YugabyteDB 2.15: Support Any Workload with Dynamic Workload Optimization
June 29, 2022
Several of the key innovations released in YugabyteDB 2.15 help you not just survive, but thrive, in the face of changes. New YugabyteDB features support a diverse set of applications and their inherent unpredictability with greater ease. By leveraging a flexible, unified database you can avoid re-architecting applications or augmenting your environment with new databases.
Predicting how your applications and their requirements will change and morph over time is almost impossible. We live in a world where old customers disappear, surprise customers grow rapidly, and new services require different application architectures. For example, a set of applications today may depend mainly on NoSQL whereas in the future SQL could become more important. You need to be ready for any future.

YugabyteDB 2.15 delivers the following key new features to support dynamic workload optimization:
- Quality of Service (QoS) and multi-tenancy
- Dynamic app-aware sharding
We’ll break down the other main pillars and features of YugabyteDB 2.15 in additional blogs so check back in for those. Now, let’s explore each of these features in a lot more detail…
Quality of Service (QoS) and multi-tenancy
As we increase the number and diversity of applications deployed on YugabyteDB, we wanted to release a number of features focused on Quality of Service (QoS) and multi-tenancy. The new features help ensure that your critical services (or SQL statements) achieve performance objectives and that we can smoothly handle situations of heavy load.
Two scenarios where QoS becomes important include:
- Heavy cluster utilization: In this scenario, you need to keep the cluster running while ensuring higher priority transactions. Admission controls handles this.
- Multi-tenancy: If multiple tenants or services use the cluster, it becomes essential to limit the resource usage of any one tenant or service. Rate limiting resources per tenant accomplishes this.
Manage heavily loaded clusters with admission controls
YugabyteDB implements admission control to ensure that a heavily loaded cluster is able to stay up and running. Admission control kicks in after connection authentication and authorization. It works at various stages of query processing and execution. The following controls are available to ensure quality of service.
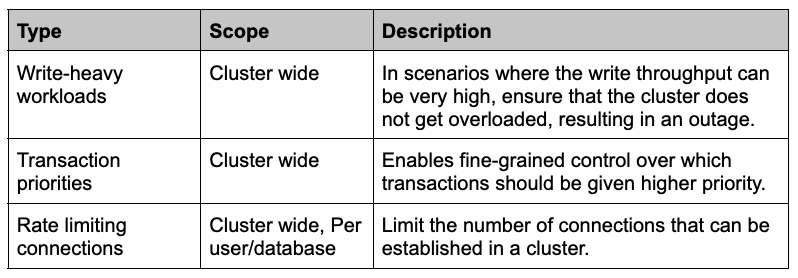
Prioritize transaction execution with QoS
New YugabyteDB transaction priorities ensure the most important requests for your application are always served first. Applications can set the priority of individual transactions. When using optimistic concurrency control, a higher priority transaction gets priority over a lower priority transaction. In this scenario, if these transactions conflict, the lower priority transaction is aborted.
This behavior sets the pair of session variables:
- yb_transaction_priority_lower_bound (value between 0.0 and 1.0)
- yb_transaction_priority_upper_bound (value between 0.0 and 1.0)
The transactions in that session computes and assigns a random number between the lower and upper bound. If this transaction conflicts with another, the conflicting transaction compares with the value of transaction priority. The transaction with a higher priority value wins.
For example, imagine a financial services application that needs to handle a deposit and a withdrawal transaction that happen at the same time to the same account. You want to give higher priority to deposit transactions (when compared to withdrawals). To achieve this, you need to set the following transaction priorities for both these transactions.

The deposit transaction starts after withdrawal initiation, but occurs before withdrawal completion from a separate session.
Rate limiting connections per node/tenant/database
Each connection to a YugabyteDB cluster uses CPU and memory. This means it is important to consider the required number of connections for the application. YugabyteDB uses a max_connections setting to limit the number of connections per node in the cluster (and thereby the connections that consume resources). It does this to prevent run-away connection behavior from overwhelming your deployment’s resources.
You can check the value of max_connections with your admin user and ysqlsh.
SHOW max_connections; max_connections ----------------- 300
Similarly, it is important to limit the number of connections per tenant. In order to achieve this, map a tenant to a database and a user (or a service account), and rate limit the number of connections per database for the user.
Set connection limit for database as shown below:
alter database test_connection CONNECTION LIMIT 1;.
You can display the limit as shown below:
select datname, datconnlimit from pg_database where datname =’test_connection’; datname | datconnlimit -----------------+-------------- test_connection | 1
Admission controls for write-heavy workloads
YugabyteDB has extensive controls in place to slow down writes when flushes or compactions cannot keep up with the incoming write rate. Without this, if users keep writing more than the hardware can handle, the database will:
- Increase space amplification, which could lead to running out of disk space
- Increase read amplification, significantly degrading read performance
New features in YugabyteDB 2.15 can slow down incoming writes to a manageable speed to avoid the above issues. In these scenarios, YugabyteDB slows down the incoming writes gracefully by rejecting some or all of the write requests.
The reason that writes stall and thus require more time to handle are two main scenarios—a low CPU environment or disks with low performance. When this happens, the following symptoms occur at the database layer:
- Flushes cannot keep up: More writes than the system can handle could result in too many memtables getting created, which get flushed.
- Compaction cannot keep up: The database getting overloaded with writes can also result in compactions not being able to keep up.
- WAL writes are too slow: If WAL writes are slow, then writes experience higher latency which creates a natural form of admission control.
- Limited disk IOPS or bandwidth: In many cloud environments, the disk IOPS and/or the network bandwidth is rate-throttled.
In order to slow down the incoming writes gracefully, YugabyteDB incorporates both stop writes triggers and slow down writes triggers. Let’s explore more about when these triggers get activated.
Stop writes trigger
In a stop writes trigger scenario, the rejection of incoming write requests happens when YugabyteDB gets the write request. The incoming write rejection computes on a per tablet basis. If a write request is already processed by the database (meaning acceptance and not rejection), then that write will be processed. However, if the write request ends up needing to trigger subsequent writes (for example, certain types of writes that need to update indexes), then those subsequent requests could themselves fail.
Stop writes trigger activates in one of the following scenarios:
- Too many SST files: The number of SST (Sorted Sequence Table) files exceeds the value determined by the flag sst_files_hard_limit, which defaults to 48. Once the hard limit hits, no more writes process, and all incoming writes get rejected.
- Memstores flushed too frequently: This condition occurs if there are a large number of tablets, all of which get writes. In such cases, the memstores flush frequently, resulting in too many SST files. In such cases, you can tune the total memstore size allocated. Total memstore size is the minimum of the two flags:
- global_memstore_size_mb_max (default value is 2GB)
- global_memstore_size_percentage (defaults to 10% of total TServer memory)
You have two different options for controlling how YB-TServer allocates the amount of memory:
- By setting default_memory_limit_to_ram_ratio to control what percentage of total RAM on the instance the process should use
- Specify an absolute value too using memory_limit_hard_bytes. For example, to give YB-TServer 32GB of RAM, use –memory_limit_hard_bytes 34359738368
- Too many memstores queued for flush: More than one memstore queues for getting flushed to disk. The number of memstores queued at which this trigger activates is set to 2 (therefore, 2 or more memstores queue for flushing).
Slowdown writes trigger
Slowdown writes trigger activates when the number of SST files exceeds the value determined by the flag sst_files_soft_limit. However, it does not exceed the sst_files_hard_limit value. The default value of the sst_files_soft_limit flag is 24. The slowdown in writes rejects a percentage of incoming writes with probability X, where X computes as follows:
X = (<num SST files> - soft_limit) / (hard_limit - soft_limit)
Dynamic app-aware sharding
If you work at a large or growing company, then you probably have a wide mix of transactional applications. These applications have different needs satisfied simultaneously on a single database.
By combining existing YugabyteDB capabilities with the new 2.15 enhancements around QoS and multi-tenancy, you can manage different types and sizes of workloads without an excessive increase in resources. In addition, you can handle varying and conflicting workloads without a corresponding variance in response times. You can also manage the workloads to meet defined service levels.
Expanded flexibility and application support is desirable in a number of scenarios, including the following:
- Small datasets needing HA or geo-distribution: Applications that have a smaller dataset may fall into the following pattern where they require a large number of small tables, indexes, and other relations created in a single database. The size of the entire dataset is small but needs high availability and/or geographic data distribution. In this case, scaling the dataset or the number of IOPS is not an immediate concern. Also, it is undesirable to have the small dataset spread across multiple nodes because this might affect performance of certain queries due to more network hops (for example, joins).
- Large datasets with both large and small tables: Other applications may have a few large tables with many small tables, where the large dataset requires many tables and indexes. The applications may have a handful of tables expected to grow and require a lot of scale, while the rest of the tables will continue to remain small. In this scenario, only the few large tables would need to shard and scale out. All other tables would benefit from colocation, because queries involving all tables except the larger ones would not need network hops.
Get started and learn more
We’re thrilled to be able to deliver these enterprise-grade features in the newest version of our flagship product – YugabyteDB 2.15. We invite you to learn more and try it out:
- YugabyteDB 2.15 is available to download now! Installing the release just takes a few minutes.
- Join the YugabyteDB Slack Community for interactions with the broader YugabyteDB community and real-time discussions with our engineering teams.
Finally, Register for our 4th annual Distributed SQL Summit taking place in September.
NOTE: Following YugabyteDB release versioning standards, YugabyteDB 2.15 is a preview release. Many of these features are now generally available in our latest stable release, YugabyteDB 2.16.

")
