YugabyteDB 2.17: Faster, Better Protection for Your Business-Critical Apps
December 13, 2022
Data protection is crucial to ensure business continuity. If an organization loses its data, or even a significant part of it, the consequences will be catastrophic.
At the core of data protection are database backups—regularly taken copies of data stored outside of the cluster. In the case of partial or full data loss due to hardware or software failure, the latest backups can be retrieved to restore the data.
Different businesses have different data protection requirements, usually expressed as two key objectives:
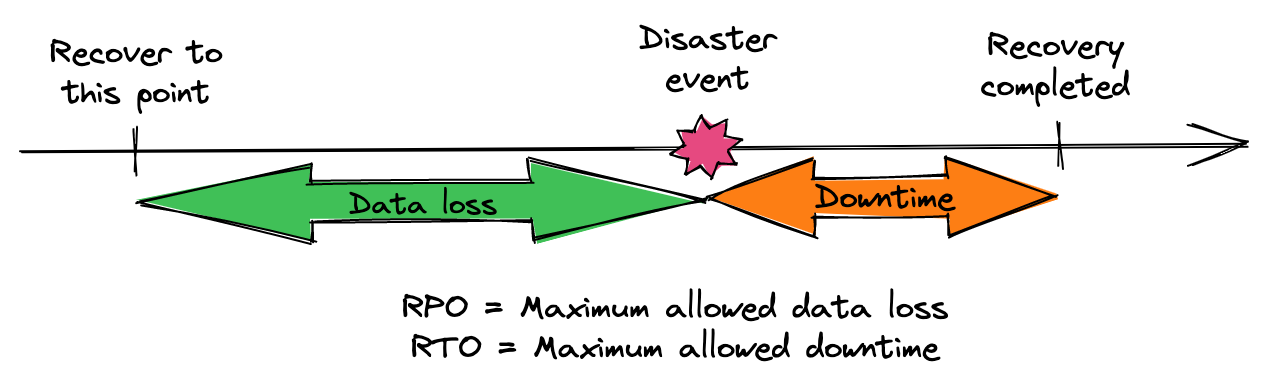
- Recovery point objective (RPO) refers to the earliest point in time prior to a disaster event when the data must be restored to. In other words, RPO indicates the amount of tolerable data loss.
- Recovery time objection (RTO) is the maximum tolerable downtime (i.e. the maximum amount of time needed to restore the system to a workable state).
At Yugabyte, we are continuously working on improving backup and restore capabilities to support various organizational objectives. YugabyteDB 2.17 includes major updates, which we call “Backup 2.0.”
In this blog, we dive into these new updates and show how you can use this added flexibility to lower RPO and RTO.
The Importance of Backup Performance
Before diving into the new features of 2.17, let’s review how backups are implemented in YugabyteDB, and how the time to create a backup—and to restore from a backup—relate to RPO and RTO.
A YugabyteDB backup is created in two steps:
- Create a distributed in-cluster snapshot, which is a consistent cut of data across all nodes and tablets.
- Locate all the data files belonging to the snapshot and transfer them to a remote location, such as a cloud object store (AWS S3, GCS, Azure Blob) or NFS.
The first step is executed locally on YugabyteDB nodes and mostly consists of creating hard links to the immutable SST files. No physical data copying or any other operations is required, so the snapshot creation is blazingly fast. It typically completes within seconds.
The second step, implemented in YugabyteDB Anywhere, is much different. It involves transferring data across the network and saving it at the destination. The larger your database, the more data you need to transfer. Therefore, the longer it will take to create a remote backup.
The time it takes to create a backup is crucial, since it directly affects RPO. Reducing this time allows you to create more frequent backups. More frequent backups mean lower RPO.
Time to restore is equally important from an RTO point-of-view. When a data loss event occurs, you will restore from the latest backup by transferring data from the remote location back to the cluster. This,of course, takes time. In many cases, this time is the biggest contributor to the downtime, so lowering it is likely to improve RTO.
New Backup and Restore Architecture
Prior to YugabyteDB 2.17, the YugabyteDB Anywhere instance was fully responsible for managing the backup and restore processes. In a nutshell, it would span several parallel threads and use each of those threads to connect to one of the tablets via SSH. It would also coordinate the transfer of the files that belong to that tablet.
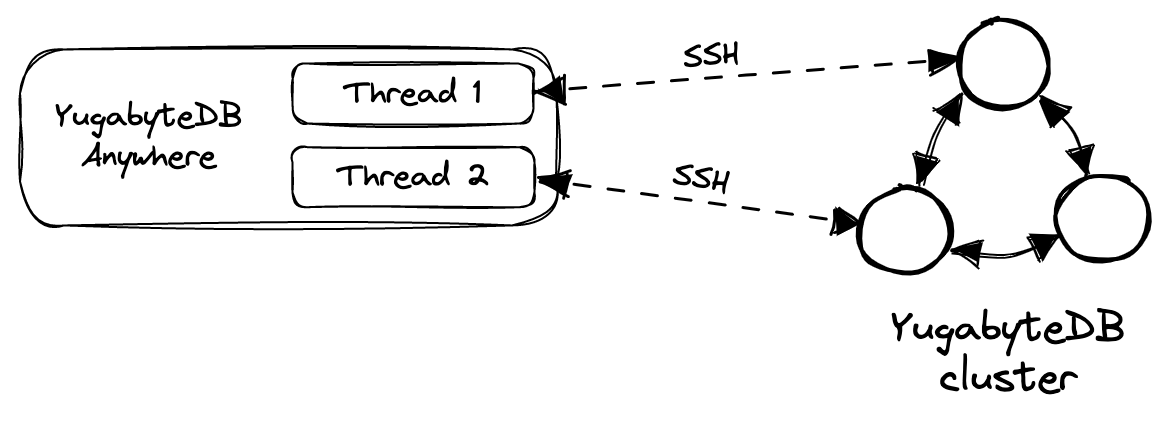
The number of threads that can be created on the YugabyteDB Anywhere side is limited. So in some instances, especially when dealing with large clusters and large databases, it could become a bottleneck.
To mitigate the bottleneck, YugabyteDB Anywhere, along with YugabyteDB 2.17, introduces a new backup architecture. Here, each node sends its data directly to the backup target in parallel, allowing for a much better level of parallelism during both backup creation and restore. Instead of centrally managing the process, YugabyteDB Anywhere now delegates these functions to a specialized internal component called the YB-Controller (YBC). This is a standalone process running next to every node in the cluster.
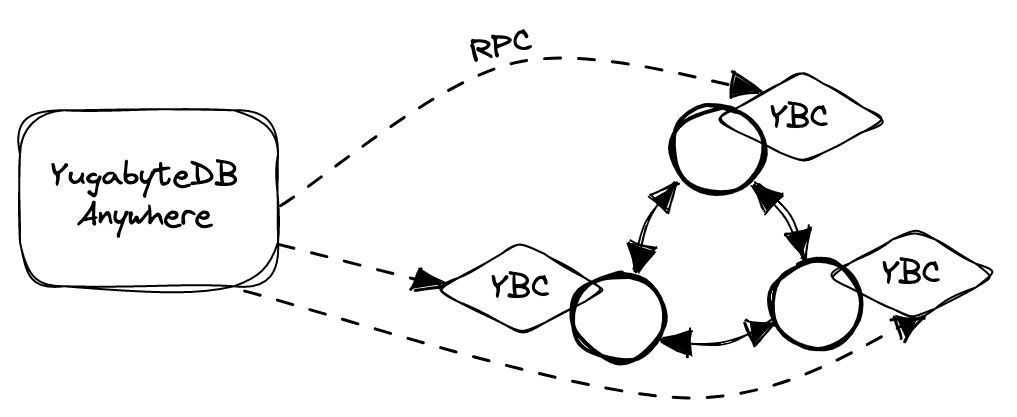
When you use YugabyteDB Anywhere to create a new backup, or restore from an existing backup, it sends a corresponding RPC command to one of the YBC instances, which then forwards this command to other instances after the snapshot is created. From that point on, each of those instances is fully responsible for copying the data from or to the node it is attached to.
During the data transfer process, which is the most expensive step, an instance of YB-Controller is completely independent from its siblings and communicates only with a single local node. In addition, the number of YB-Controllers is always equal to the number of nodes, which means that they scale together with the cluster. This decentralization makes the whole process extremely efficient and can transfer more data in less time, consuming less or an equal amount of CPU and memory resources.
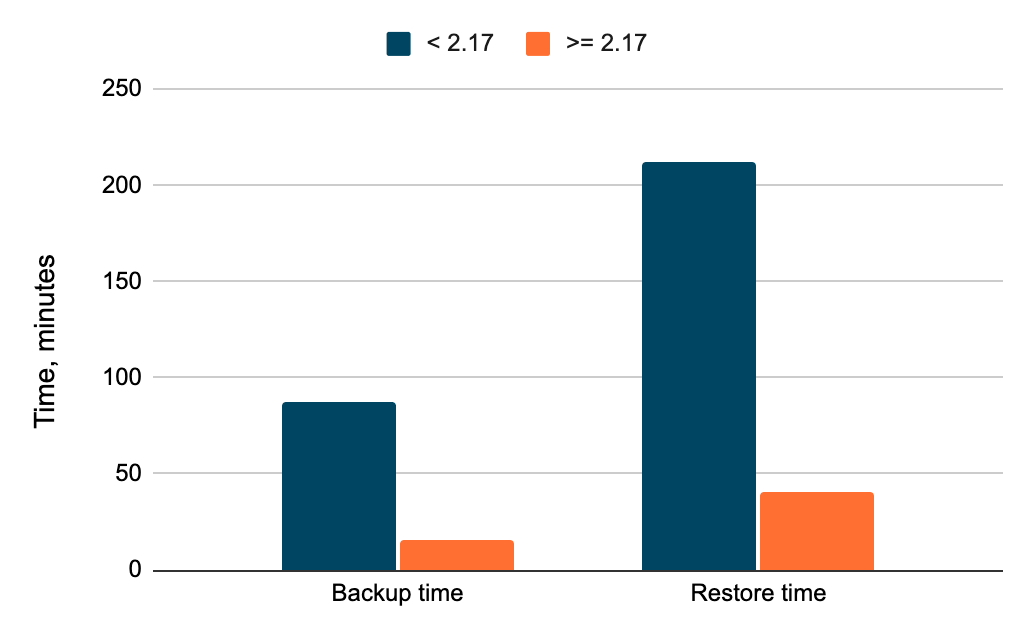
The new scalable architecture delivers up to a 5x improvement in backup and restore times compared to previous YugabyteDB versions. Below are the test results for a 600GB dataset deployed on a 9-node YugabyteDB cluster.
These new capabilities are enabled by default for any new clusters created after upgrading to YugabyteDB 2.17. No additional configuration is required. Note: internally, YugabyteDB Anywhere still supports both the old and new implementations, so that you can restore from backups created by older versions. If you try to restore from such a backup, the system will automatically fallback to the older mechanism.
New Incremental Backups
Another big feature introduced in YugabyteDB 2.17 is incremental backups.
An incremental backup represents the delta since the last backup, which can be another incremental, or a full backup. With this capability you don’t have to transfer all the data each time you create a backup. Instead, you can set up a schedule, which, for example, will create a full backup once a week and then an incremental backup every day.
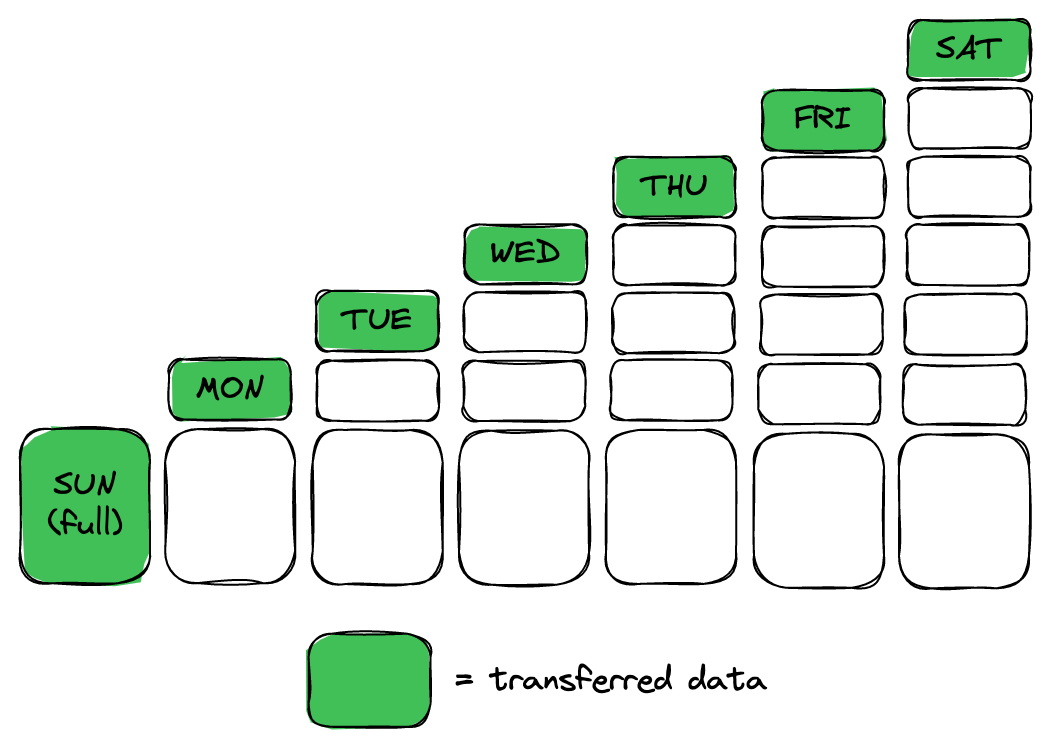
An incremental backup only holds the data that has changed since the last backup. It is generally much smaller in size than a full backup (this is especially true for large datasets). Therefore, by using incremental backups, you significantly reduce the amount of data sent across the network on every iteration of the backup schedule. This provides two main benefits:
- Possibility of more frequent backups: By reducing the average size of a backup, we also reduce the time it takes to create it. As we discussed earlier, better performance means that backups can be created more frequently, thus reducing RPO.
- Lower cost of backups: Smaller backups require less disk space on the backup storage, as well as less network resources to transfer them to that storage. Both are significant factors that contribute to the amount you need to spend on maintaining your data backups—incremental backups are a great way to save money.
How do incremental backups work?
YugabyteDB 2.17 uses a file-level approach for incremental backups. It calculates the delta between backups by comparing a list of files in the latest backup and in the snapshot created for the new backup, without diving deeper into the logical contents of those files.
This approach is possible because YugabyteDB is based on LSM storage. This stores all the data in immutable SST files, so while the data is being updated, new SST files can be created, but the existing ones are never changed.
To demonstrate the algorithm, let’s look at a simple example. We start with a database consisting of four SST files:
000010.sst 000011.sst 000012.sst 000013.sst
First, create a full backup. For that, we simply copy all four files to a designated location (let’s say, s3://backups/my-db/full). We also create a special manifest file that lists every file included in the backup, along with its precise location. So, the manifest for the full backup contains the following information:
000010.sst => s3://backups/my-db/full 000011.sst => s3://backups/my-db/full 000012.sst => s3://backups/my-db/full 000013.sst => s3://backups/my-db/full
Now, let’s assume that one additional file has been created (000014.sst). Now there are five files.
To create an incremental backup, we go through the following steps:
- Lookup the manifest for the latest backup (in this case, the full backup), compare it with the latest list of files, and identify the newly added files. In our example, this will produce a list with one new file, which is 000014.sst.
- Identify a location for the new backup (e.g., s3://backups/my-db/incremental-1).
- Copy only the new file to that location.
- Create a manifest for the new backup that lists all files and their locations.
The manifest for the incremental backup will look like this:
000010.sst => s3://backups/my-db/full 000011.sst => s3://backups/my-db/full 000012.sst => s3://backups/my-db/full 000013.sst => s3://backups/my-db/full 000014.sst => s3://backups/my-db/incremental-1
NOTE: Older files still point to the full backup location, so the system always knows where to find them. If you decide to restore from an incremental backup, it will look at the manifest for that backup, and collect all the required files from different locations, as stated by the manifest.
Repeat the above process for every incremental backup. So, for example, if two more files are created in the database, only those two files would be transferred to create a latest incremental backup, and the manifest will look something like this:
000010.sst => s3://backups/my-db/full 000011.sst => s3://backups/my-db/full 000012.sst => s3://backups/my-db/full 000013.sst => s3://backups/my-db/full 000014.sst => s3://backups/my-db/incremental-1 000015.sst => s3://backups/my-db/incremental-2 000016.sst => s3://backups/my-db/incremental-2
Again, the manifest lists all the files required to restore from this backup, along with the location of those files, so that the system can find them.
The advantage of the file-level approach is that, unlike with other implementations, the restore time does not depend on the number of incremental backups in the backup chain. If you increase the frequency of your incremental backups without increasing the frequency of full backups, you will get the same value for the RTO as before. This will help you more easily adapt to changing requirements for data protection.
Conclusion
With a large, ever-increasing global footprint of data, DBAs need to mitigate the challenge of accommodating growing backups during a set timeframe.
To accommodate growing needs, YugabyteDB 2.17 rearchitects backup and restore mechanisms to accelerate them with up to 5x higher throughput. It also adds incremental backups so you can create backups up to 20x more frequently.
By adding these new features, YugabyteDB 2.17 removes key obstacles to database modernization. It empowers organizations by providing a host of new benefits unmatched in both legacy and many modern databases, placing developer productivity at the core.
Download YugabyteDB 2.17 for free today and find out for yourself.
NOTE: Following YugabyteDB release versioning standards, YugabyteDB 2.17 is a preview release. New features included are under active development and made available for development and testing projects.


