Announcing YugabyteDB 2.9: Pushing the Boundaries of Relational Databases
August 26, 2021
This morning we announced the latest release of the YugabyteDB open source database, YugabyteDB 2.9! This release introduces new capabilities that push the boundaries of relational databases further than ever before. Yugabyte pioneered distributed SQL databases that combine advanced RDBMS capabilities with the resilience, scale, and geo-distribution that cloud native applications demand. Over the years, we have continued to innovate with capabilities such as distributed transactional backups, YSQL tablespaces, and tablet splitting that implement SQL capabilities in a distributed environment, or optimize for the distributed nature of a YugabyteDB cluster.
YugabyteDB 2.9 introduces several new capabilities and significant improvements that push the state of SQL forward in the world of distributed SQL:
- Industry first smart client driver for SQL that allows applications to get better performance and fault tolerance by connecting to any node in a distributed SQL database cluster without the need for an external load balancer.
- Transaction savepoints that allow all statements that are executed after it was established to be rolled back, restoring the transaction state to what it was at the time of the savepoint.
- Automatic re-sharding of data with tablet splitting that enables dynamic scaling of clusters.
- RPC compression to significantly reduce costs associated with cross-AZ or cross-region network traffic by compressing internode network traffic with minimal CPU overhead.
- Support for chunking/throttling options for secondary index backfill operations in order to control performance.
In the following sections, we go over these capabilities in YugabyteDB 2.9.
Smart Client Driver for SQL
This release delivers the industry’s first smart client driver for SQL. The driver understands the distributed architecture of a YugabyteDB cluster, and allows applications to directly connect to any node in a distributed SQL database cluster without the need for an external load balancer. The client driver is available as open source software under the Apache 2.0 license. Let us see why this is important.
Since YugabyteDB is feature compatible with PostgreSQL, applications can use many of the widely available PostgreSQL client drivers to connect to a YugabyteDB cluster. However, these PostgreSQL drivers are designed to be used with a monolithic database with a single network address. When they connect to a distributed database, they don’t understand that the database consists of multiple nodes that they can connect to. Organizations get around this limitation by putting the nodes behind one or more load balancers.
However this approach results in complex configurations and increases management overhead. For example, the database cluster endpoints abstract role changes (primary elections) and topology changes (addition and removal of instances) occurring in the database cluster. However, DNS updates are not instantaneous. In addition, they can lead to a slightly longer delay between the time a database event occurs and the time it’s noticed and handled by the application.
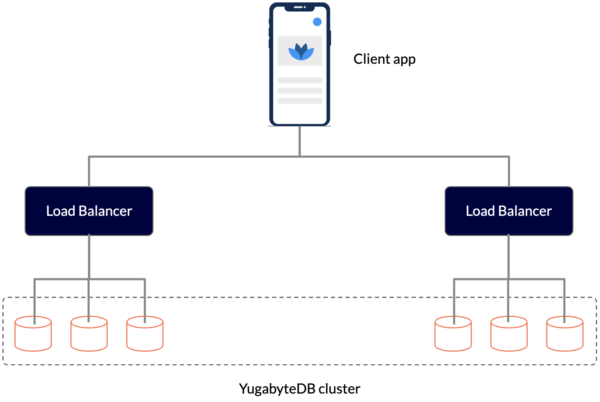
Figure: Connecting to a YugabyteDB cluster using load balancers
The new Yugabyte Smart Driver for SQL is optimized for use with a distributed SQL database. The Yugabyte Smart Driver for SQL is both cluster-aware and topology-aware. The driver keeps track of the members of the cluster as well as their locations. As nodes are added or removed from clusters, the driver updates its membership and topology information. The Yugabyte Smart Driver has the ability to read the database cluster topology from the metadata table. It can route new connections to individual instance endpoints without relying on high-level cluster endpoints. The Yugabyte smart driver is capable of load balancing read-only connections across the available Yugabyte T-Servers.
Let us look at some of the benefits of using the Yugabyte Smart Driver:
- Simplify operations by eliminating the load balancer: Because PostgreSQL JDBC drivers are designed for a single-node database, they do not keep track of the nodes of a distributed database cluster or their locations. Customers rely on external load balancers to route requests to different nodes in a database cluster, adding to the operational overhead. Yugabyte’s Smart Driver eliminates the need for an external load balancer.
- Improve performance by connecting to nearby nodes: Client applications can identify and connect to the database cluster nodes closest to them to achieve lower latency
- Improve availability with better failure handling: If a database node becomes unreachable due to a network issue or server failure, clients can connect to a different node in the cluster. Retry logic on the client-side can make failures transparent to the end-user.
Transaction Savepoints for Error Recovery in Large Transactions
Recovering from errors during a transaction can lead to an undesirable situation where some operations succeed before one of them fails, and after recovering from that error the data is left in an inconsistent state. YugabyteDB now offers a solution to this problem in the form of Savepoints.
Savepoints are useful for implementing complex error recovery in database applications. If an error occurs in the midst of a multiple-statement transaction, the application may be able to recover from the error (by rolling back to a savepoint) without needing to abort the entire transaction.
A savepoint is a special marker inside a transaction that allows all statements that are executed after it was established to be rolled back, restoring the transaction state to what it was at the time of the savepoint.
Yugabyte Savepoints are implemented in PostgreSQL using sub-transactions. Rolling back to a savepoint allows you to get out of the “current transaction is aborted, commands ignored until the end of transaction block” mode, so savepoints are useful for error handling in large transactions.
The relevant savepoint commands are:
| Command | Description |
|---|---|
| SAVEPOINT <name> | Establishes a savepoint inside a transaction |
| RELEASE SAVEPOINT <name> | Forgets a savepoint, and keeps the effects of statements executed after the savepoint was established |
| ROLLBACK TO SAVEPOINT <name> | Rolls back a transaction partially to a previously established savepoint, discarding all changes created after that savepoint |
Automatic Re-sharding of Data with Tablet Splitting
Tablet splitting is the resharding of data in the cluster by presplitting tables before data is added or by changing the number of tablets at runtime. YugabyteDB clusters have supported two mechanisms to reshard data by splitting tablets: 1. presplitting tables into a desired number of tablets at creation time, and 2. manually splitting tablets at runtime.
In YugabyteDB 2.9, we have now added support for automatic tablet splitting. This feature enables dynamic scaling by automatically resharding data in a cluster while online, and transparently to users. There are a number of scenarios where this is useful:
- Range Scans: In use-cases that scan a range of data, the data is stored in the natural sort order (also known as range-sharding). In these usage patterns, it is often impossible to predict a good split boundary ahead of time. For example: On column ‘age’ it’s not possible for the database to infer the range of values for age. It’s also impossible to predict the distribution of rows in the table, This makes it hard to pick good split points ahead of time.
- Low-cardinality primary keys: In use-cases with a low-cardinality of the primary keys (or the secondary index), hashing is not very effective. However, it is still desirable to use the entire cluster of machines to maximize serving throughput.
- Small tables that become very large: This feature is also useful for use-cases where tables begin small and thereby start with a few shards. If these tables grow very large, then nodes continuously get added to the cluster. We may reach a scenario where the number of nodes exceeds the number of tablets. Such cases require tablet splitting to effectively re-balance the cluster.
Reduction in Network Bandwidth Consumption Using RPC Compression
YugabyteDB 2.9 offers the ability to compress network traffic between nodes of a cluster in order to reduce the amount of bandwidth used between peers. With the RPC compression feature, we significantly reduce costs associated with cross-AZ or cross-region network traffic with minimal CPU overhead. The feature supports different compression algorithms. In addition to the existing gzip compression algorithm we added Snappy and LZ4 traffic compression algorithms. The feature supports easy enable or disable compression with rolling upgrade support and provides the ability to select the compression algorithm of your choice.
Support for Chunking/Throttling for the Secondary Index Backfill Operation
If you are adding a secondary index to a very large table, it might take a long time for the index creation process to complete. It depends on several factors, such as: the size of the table, items in the table that qualify for inclusion in the index and the attributes projected into the index.
If the provisioned write throughput setting on the index is too low, the index build will take longer to complete. To shorten this time, you can increase its provisioned write capacity with backfill instruction. The backfill instruction defines how many rows to process (backfill) and which row key to start from (i.e. where the previous backfill call left off).
The rate at which the backfill should proceed can be specified by the desired number of rows of the primary table to process per second. In order to enforce this rate, the index backfill process keeps track of the number of rows being processed per second from the primary table.
Additionally, the maximum number of backfill operations happening on any TServer across tablets can also be specified in order to rate-limit backfilling. If a user creates multiple indices, the backfill for the different indices are batched together so that only one scan is done.
Also In This Release
In addition to these five key capabilities, YugabyteDB 2.9 includes several new features and improvements that we will cover in separate posts:
- Faster compaction with TTL (Time To Live) file expiration: Instead of iterating through every K/V pair in the file to identify expired entries, we have done optimization to improve disk usage and compaction performance by directly removing files that have completely expired based on their TTL.
- LDAP support for YCQL: In addition to YSQL LDAP support, YCQL customers can now also manage and authorize users’ privileges via an LDAP server.
- Continuous data protection with Point in Time Recovery (PITR): PITR enables granular data protection with a low recovery point objective (RPO) and recovery time objective (RTO), and has minimal impact on the cluster.
- Integration with schema migration tools like Flyway, Liquibase and ORM tools like Sequelize.
What’s Coming – Roadmap Teaser
At Yugabyte, we strive to be fully transparent with our customers and user community, and to that end we publish our roadmap on GitHub. Here are some notable features you can expect in upcoming releases. Note that the current roadmap is subject to change as we finalize our planning for the next releases.
Database
Several database features are on the roadmap, such as point in time recovery and incremental backups, better support for pessimistic locking, and better support for online schema migrations including support for popular migration frameworks such as Liquibase, Flyway, and other ORM migration frameworks. Additionally, continued work to unlock even greater database performance is always a work in progress.
- Support for Internationalization and Collation in YSQL – Support COLLATE option for text-based columns. In particular support for primary key and indexed columns requires specific DocDB handling to ensure correct equality and sorting semantics.
- Support for GIN indexes
Platform
- xCluster replication management UI – An easy and user-friendly interface for setting up xCluster replication, ensuring setup correctness, monitor, and tracking xCluster replication through the Yugabyte Platform console rather than using CLI commands
- New Alerting and Notifications UI to raise real-time alerts based on a user alert policy. It also provides out of the box intelligent database health checks and default alerts. Users can choose to forward notifications to 3rd party centralized notification systems or build their alerting stack programmatically via APIs
- Yugabyte Platform API SDK to enable automation of any day 2 operations of the database using your favorite CI/CD tools
Get Started
We’re very happy to be able to release all of these enterprise-grade features in the newest version of our flagship product – YugabyteDB 2.9. We invite you to learn more and try it out:
- YugabyteDB 2.9 will be available at the end of the month. You can install the release in just a few minutes.
- Join us in Slack for interactions with broader YugabyteDB community and real-time discussions with our engineering teams.


