A Busy Developer’s Guide to Database Storage Engines — Advanced Topics
June 28, 2018
In the first post of this two-part series, we learned about the B-tree vs LSM approach to index management in operational databases. While the indexing algorithm plays a fundamental role in determining the type of storage engine needed, advanced considerations highlighted below are equally important to consider.
Consistency, Transactions, and Concurrency Control
Monolithic databases, which are primarily relational/SQL in nature, support strong consistency and ACID transactions. Distributed databases have to abide by the CAP Theorem where an explicit choice of either consistency or availability has to be made in the presence of failures. NoSQL databases are inherently distributed, and 1st generation NoSQL databases (including Apache Cassandra, AWS DynamoDB, Couchbase) prefer availability over consistency. In other words, they follow eventual consistency. Eventually consistent databases do not support ACID transactions and are limited to BASE operations. Next-generation databases such as YugabyteDB, FoundationDB, and MS Azure Cosmos DB are breaking these long-held design choices by bringing strong consistency to the NoSQL world.
How do these guarantees impact the design of the storage engine? The biggest impact is related to how the storage engine handles concurrent requests, which are determined by the Isolation levels (i.e. the “I” in ACID) supported. SQL databases originally went with the strictest form of concurrency control using row-level locks. However, the need to provide better throughput led to the introduction of Multi-Version Concurrency Control (MVCC) that relaxed the need for locks by creating different versions of the rows for reads and writes to work on. E.g. in the figure below the write by Session 1 is on version 2 of the record while the read by Session 2 uses version 1. Periodic pruning called Garbage Collection is used to remove the unused versions.
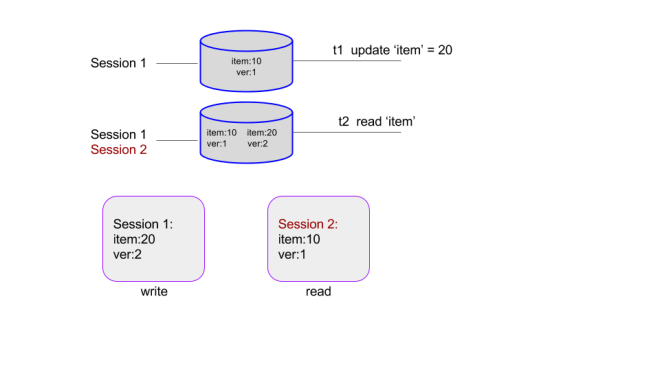
MVCC “without locks” usually means Snapshot Isolation level where each transaction executes against a consistent snapshot of the database. Serializable, the strictest isolation level, requires approaches such as 2-phase locking (the Oracle way) or serializable certifier (the PostgreSQL way). Monolithic SQL databases usually support both Snapshot Isolation and Serializable levels.
On the traditional NoSQL front, MVCC is rarely implemented. Apache Cassandra has no MVCC, which means it does not stop multiple concurrent writers from writing conflicting values — the write with the latest client timestamp wins. AWS DynamoDB allows apps to implement optimistic concurrency control only if conditional operations are used. With Global Tables, AWS DynamoDB loses even that guarantee and falls back to the the same last-writer-wins semantics as Apache Cassandra for all operations. A notable exception here is MongoDB’s WiredTiger that implements MVCC with document-level concurrency.
Transactional NoSQL databases such as YugabyteDB and FoundationDB have MVCC implementations. YugabyteDB’s implementation is based on a hybrid timestamp approach. FoundationDB uses MVCC for reads and optimistic concurrency for writes.
Compactions
 LSM engines naturally compact data periodically and, in the process, reorganize data stored in a write-optimized format to a more read-optimized format, and also garbage-collect stale data. They typically offer multiple compaction strategies so users can configure them per their workload needs. For example, Apache Casssandra offers Size (for write-heavy workloads), Leveled (for read-heavy workloads) and TimeWindow (for time-series workloads) compactions.
LSM engines naturally compact data periodically and, in the process, reorganize data stored in a write-optimized format to a more read-optimized format, and also garbage-collect stale data. They typically offer multiple compaction strategies so users can configure them per their workload needs. For example, Apache Casssandra offers Size (for write-heavy workloads), Leveled (for read-heavy workloads) and TimeWindow (for time-series workloads) compactions.
Compaction in B-tree engines has a completely different meaning when compared to LSM engines. B-tree compaction refers to the process of reclaiming disk space by removing stale data and index values. For write-heavy workloads where new data is entering the engine continuously, reclaiming disk space is important. Compaction of data and indexes can be done either sequentially (lower CPU/disk IO overhead) or in parallel (higher CPU/disk IO overhead).
Compression
 Compression is essentially the process of making size of on-disk data smaller to reduce storage costs and backup times. It comes with an increase in CPU costs given the need to compress and de-compress data when needed. A common approach is to compress blocks of data using algorithms such as Prefix, Snappy, LZO, LZ4, ZLib, and LZMA. Similar to compaction, most databases support multiple compression algorithms so that users can configure whichever ones fit their needs. Note that B-tree engines are susceptible to fragmentation with wasted space that doesn’t lend itself well to compression. LSM engines do not suffer from this problem and hence offer better compression.
Compression is essentially the process of making size of on-disk data smaller to reduce storage costs and backup times. It comes with an increase in CPU costs given the need to compress and de-compress data when needed. A common approach is to compress blocks of data using algorithms such as Prefix, Snappy, LZO, LZ4, ZLib, and LZMA. Similar to compaction, most databases support multiple compression algorithms so that users can configure whichever ones fit their needs. Note that B-tree engines are susceptible to fragmentation with wasted space that doesn’t lend itself well to compression. LSM engines do not suffer from this problem and hence offer better compression.
Summary
At the core, database storage engines are usually optimized for either read performance (B-tree) or write performance (LSM). Additional aspects such as consistency, transactions, concurrency, compactions, and compressions should be taken into account for a complete understanding of the engine.
In the last 10+ years data volumes have grown significantly and LSM engines have become the standard. LSM engines can be tuned more easily for higher read performance (e.g. using bloom filters and various compaction strategies) compared to tuning B-tree engines for higher write performance. Note that the supported data model (relational vs. non-relational) and the corresponding database client API (SQL vs. NoSQL) are not directly tied to the design of the storage engine. Both SQL and NoSQL databases are built on B-tree and LSM engines.


