Achieving 10x Better Distributed SQL Performance in YugabyteDB 2.1
February 25, 2020
When starting the YugabyteDB project, our founding thesis was to build a high-performance distributed SQL database for the cloud native era. Achieving high performance will always remain an ongoing initiative, especially when additional optimizations are required to support new features and new use cases. We are excited that the current YugabyteDB 2.1 release has a number of improvements that make Yugabyte SQL’s performance 10x better on average than the previous 2.0 release (from September 2019). These improvements have also resulted in much better Yahoo! Cloud Serving Benchmark (YCSB) results. Additionally, we were able to run the TPC-C benchmark against YSQL for the first time. In this post, we will look at some of the performance enhancements that have gone into YugabyteDB 2.1, and the benchmarking results for YCSB and TPC-C.
The table below summarizes some of the performance optimizations, along with a realistic estimate of how much performance improvement they contributed.
| YSQL Feature | Performance Improvement |
|---|---|
Batch loading data using COPY FROM | 35x |
| Insert array of values | 15x |
| Parallel execution for full scans and aggregates | 10.5x |
| Index scan improvements | 5x |
| Single row update with fine-grained locking | 2.5x |
| Caching checked foreign keys inside transactions | 2x |
Pushing down aggregate functions such as MAX() | 1.1x |
| Average | ~ 10x |
Realized performance gain across various enhancements in YugabyteDB 2.1
Understanding the Performance Improvements
There are a number of optimizations to commonly used scenarios in YugabyteDB 2.1 that have been implemented. Each of them involved different techniques, and diving into the details of each optimization is a series of posts in itself. In this section, we will look at one class of optimizations (involving a reduction in the number of RPC calls to remote nodes) that yielded large performance wins.
It’s All About the Network
Broadly speaking, in a distributed SQL database like YugabyteDB most of the additional pushdown optimizations required (on top of a single-node RDBMS) come down to working around the latency and bandwidth limitations imposed by the network. These primarily include reducing the number of RPC calls and the data transferred over the network. Thus, in order to optimize for the network, it is important to identify these scenarios across the various queries and optimize them by pushing down as much of the query processing logic close to the storage layer as possible.
In order to enable more pushdowns, the underlying storage layer needs to be capable of performing as large a fraction of query processing as the query layer itself. YugabyteDB achieves this by reusing the PostgreSQL libraries at both the YSQL query layer as well as at the distributed storage layer, called DocDB. This is possible because the PostgreSQL libraries are implemented in C and DocDB is implemented in C++. Therefore there is no impedance to cross-language calls. This is shown diagrammatically below.
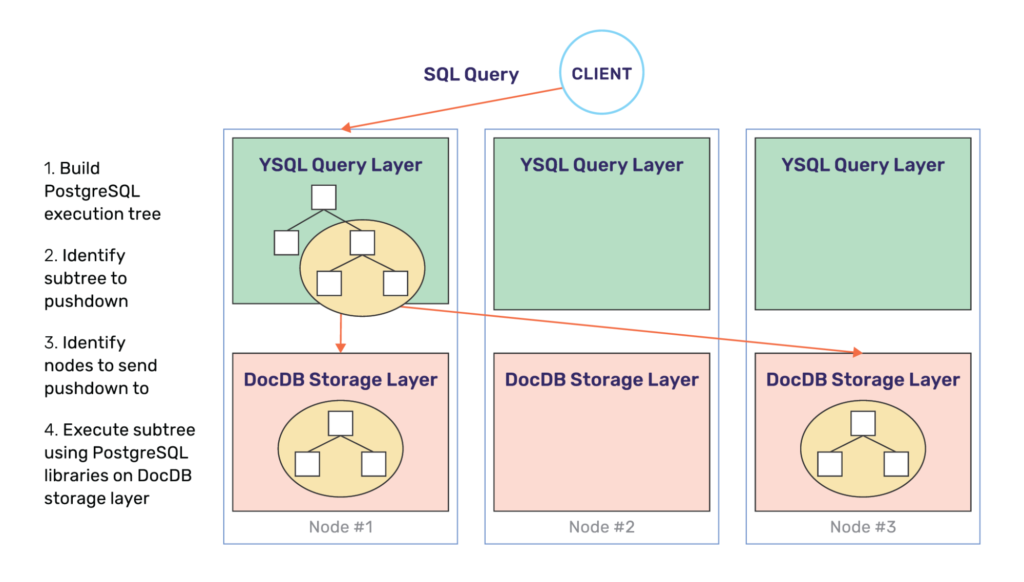
Reducing RPC Calls to Remote Nodes
For this class of optimizations, we will look at how the COPY FROM performance was optimized. This technique applies to a number of other optimizations, such as inserting an array of values, and filtering using index predicates. In many benchmarks (and real-world scenarios), a large data set must first be loaded into YugabyteDB. Very often, data is batch loaded into the database from an external CSV file using the COPY FROM command as shown below.
COPY table FROM 'data.csv' WITH (FORMAT csv, ESCAPE '\');
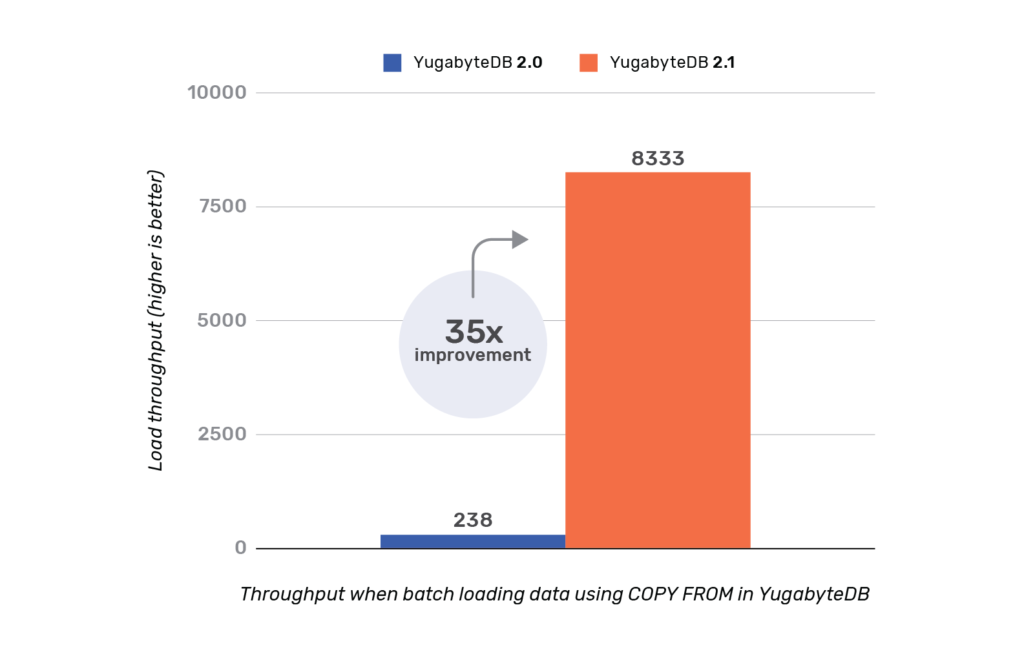
YugabyteDB 2.1 has significant performance improvements in batch loading data over the 2.0 release. A distributed SQL database internally shards the rows of a table and distributes it across multiple nodes of a cluster to achieve horizontal scalability. In doing so, there is a real possibility that multi-row operations become punitively slow if care is not taken to appropriately batch them.
In order to optimize statements that involve batch loading data, YugabyteDB implements buffering and regrouping of sub-operations as two key strategies. Once again, this optimization is transparent to the end user and ensures ACID transactional guarantees. The write path across the various nodes is shown in the architecture diagram below.
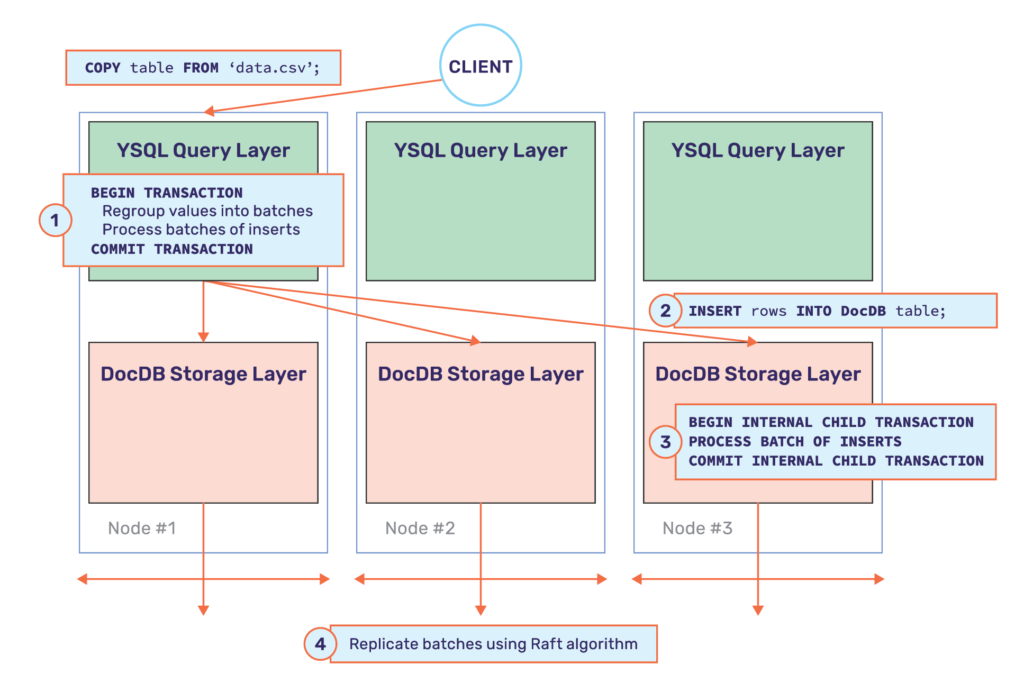
In order to measure the performance improvement, we tried inserting 50K rows using the COPY FROM command. The results of this experiment are shown below.
YCSB
The goal of the Yahoo! Cloud Serving Benchmark, known as YCSB for short, is to develop a framework and common set of workloads for evaluating the performance of different key-value and cloud serving stores. It serves as an excellent benchmark for understanding the performance characteristics of databases in the cloud. For YCSB, we employed a standard JDBC client. We have uploaded a pre-built package of the YCSB benchmark with the JDBC driver, so you can run the benchmark yourself by following the instructions in our Docs.
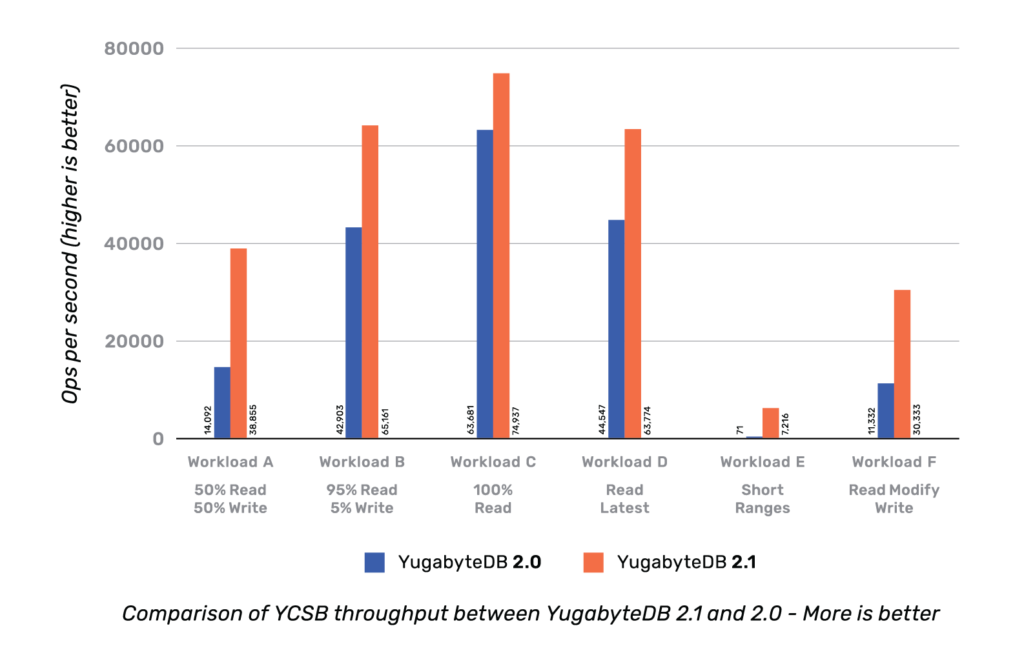
The chart below compares the YCSB throughput of YugabyteDB v2.1 vs. v2.0 when running the benchmark on a cluster of three nodes (each node is a c5.4xlarge with 16 vCPUs) in Amazon Web Services (AWS) cloud.
The chart below compares the corresponding latencies.
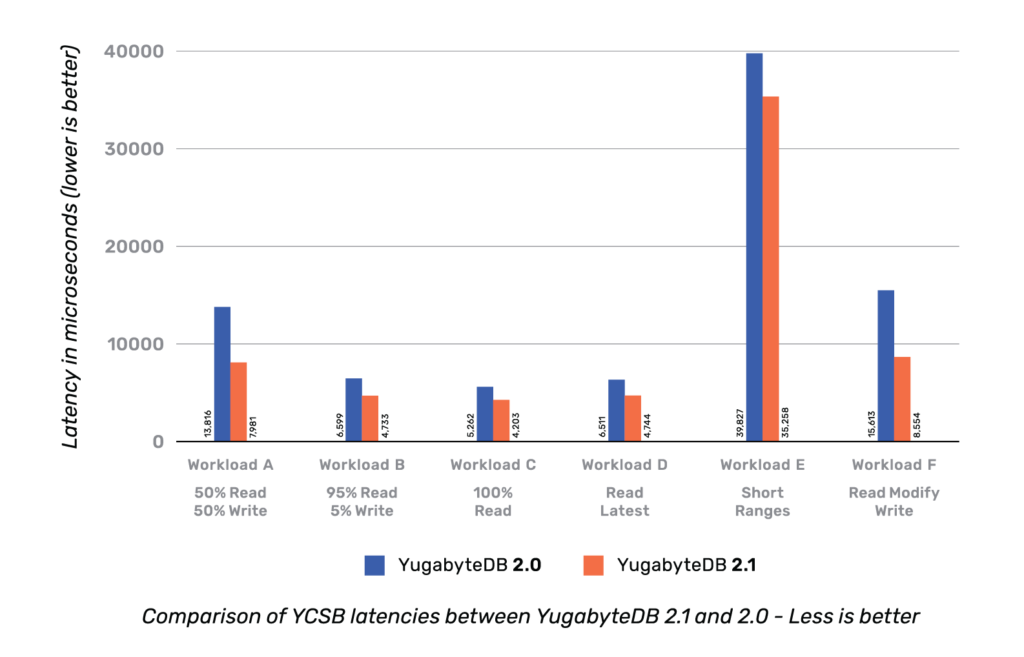
From the charts above, it should be clear that there is an improvement in both throughput and latency across all the YCSB workloads.
Modeling Workload E Efficiently in Distributed SQL
The official YCSB documentation has the following description for Workload E.
“In this workload, short ranges of records are queried, instead of individual records. Application example: threaded conversations, where each scan is for the posts in a given thread (assumed to be clustered by thread id).”
In YugabyteDB, the most optimal way to achieve this workload is by using a combination of HASH and RANGE sharding. This can be done quite easily by creating the YCSB table using the following schema.
CREATE TABLE usertable( YCSB_KEY1 VARCHAR, YCSB_KEY2 VARCHAR, FIELD0 VARCHAR, FIELD1 VARCHAR, ... PRIMARY KEY(YCSB_KEY1 HASH, YCSB_KEY2 ASC));
In the schema above, we assume that YCSB_KEY1 represents the thread id, and YCSB_KEY2 represents the message id inside a thread. Hash sharding the thread ids is optimal, because in the example of a threaded conversation, it is much more efficient to distribute the various threads across the nodes of a cluster while keeping the various messages inside the thread ordered by posts.
TPC-C
TPC-C is an on-line transaction processing (OLTP) benchmark simulating an order-entry environment and involves a mix of five concurrent transactions of different types and complexity either executed on-line or queued for deferred execution. The database is comprised of nine types of tables with a wide range of record and population sizes. TPC-C is measured in how many New-Order transactions per minute (tpmC) a system generates while the system is executing four other transactions types (Payment, Order-Status, Delivery, Stock-Level). While the benchmark portrays the activity of a wholesale supplier, TPC-C is not limited to the activity of any particular business segment, but, rather represents any industry that must manage, sell, or distribute a product or service.
For running TPC-C, we used the standard JDBC client. We have uploaded a pre-built package of the TPC-C benchmark with the JDBC driver, so you can run the benchmark yourself by following the instructions in our Docs.
The following table shows the initial results of running TPC-C with 100 warehouses accessed by 64 terminals. YugabyteDB was running on a 3-node cluster using c5.4xlarge AWS instances, each with 16 CPU cores, 32GB RAM and 2 x 500GB gp2 EBS volumes. YugabyteDB 2.1 is the first version we have benchmarked against TPC-C and the results of benchmark are shown below.
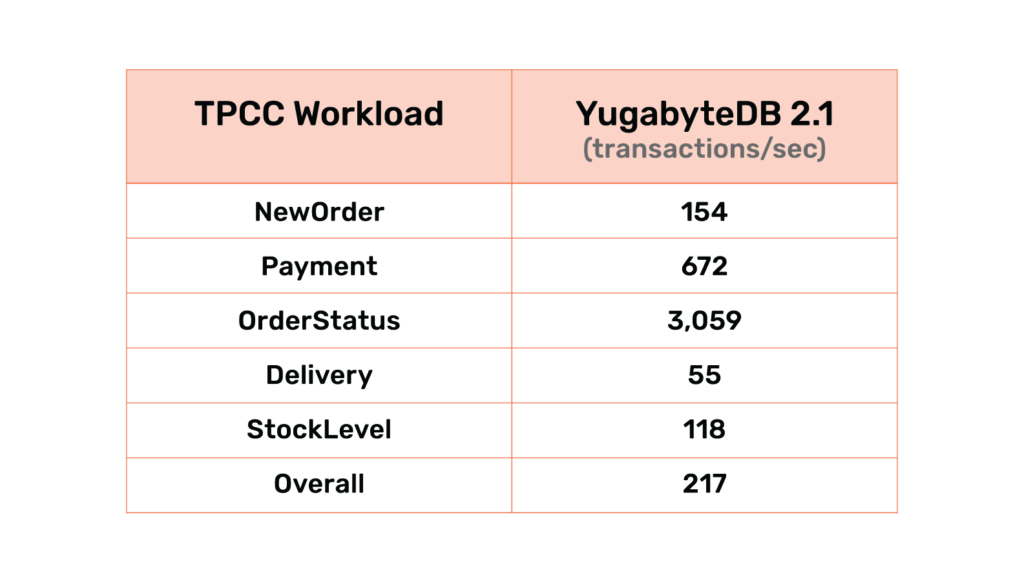
The TPC-C numbers above are from running the open-source oltpbench TPC-C workload using 100 warehouses. “Overall” represents the transactions/sec when running a weighted mix (as per TPC-C specification) of all five transaction types (new order, payment, order status, delivery and stock level). The other rows represents the transactions/sec when running a transaction type individually.
NOTE: oltpbench does not handle some TPC-C specifications such as wait times and response time constraints. We are actively working on adding those and getting a more accurate benchmark suite.
YugabyteDB Cluster Setup Details
The details of the YugabyteDB cluster used in this benchmark are as follows:
- Cloud Provider: AWS
- Region/zone: us-west-2a
- Number of nodes: 3
- Node type: c5.4xlarge (16 vCPUs, 32GB RAM, 2 x 250GB gp2 EBS)
The node used to drive the load on the above cluster had the following setup:
- Cloud Provider: AWS
- Region/zone: us-west-2a (located in the same AZ as the cluster)
- Number of benchmarking nodes: 1
- Benchmark node type: c5.4xlarge
All three packages–YCSB, TPC-C, and yugabyteDB–were installed on the benchmark client VM.
What’s Next?
Look for upcoming posts that will go into the details of the various optimizations. Though a number of optimizations have gone into YugabyteDB 2.1, the work is far from complete. We’re looking at even more enhancements, below are a few examples.
- Pushing down an entire execution subtree into DocDB. For example, pushing down the entire set of predicates and multi-column expressions.
- Optimizing
GROUP BYqueries with pushdowns. - Another area of ongoing work is to improve parallel queries to the DocDB storage layer.
- Cost-based optimization of queries is also in progress. Given that YugabyteDB is a geo-distributed database, the idea is to enhance the PostgreSQL cost optimizer (which is available in its entirety in YSQL) to not just compute costs based on table sizes but also take the network latency into consideration


