A Behind-the-Scenes Look at Chaos Testing
September 21, 2023
A crucial aspect of ensuring database robustness is chaos testing. Chaos testing, a critical facet of assessing system resilience, simulates real-world failures to understand how a system responds under extreme circumstances. This blog takes you on an immersive journey into the domain of chaos testing, focusing on a practical case study involving YugabyteDB’s Change Data Capture (CDC) functionality.
Understanding Chaos Testing: Delving into the Unpredictable
Chaos testing is a methodology that mimics chaotic conditions to uncover vulnerabilities, weaknesses, and potential pitfalls within a database system.
By subjecting the system to controlled chaos, we can gain invaluable insight into its behavior under extreme stress and any resulting failures, enabling us to proactively address shortcomings.
Chaos testing is like a safety drill for a rocket launch. Before the rocket embarks on its journey into space, it needs to go through simulated challenges in a controlled environment. Why? So that when it faces the vast unknowns of outer space, the mission control team can navigate its complexities and ensure a successful journey.
In the digital world, chaos testing does something similar. It creates controlled challenges for systems, by practicing emergency situations. We put our systems into tough situations – data storms, part malfunctions, and even network hiccups. By doing this, we’re not just finding weak points; we’re building a strong foundation that can withstand any turbulence, just like a well-tested rocket.
In fact, these challenges become opportunities for our team to make our database even better, turning any obstacles into stepping stones toward improvement.
Change Data Capture (CDC) and YugabyteDB
In our journey, let’s pause to decipher an integral concept, particularly relevant to our case study – Change Data Capture (CDC) within the scope of YugabyteDB.
CDC in YugabyteDB ensures that any changes in data due to operations such as inserts, updates, and deletions are identified, captured, and automatically applied downstream, or made available for consumption by applications and other tools. It’s like an eagle-eyed observer meticulously noting every move and seamlessly transmitting it downstream for further action.
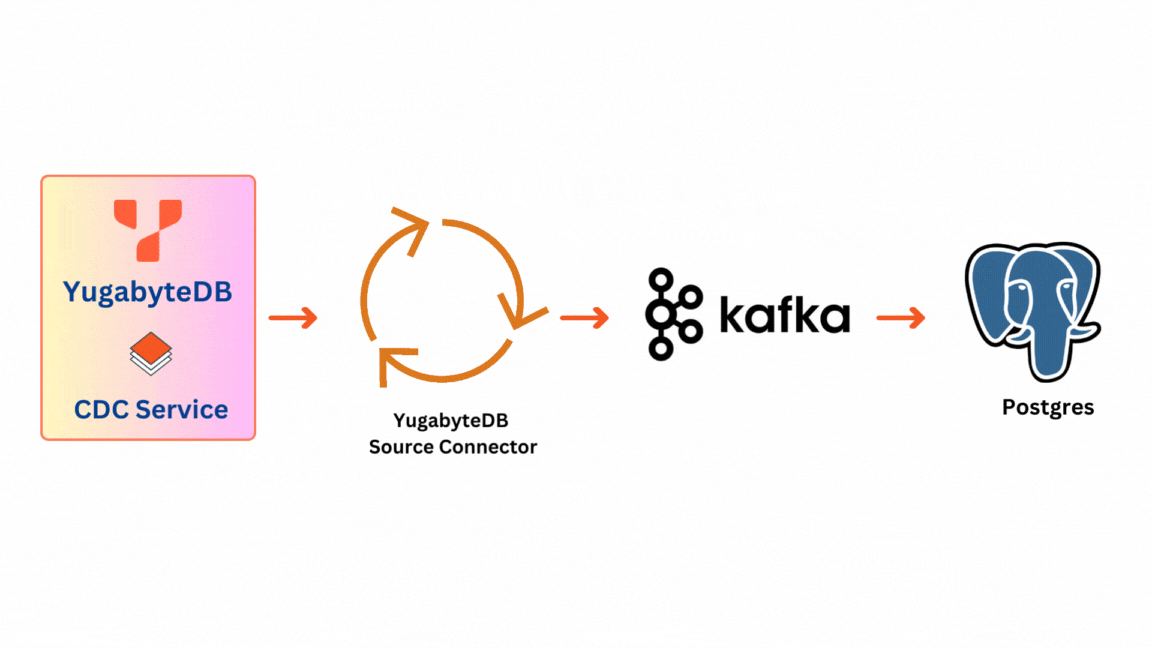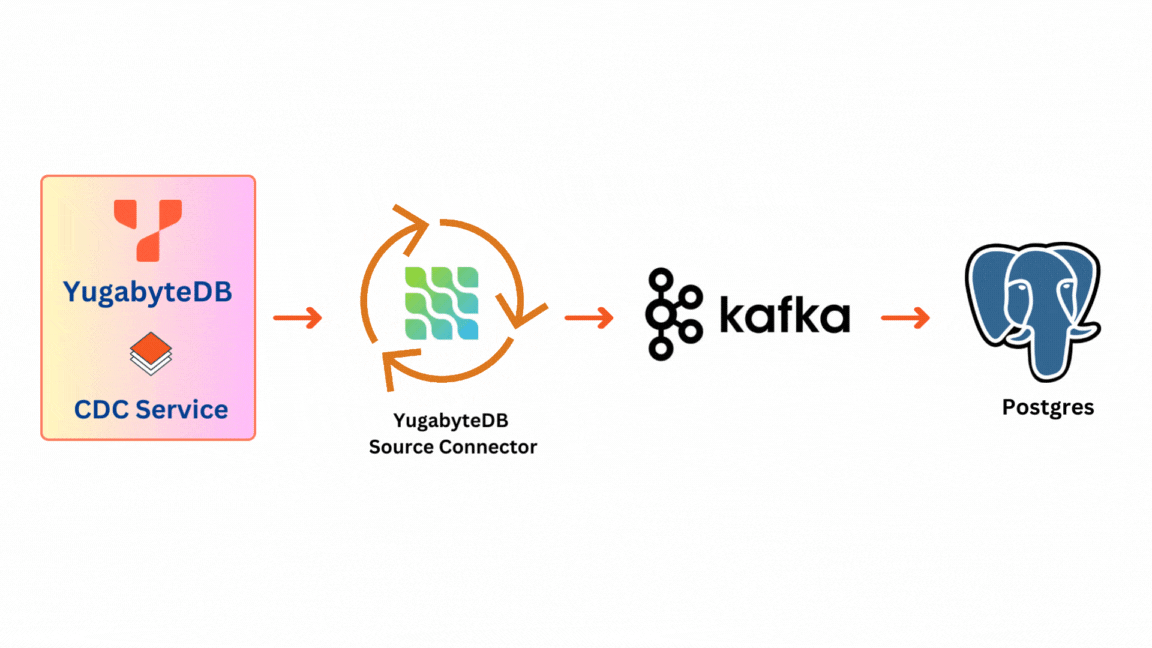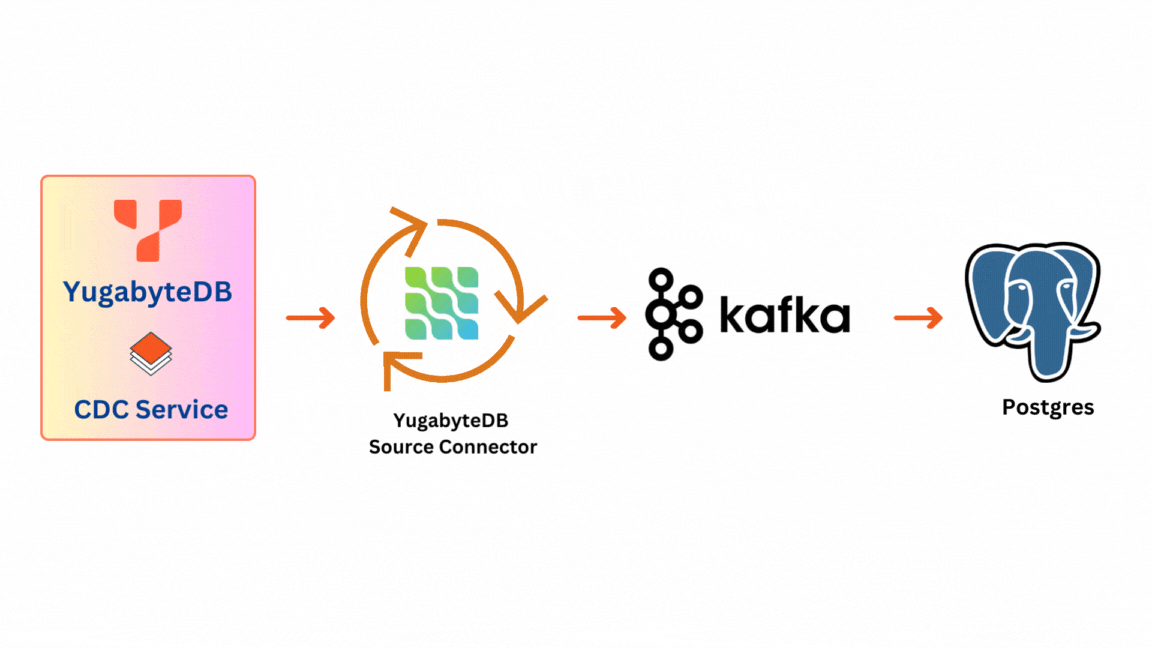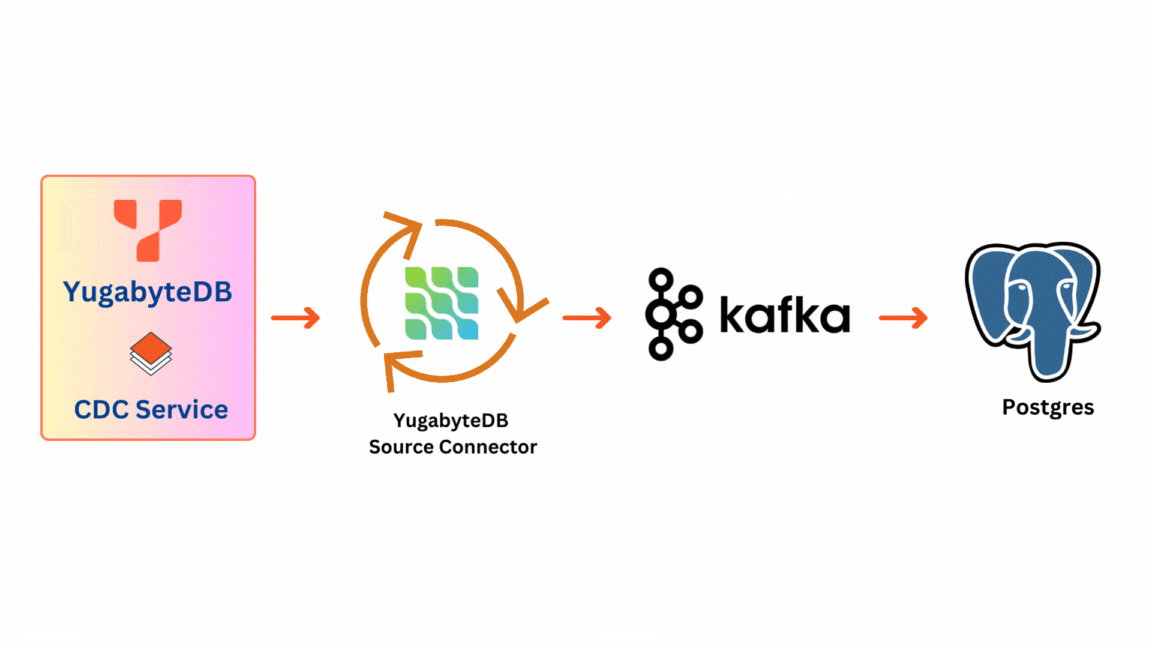
There are 2 main components to the solution:
- YugabyteDB CDC Stream: This originates at the database level within YugabyteDB. Each Tserver node holds a CDC Service that manages it. It provides access to change data from all tables in a given database.
- YugabyteDB Source Connector: The YugabyteDB Source Connector acts as a YugabyteDB stream client. It captures row-level changes in YugabyteDB database schemas and pushes change records to a message queue—a Kafka topic designed for that table.
Once messages are pushed to the Kafka topic they become available for consumption by various applications. In the context of our testing, we utilize PostgreSQL as an illustrative sink for data validation, although any Kafka consumer can serve as a sink.
Testing Without Chaos. Let’s Visualize the Difference
While we have a vast array of unit test cases that cover CDC testing within specific functional areas, a cornerstone principle since Day One has been the pursuit of extended, continuous testing. As a result, we cultivate an ever-evolving collection of prolonged test cases that incorporate an array of YugabyteDB’s features.
These test cases resemble marathons rather than sprints. We subject the system to prolonged tests, spanning ‘n’ number of configurable hours through iterative cycles.

In simpler terms, without chaos, each iteration would involve flooding the system with data and carefully checking if it travels down to PostgreSQL through Kafka. The core idea driving this approach was to replicate extended scenarios, uncovering challenges that might not manifest in our unit tests. However, reality is far from straightforward; it often descends into the chaotic world of unpredictability, setting the stage for our next chapter.
Infuse Controlled Chaos for System Improvement
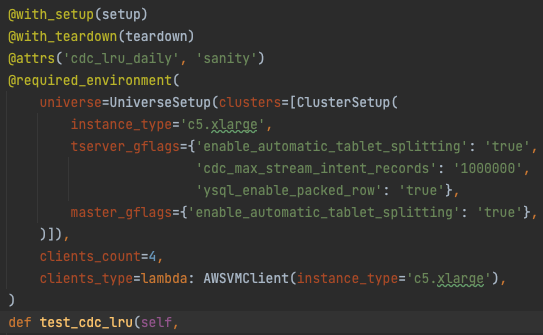
- Establishing the Playground: Setting Up the Chaos Testing Environment for CDC Case Study. We establish a multi-node configuration of YugabyteDB which comes with 2k+1 fault tolerance, allowing for adjustable parameters. For instance, the selection of instance types for YugabyteDB nodes or clients aligns with the specific workload demands. Additionally, we possess the capability to configure gflags, as demonstrated in the example below, to optimize cross-functional CDC testing.In this case, we’ve set enable_automatic_tablet_splitting (which is on by default from 2.18.0), ysql_enable_packed_row, and cdc_max_stream_intent_records.

Configuring multi-node test environment with required settings The orchestration continues through a containerized Docker setup for the pipeline. Leveraging the efficiency of Docker, we streamline the testing process by setting up Kafka Connect, Zookeeper, and Kafka Docker containers for our CDC solution. We also initiate a PostgreSQL instance to serve as the sink, catering to real-time verification needs during testing.
For Zookeeper, we deploy a Docker container using the following command:
docker run -d --log-opt max-size=10m --log-opt max-file=2 --name zookeeper -p 2181:2181 -p 2888:2888 -p 3888:3888 debezium/zookeeper:<version>
To establish the Kafka environment, we utilize the following command:
docker run -d --name kafka --log-opt max-size=10m --log-opt max-file=2 -p 9092:9092 --link zookeeper:zookeeper -e ADVERTISED_HOST_NAME=<HOST_IP> debezium/kafka:<version>
Then, we deploy Kafka Connect using this command:
docker run -d --name connector -p 8083:8083 --log-opt max-size=10m --log-opt max-file=2 \ -e GROUP_ID=3d18a5 -e CONFIG_STORAGE_TOPIC=my_connect_configs_3d18a5 \ -e OFFSET_STORAGE_TOPIC=my_connect_offsets_3d18a5 \ -e STATUS_STORAGE_TOPIC=my_connect_statuses_3d18a5 \ -e BOOTSTRAP_SERVERS=<HOST_IP>:9092 \ quay.io/yugabyte/debezium-connector:latest
Next we proceed with the creation of the CDC StreamID and the deployment of the connector. An illustrative example of this process can be found at How to Integrate Yugabyte CDC Connector.
- Designing Controlled Chaos: Crafting Chaos Test ScenariosLets dive into the craft of devising chaos test scenarios that mirror rare but plausible failures. Our ultimate aim? To ensure our product thrives even in the harshest of circumstances, a testament to one of YugabyteDB’s unique selling points. Keeping that in mind, we have below chaos scenarios running in parallel.
Server side chaos:
- Restart TServer process on nodes: In this scenario, we simulate a crash and subsequent revival of TServer process on a node of YugabyteDB. When data is written to YugabyteDB, it’s first recorded in the write ahead log (WAL) to ensure durability. Later, it’s applied to the actual data files. If a TServer process crashes, the changes recorded in the WAL can be used for recovery and ensuring data consistency. Through this chaos, we gather insights into how YugabyteDB CDC streaming adapts to unexpected outages and resumes operation without losing data integrity or replication.
- Restart Master processes on nodes: Similar to TServer, we simulate a crash and subsequent revival of the Master process on a node of YugabyteDB. When data changes are written to the WAL, the master process is involved in overseeing the replication of these changes to other nodes in the cluster. It also manages the distribution of tablets (shards of data) and coordinates the overall data placement and availability across the nodes.
- Slowdown network nodes: Slowing down network nodes evaluates YugabyteDB CDC’s resilience to network latency. This mimics real-world scenarios where network bottlenecks might affect data transmission and highlights the system’s ability to handle such challenges. We randomly choose nodes and adjust the network speed to a configurable value.
- Partition network nodes: We create deliberate network partitions to mimic network failures and disruptions. The network is intentionally divided, isolating nodes from each other. The objective is to observe how YugabyteDB CDC responds to this network segmentation, which can occur due to network outages or other unforeseen circumstances.
- Rolling Restart: We simulate a controlled sequence of Universe node restarts, one after the other to apply changes. This situation mimics instances where system maintenance, updates, or other operational tasks necessitate restarting nodes within the YugabyteDB cluster. An example would be while doing gflag update on Universe. Here we ensure that while one node is being restarted, others continue to function without disruption. As the restarted node rejoins the cluster, YugabyteDB’s CDC mechanism must adapt and ensure that no data is lost during this transition.
- Stop/Start node VMs: Here we simulate abrupt halts and subsequent restarts of node VMs after some random time. This mirrors situations where VMs might encounter sudden shutdowns and then resume operation. By scrutinizing how YugabyteDB CDC handles the interruption and re-establishment of data flow, we gain insights into its resilience and recovery mechanisms.
- Restart node VMs: Similar to the previous scenario, this chaos tests the system’s response to complete VM restarts.
- Restart Only Leader: Isolating the leader node VM and restarting it reveals the CDC’s ability to adapt when a leader node undergoes disruption. It showcases how the system manages leadership changes without data loss.
Client side chaos:
- Restart source connector in an aggressive manner: Restarting connectors aggressively simulates abrupt failures or restarts of connector instances. This chaos evaluates the CDC’s response to connector disruptions. We restart it every minute and this could be one example of a non-realistic frequency of chaos, but it helps us to catch even the most corner case issues that could occur.
- Pause/Resume source connector: This chaos entails temporarily halting the data streaming process carried out by the connector and then allowing it to resume its data capture and transmission tasks from the exact point where it was halted. This behavior ensures that no data is missed or left behind during the pause period, maintaining data integrity and synchronization between the source and destination.
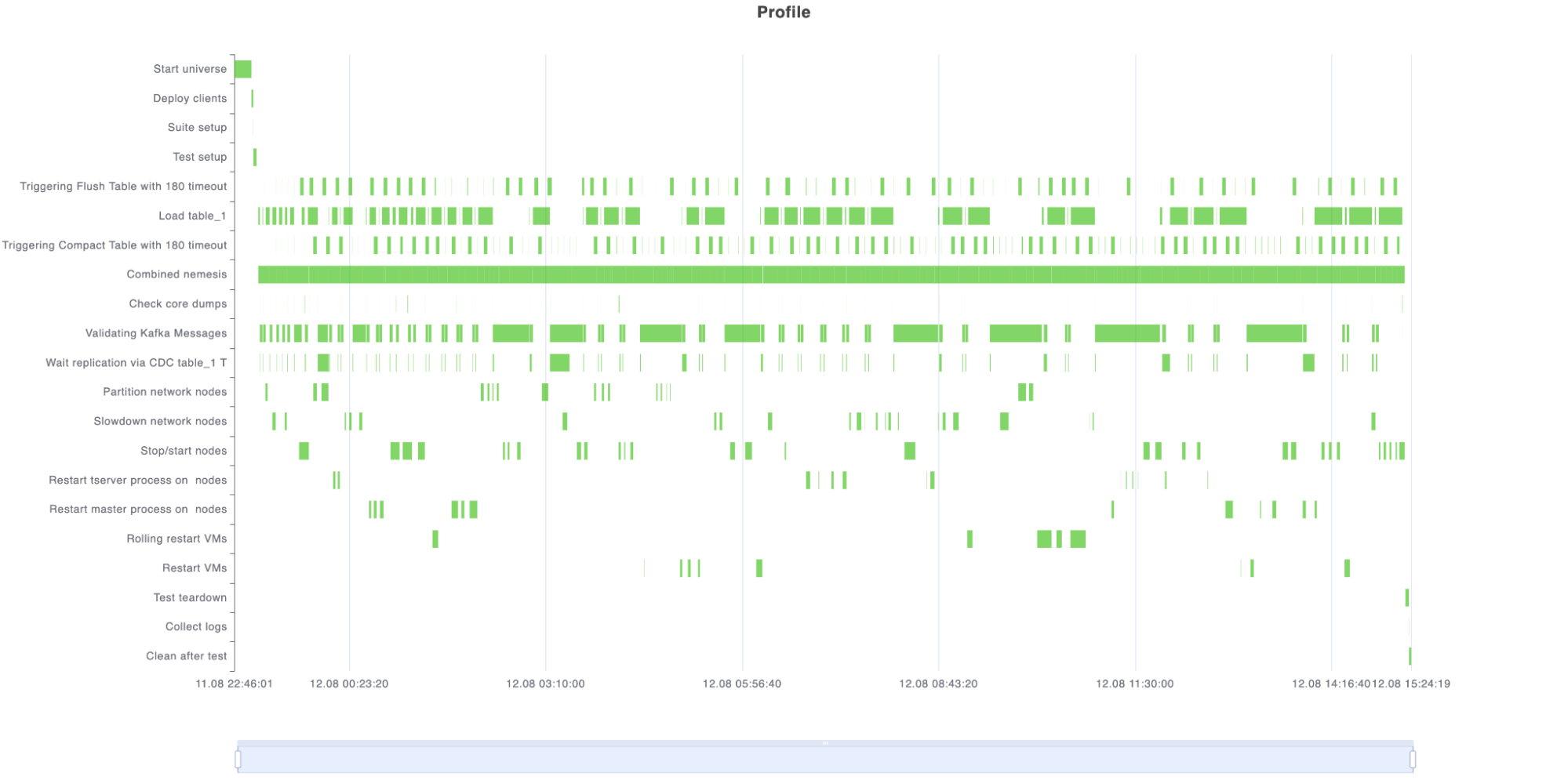
This is how the sample report looks: on the Y-axis, you can observe the steps being executed, which includes the chaos scenarios. The duration of each specific step is indicated by the corresponding green cell. It’s akin to performing chaos and then restoring it to the correct state, forming a single step – symbolized by a green cell in the respective chaos row.
Sample chaos report
Randomization and Probability Scope in Test
While we have functional tests that play a crucial role in ensuring specific functionalities work as intended following a predetermined sequence of rules, long-running chaos tests examine the response to unpredictability. For instance, the timing and duration of each chaos step are randomized, resulting in unique runs. The advantage of this is the ability to identify multiple interesting issues, although with the trade-off of potential repetitiveness in certain cases.
However, by reporting ample amounts of data, logs, and metrics, these drawbacks are mitigated, as well-equipped data will assist in our understanding of challenging situations and provide practical insights into system behavior. For example, in the CDC case, once the test completes, we have access to universe node logs, YugabyteDB source connector logs, different CDC component logs, extracted core files if there is a crash, and more.
CDC-Specific Verifications
- CDC Replication and Data Loss Check: Our main goal is to verify CDC replication, so after each iteration, we compare the source YugabyteDB with the sink PostgreSQL. This process helps us catch data loss problems, which is very interesting during tablet splitting, CDC snapshot, CDC streaming phases, and more.
- Impact on Primary Cluster: Since CDC operates as an extension of the primary cluster, our testing process involves traversing the same DST (Distributed Storage layer) and LRT (Query layer) in our test cases. We monitor the impact on the primary cluster, checking for crashes, cores, and FATAL logs in a separate thread. This also helps reveal any primary cluster issues that might arise from chaos events.
- Managing Garbage Collection: CDC reads from WAL files and IntentDB; while it reads changes, garbage collection (GC) is postponed. However, after reading changes, it’s crucial to ensure proper GC occurs post-streaming. Neglecting this can burden the source system and lead to potential performance degradation, such as a lag in reads within the Yugabyte cluster.
- Yugabyte Source Connector Check: By constantly asserting the status of connector tasks, we find out if any issues occurred in the CDC connector. If any issue did occur in CDC, we check connector logs to spot exceptions, gaining information into any connector-related issues and understanding the root causes.
Chaos testing is a broad spectrum that involves various aspects, from functionality and resilience to performance metrics and user experience. It allows you to better understand system behavior and virtually assess anything you want by introducing chaos. It is constantly evolving, and our team plans to integrate other aspects into our testing roadmap.
Outcomes and Takeaways
As we navigated the domain of chaos testing, a number of valuable outcomes surfaced. This phase wasn’t just about inducing chaos; it was about learning from the chaos.
- Interesting Issues Discovered: Our satisfaction stems from uncovering a substantial number of issues (100+), encompassing high-severity instances. That is what testing is all about, after all. These critical findings highlighted vulnerabilities and risks that could disrupt data integrity, recovery, and performance. Successfully addressing these issues boosted system resilience and reliability. We have now extended these tests to cover other features of YugabyteDB, as they have proven effective.
- Better User Recommendations: The power of chaos, along with long-running scenarios, paved the way for refined recommendations. These include insights on memory requirements, retention period settings, space utilization, optimal configurations, and more.
- Reality-Driven Resilience Mindset: With chaos scenarios resembling real-world failures, our understanding of system behavior has increased, resulting in a proactive approach to resilience integrated into our mindset.
- Continuous Improvement Through Iteration: Chaos testing supports a cycle of continuous improvement. Insights gained from each chaos test iteration can be used to refine processes, enhance the system, and optimize recovery strategies, fostering an environment of ongoing improvements.
Conclusion
Chaos testing is a technological stress test akin to top-tier athletes preparing for the Olympics. Just as elite athletes train through rigorous drills to excel under pressure, chaos testing subjects our systems to extreme scenarios. It’s just not about breaking the system; it’s about understanding its limits, identifying potential breaking points, and ensuring recovery when pushed. The introduced chaos isn’t destructive; it’s creative, molding resilient systems to thrive in uncertainty—a testament to our dedication to a trustworthy and resilient solution.


