Solving PostgreSQL Indexes, Partitioning, and LockManager Limitations
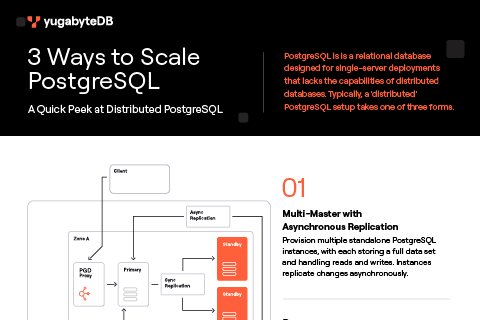
Managing large PostgreSQL tables requires partitioning, which can complicate queries. Migrating to YugabyteDB simplifies scaling by automatically sharding and distributing data and minimizing partition reliance. The article includes demos on PostgreSQL’s partitioning limitations and YugabyteDB’s advantages in distributed tables and scalability.