------------+-------------+------------------+----------------- copy_tab | COPY FROM | PASS | FILE | 152 | 152 | 12 | 0 (1 row)
YugabyteDB 2.15: YSQL query optimizer enhancements
YugaybteDB 2.15 introduces several pushdown and scanning improvements for enhanced query performance. The updates include changes to the framework for expression pushdowns, new pushdowns for RowComparisonExpression filters, and enabling DocDB to process lookups on a subset of the range key.
Smart Scan with Predicate Pushdown in YugabyteDB 2.15
As is often the case with large queries, the predicate filters out most of the rows read. Yet all the data from the table needs to be read, transferred across the storage network and copied into memory. Many more rows are read into memory than required to complete the requested SQL operation. This generates a large number of data transfers, which consumes bandwidth and impacts application throughput and response time.
YugabyteDB 2.15 adds a framework to pushdown predicates to the DocDB storage layer. With this predicate filtering for table scans, only the rows requested return to the query layer rather than all rows in a table. YugabyteDB now supports remote filtering of conditions.
For instance SELECT … WHERE v = 1, if there is no index on v, then this needs to be filtered during execution. This allows filtering on the remote node to minimize data movement and network traffic. The predicate pushdown also occurs in case of DMLs like UPDATE and DELETE.
The beauty of open source software is that the tests are also open. If you want to get an idea of the predicates that can be pushed down, why not grep for Remote Filter on the regression tests, like this:
curl -s https://raw.githubusercontent.com/yugabyte/yugabyte-db/master/src/postgres/ src/test/regress/expected/yb_select_pushdown.out \ | grep "Remote Filter"
Currently, equality, inequality, null test, boolean expressions, CASE WHEN THEN END, and some functions are safe to push down.
New Hybrid Scan combining both Discrete and Range filters
YugabyteDB Query Optimizer uses ScanChoices iterator to iterate over tuples allowed by a given query filter in the DocDB layer. Currently, there are two types of ScanChoices based on the following filter types.
- Discrete filters (DiscreteScanChoices): These filters of the form `x` IN (a, b, c) AND `y` IN (d,e,f) where a,b,c,d,e,f are all discrete values and `x`, `y` are table columns. In this example, a DiscreteScanChoices would iterate over the space (a,b,c) x (d,e,f).
- Range filters (RangeBasedScanChoices): These are the filters that express ranges of values such as a <= x <= b where x is a table column and a, b are discrete values. In this example, the RangeBasedScanChoices would iterate over the space (a,….,b).
A shortcoming of this approach of having different ScanChoices implementations for different filter types is that it cannot support a mixture of the two filter types. If we consider a filter of the form x IN (a,b,c,d,e,f) AND p <= y <= q, then we are forced to choose either using DiscreteScanChoices and only being able to process the filter for x or the alternative where we can only process the filter on y.
YugabyteDB 2.15 introduces a new iterator, HybridScanChoices, which supports both types of filters. It treats both filter types as part of a larger class of filters that are conceptualized as lists of ranges as opposed to lists of values or singular ranges. It converts a filter of the form r1 IN (a,b,c,d) to r1 IN ([a,a], [b,b], [c,c], [d,d]). A range filter of the form a <= r1 <= b is converted into r1 IN ([a,b]).
This unifies the way filters are interpreted at the DocDB iteration level and allows much more efficient queries. The feature is enabled by default, but it can also be disabled by setting the runtime GFlag, disable_hybrid_scan, to true.
YugabyteDB 2.15: Get started and learn more
We’re thrilled to be able to deliver these enterprise-grade features in the newest version of our flagship product – YugabyteDB 2.15. We invite you to learn more and try it out:
- YugabyteDB 2.15 is available to download now! Installing the release just takes a few minutes.
- Join the YugabyteDB Slack Community for interactions with the broader YugabyteDB community and real-time discussions with our engineering teams.
NOTE: Following YugabyteDB release versioning standards, YugabyteDB 2.15 is a preview release. Many of these features are now generally available in our latest stable release, YugabyteDB 2.16.


