Achieving Fast Failovers After Network Partitions in a Distributed SQL Database
May 15, 2019
In February of this year, Kyle Kingsbury of Jepsen.io was conducting formal testing of YugabyteDB for correctness under extreme and unorthodox conditions. Obviously, simulating all manner of network partitions is part of his testing methodology. As a result, during his testing he spotted the fact that although nodes would reliably come back after a failure, the recovery itself was taking roughly 25 seconds to occur. We certainly didn’t like the sound of that!
In this blog post, we’ll look at how failovers after a network partition are handled in YugabyteDB, plus do a quick overview of the changes we implemented to bring recovery times down to under 5 seconds. But, before we dive into the problem and solution, it merits to get a quick overview of exactly how network partitions and failovers are handled in YugabyteDB.
How Does YugabyteDB Handle Network Partitions and Failovers?
What Exactly is a Network Partition?
A network partition in the context of distributed SQL databases like YugabyteDB happen when the network connectivity is split between the nodes due to a failure. For example, when a switch between two subnets fails. Or in the case of a multi-datacenter deployment, when the datacenters are unable to communicate with each other due to a power outage, natural disaster or operator error! These are just a few examples of how “network partitioning” between nodes can occur.

The negative consequences, if not handled correctly, include reading stale data and writing or modifying data to partitioned nodes that are now inconsistent with each other. The longer the partition and heavier the write workload, the bigger the mess in trying to resolve conflicts and synchronize the nodes into a consistent state.
YugabyteDB is a Consistent and Partition-Tolerant Database
In terms of the CAP theorem, YugabyteDB is a Consistent and Partition-tolerant (CP) database. It ensures High Availability (HA) for most practical situations even while remaining strongly consistent. While this may seem to be a violation of the CAP theorem, that is not the case. The ‘C’, ‘A’ and ‘P’ are not binary knobs and YugabyteDB offers very high availability while being a CP database. Read more about the CAP theorem here.
Handling Network Partitions in YugabyteDB
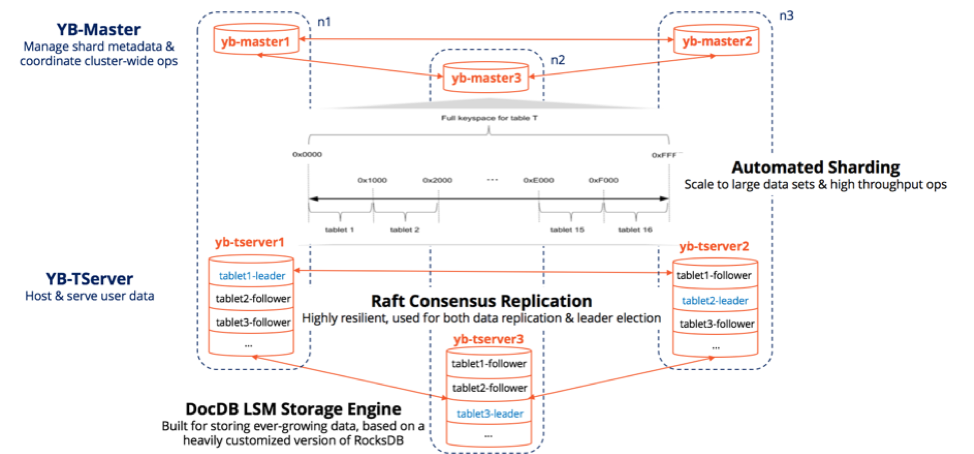
Three Node RF3 YugabyteDB Cluster
During network partitions or node failures, the replicas of the impacted tablets (whose leaders got partitioned out or lost) form two groups: a majority partition that can still establish a Raft consensus and a minority partition that cannot establish such a consensus (given the lack of quorum). The replicas in the majority partition elect a new leader among themselves in a matter of seconds and are ready to accept new writes after the leader election completes. For these few seconds till the new leader is elected, the DB is unable to accept new writes given the design choice of prioritizing consistency over availability. All the leader replicas in the minority partition lose their leadership during these few seconds and hence become followers.
Majority partitions are available for both reads and writes. Minority partitions are available for reads only (even if the data may get stale as time passes), but not available for writes. Multi-active availability refers to YugabyteDB’s ability to serve writes on any node of a non-partitioned cluster and reads on any node of a partitioned cluster.
The above approach obviates the need for any unpredictable background anti-entropy operations, as well as, the need to establish a quorum at read time. YugabyteDB’s sharding, replication and transactions architecture is similar to that of Google Cloud Spanner which is also a CP database with high write availability. Note that Google Cloud Spanner leverages Google’s proprietary network infrastructure, YugabyteDB is designed work on the commodity infrastructure used by most enterprises in conjunction with hybrid logical clocks (HLC).
25 Second Failovers? That’s Not Good!
Here’s the relevant issue and comment that Kyle reported to us during his testing:
OK, I’ve done a bunch more testing; recovery times on 1.1.15.0-b16 now look to be around ~25 seconds, and they’re in general reliable about coming back after that time.

~25 Second Recovery Time After Network Partition
5 Second Failovers? Yes, and Can Still be Improved!
After Kyle’s observation we quickly got started looking into the issue to see what improvements or fixes we could apply.
The Problem: Stuck TCP Connections
Here’s the relevant issue I opened to track its progress:
What we found was that when Jepsen introduced a network partition using iptables like: iptables -A INPUT -s -j DROP -w, it caused the open TCP connections with traffic before the partition to produce an additional delay in acknowledging and transmitting packets, even after the network partition was over. For example, in experiments with simulated 30-second network partitions, while using netcat to communicate between hosts, we observed a 23 second delay after the network partition was over.
The Solution: Drop and Recreate TCP Connections
At first, we looked at reducing the RPC keepalive time, but this didn’t help. In fact, it sometimes made things worse. Why? Because while scanning for idle connections, it would only drop inbound server connections, but not outbound client connections. So, during a partition, the server was dropping timed out connections, but the client was not. And after a network partition, the client was still trying to send Read/Write RPC requests to the server, only to get an error that the connection was shutdown after 30+ seconds. During that period requests were simply being sent “nowhere” and the Java client requests were timing out.
Finally, the solution we came across on how to deal with these stuck connections was to drop the existing TCP connections on timeout and create new TCP connections. With this change, you can see from the graph below, that we can now predictably get 5 second failovers after a network partition. We also know that we can tune rpc_connection_timeout_ms to a lower value (the default is 15 seconds) to enable even faster recovery times. Additionally, we believe there might be some more improvements we can make by simply digging into the code a little more.
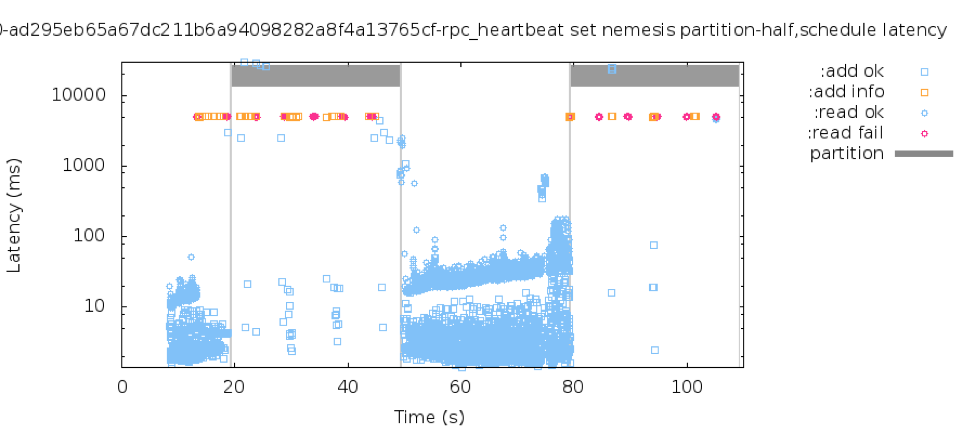
5 Second Recovery Time After Network Partition
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.

")
