YugabyteDB Testing Approaches: An Insider’s Guide
January 12, 2023
YugabyteDB is a cloud-native database for business-critical enterprise applications. It is designed to provide continuous availability as well as horizontal scalability, while retaining a strong set of RDBMS features. This objective creates a strong quality incentive for us in the Yugabyte Quality Assurance (QA) team. As a member of this team, I am giving an overview of the testing philosophy, approaches, and implementations for YugabyteDB.
In this blog post I focus on the core database product I work on. While some of the approaches described here are also applicable to our other products, such as YugabyteDB Anywhere and YugabyteDB Managed. They are not covered in detail and are topics for separate blog posts.
Testing Philosophy
The database is often the most critical part of a complex system. It functions as the source of truth by being the central store of data and its relationships. For this reason the correctness and reliability of a database management system (DBMS) are of paramount importance. This explains why there has been research into the best ways to test database systems from the very beginning.
By measuring code coverage you can discover the absence of tests covering a particular part of code. Unfortunately the opposite is not true. A part of code being covered does not imply that it is tested well, merely that there is a single path through the code in question which does not lead to a crash. This is not a sufficient goal for any software, let alone a DBMS. So blindly trusting coverage data is not the solution. Instead you need a tool to evaluate which tests should be written. See the “How to Misuse Code Coverage” article for a more detailed explanation.
A testing team’s goal is to catch bugs before customers find them, often by thinking of corner cases and how features interact with others, which developers may not have considered. The issues we file should ideally be minimal, reproducible, and contain enough information to be understood by developers based on the log files. We should try to find issues with the simplest and least powerful form of test possible, only moving to more complex testing where necessary.
On one end of the testing spectrum we have unit tests, which should be as simple as possible, covering a single part of the source code of the program. A unit test should ideally only take a few milliseconds and, if it fails, point directly to the line of the problem. On the other end of the spectrum, we have full customer scenarios that we can execute, which might run for hours and fail sporadically. In between is where most of our testing happens, and this is what I’m going to discuss.
Manual testing has some value; you get an initial look of a feature and it is quick to run once. But in the end, all tests have to be automated so that each new build can be verified against them and regressions prevented. If you try to blindly automate every combination you can think of, you will quickly run out of time. The huge search space of SQL queries, possible server configuration flags, plus other features are the perfect ingredients for a combinatorial explosion. So, in the end we have to consciously decide what is interesting to test and where failures are expected.
For every issue that has occurred before a regression, a test should be written to verify that the same issue will not reoccur. The issues that we, and other YugabyteDB users, run into can decide which part of the huge testing search space we should expand into next.
After filing the issues found in testing, in an ideal world they should get fixed quickly. In the real world there are other pressing concerns (customer issues, etc.) that can take priority. To cut down on the time it takes to triage automatic test runs, it makes sense to automatically ignore known issues which have not been fixed yet, for example by matching the specific failure using a regular expression. When the issue is fixed the corresponding ignore command has to be removed. Until the issue is fixed the test in question will have limited value, as it can’t reach the end of its runtime, which could reveal other issues. This is why it’s important to quickly fix issues which block testing, especially when multiple tests are affected.
Sporadic test failures can be difficult to reproduce. In this case high-quality log files save time and are the best way to understand the issue. With an automated test suite, additional logging can be added into the application after the issue was discovered. This means it will provide more information on the next test run. An additional approach for hard-to-reproduce issues is to use a tool like rr, which records the exact execution, allowing you to replay it in a debugger.
Testing Approaches
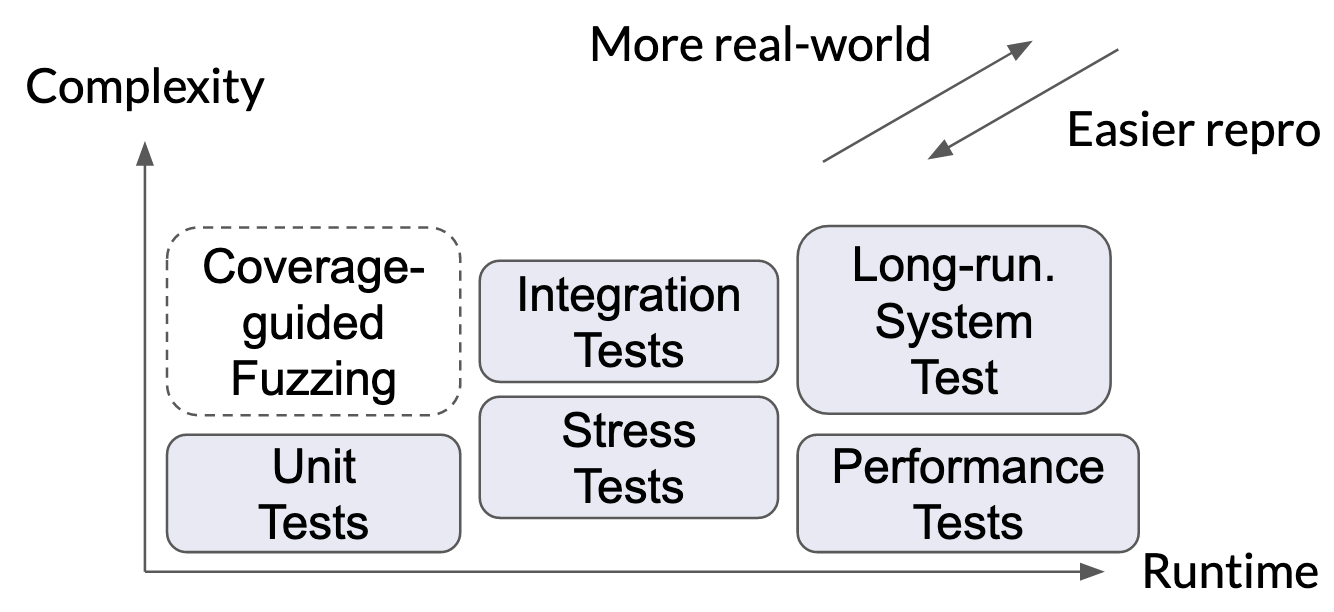
There is no one-size-fits-all approach to test an entire database system. So, we use a wide range of testing frameworks and tests, some our own, some adapted and extended from existing open source solutions. Below is an overview of some of the approaches we utilize.
Unit Tests
A unit test, in its usual definition, tests an individual unit of source code (such as a function or class) and is usually written in the same programming language as the source code—C++ in our case. Most “unit tests” at YugabyteDB in our more far-ranging definition, are tests run against a slimmed-down simulation of a local universe, which might be a single node. These tests are usually implemented in Java as well as SQL input files with corresponding outputs. Developers are primarily responsible for writing these tests for their own features. Runtime for them should be short since they will be executed for each new change, as part of our continuous integration process.
YugabyteDB provides multiple frontends: YSQL (PostgreSQL-compatible) as well as YCQL (Cassandra-compatible). I’ll focus mostly on the YSQL approach here, since this fully relational API is PostgreSQL compatible and the way to go for most applications migrating to YugabyteDB.
YugabyteDB achieves PostgreSQL compatibility by reusing part of the PostgreSQL source code and replacing the storage with our own. We also uset the extensive regression test suite of PostgreSQL. We have ported versions of these tests in our product code repository, which you can recognize by their yb_ prefix. As these tests are part of the public repository, every YugabyteDB user can execute them. See our documentation for more details.
To achieve coverage for our wide range of customers, we run the unit tests on multiple operating systems (Centos, Ubuntu, macOS), with multiple compilers (Clang, GCC), with different CPU architectures (x86-64, aarch64), using AddressSanitizer as well as ThreadSanitizer builds. These sanitizers are one of the most important recent developments in making C and C++ code safer as they detect data races, memory leaks, and errors, earlier in the process. However, their effectiveness depends on the quality of tests available.
Once a new change is pushed to Phabricator—‚the tool we use for code reviews to reduce turnaround times—we spin up spot instances to run the required builds and subsequently the test suites in a massively parallel manner. As a result,we can often provide meaningful test results by the time a human reviewer starts to review the change in question.
Since the unit tests are run and analyzed on each change, it’s essential that they produce as few false positives and sporadic failures as possible. We use an internal tool called Detective to detect failures in the test runs and warn developers about potential regressions being introduced by their change before submission. Already-broken tests are marked and ignored for this process until the corresponding issue is fixed. In this way, each new test failure requires the change owner to analyze whether the failure is caused by their change. If that’s the case, then an issue has been caught early in the process, before it even lands in the target branch.
Cross-Functional Tests
While the unit tests aim to test features in isolation, our cross-functional test suite provides end-to-end tests that run in a real distributed (multi-node) setup. These universes (or clusters) are created through the YugabyteDB Anywhere API. This is the way that most of our customers are expected to set up YugabyteDB. This test suite, internally called the ‘integration test suite’, is written in Python. As a basic workload we often use some of the YugabyteDB Sample Apps, a public workload generator written in Java to emulate various real-world scenarios.
In these tests we initially combined two features and tested that they work as expected in combination. This goes beyond what is being done in our unit test suite and ends up finding many interesting bugs, which are still relatively easy to understand and reproduce on a real universe.
Recently, we started adding more features together into a single test. This has the advantage of covering more complex scenarios, at the cost of not necessarily being a minimal reproducer. This brings us back to the already-mentioned tension in testing, where blindly testing all combinations separately would be too expensive. By adding further features into a single test we can reduce testing time, but at the cost of some triage time to figure out the responsible components when a test actually fails.
The cross-feature test suite is being run for each new build that we generate, which can include multiple changes on busy branches like our main development branch. Older releases are covered by the same tests, so the tests, which live in a separate internal repository, have to consider what version of YugabyteDB they are being run against.
Upgrade testing is a special case. During upgrade testing, we use a set of features from an older version of the database, upgrade the universe to a newer version, and verify that everything works as expected afterwards. This feature set covers many objects like partitioned tables, materialized views, colocated tables, as well as persisting them in backups. Recently, I have added more extensive verification of the database while upgrading. Since our upgrade process uses rolling restarts, the database user will inevitably get their database connection disconnected, but can immediately reconnect to another server. Providing these kinds of upgrades without downtime is an important advantage of a truly distributed database like YugabyteDB, and so testing it thoroughly is equally important.
Stress Tests
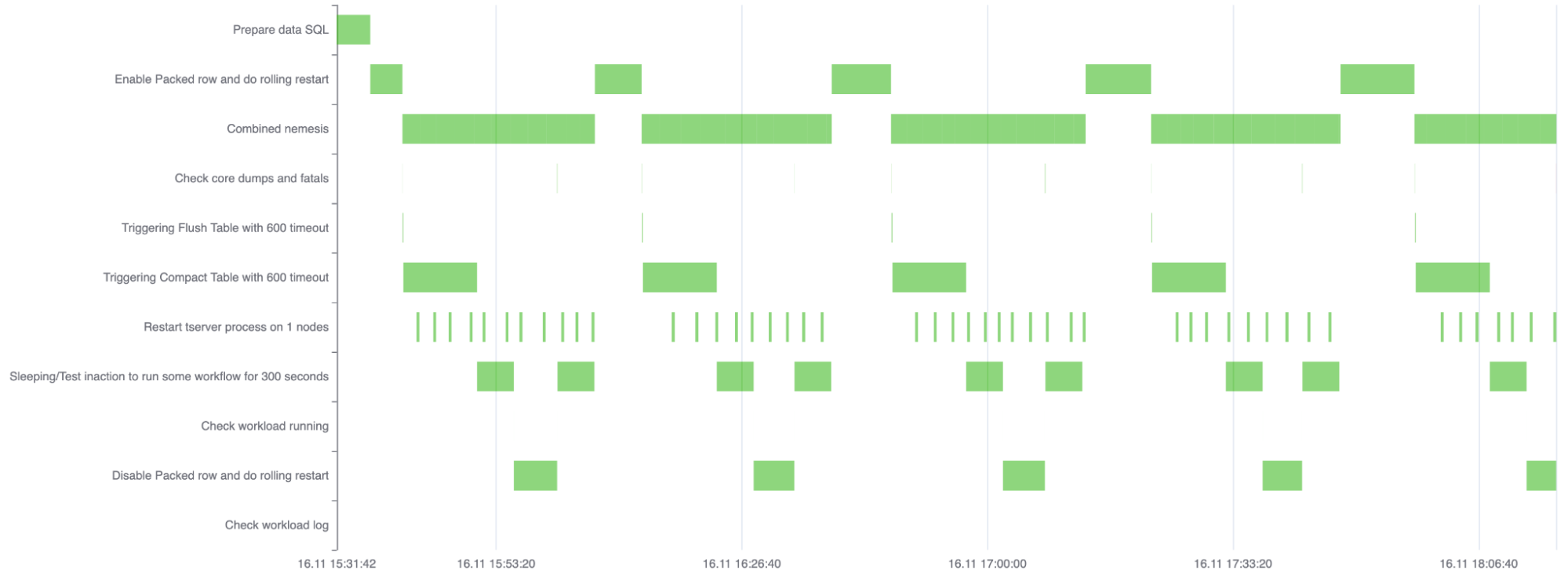
Our stress test framework is run periodically. Its main purpose is to inject failures in the form of nemesis testing and see how the system handles them. The limits of YugabyteDB are explored by running with larger datasets than in other kinds of testing. As they are still fairly simple, the issues can be easily reproduced.
Randomized Testing
I started a new testing framework for randomized testing, called the Long-Running System Test (LST). It provides a YSQL workload in which all operations are decided randomly, but can still be reproduced. For randomized testing it is essential that the seed of each run is documented; with the seed the same queries will be fired against the database again. Unfortunately, timing can still lead to different results, impossible to prevent with concurrent database connections.
On the other hand, running only a single database connection allows you to get the same results on each run. With YugabyteDB’s YSQL layer claiming full compatibility to PostgreSQL, I am excited to be currently working on testing YugabyteDB against PostgreSQL, comparing results for correctness. The remaining step will be to figure out which side actually has the wrong result.
All of the features we consider important to test in cross-feature testing should also be covered in LST. Randomized testing fills the testing gap of what we don’t consider interesting enough to explicitly write a test case for, or has never even considered. This approach, despite its limitations on finding correctness of results, has found about 100 issues so far.
Recently, I started adding different scenarios to the randomized testing suite, to more closely simulate customer scenarios. A simple scenario to periodically switch between a workload phase and a backup and recovery phase, verifying that all of the data is correctly recovered.
Open Source Tools
Our QA team is currently working on adding support for libFuzzer, a coverage-guided fuzzing tool. I’m planning to join these efforts shortly and hope to share more details then. Fuzzing is a good additional approach for the combinatorial explosion I described earlier. As it is coverage-guided, it enables you to get additional coverage of interesting combinations you didn’t consider (thus uncovered), without increasing the runtime too much.
Additionally, we have had good experiences adapting other existing testing tools, like SQLancer to detect logic bugs, plus SQLsmith for generating extremely complex queries. This is another advantage of being PostgreSQL-compatible: Users can easily port applications, and testers can easily port tests too!
Conclusion
There is always a lot to be done in the area of testing, with new features coming in and new testing approaches being used. I have yet to share insight into other areas we are working on, such as performance testing, Jepsen testing, and evaluating the query optimizer. Look out for upcoming posts from the Yugabyte QA team which delve further into how we catch and fix bugs before they ever reach the customer.


