How We Test Distributed PostgreSQL Performance and Scalability
August 5, 2024
YugabyteDB is not just another distributed SQL database. It’s much more. It delivers distributed PostgreSQL that scales and never fails.
At Yugabyte, we are committed to delivering a robust and high-performance distributed PostgreSQL database, backed by extensive and rigorous testing.
To achieve this, our engineering team leverages various benchmarks and testing tools. They use these to verify YugabyteDB’s performance, scalability, transactional consistency, high availability, and PostgreSQL compatibility.
This blog is the first in a series that explains how we test our distributed PostgreSQL database. In this blog we will focus on performance and scalability and share a detailed look into our comprehensive testing framework.
Standard Performance Testing
Our standard performance tests ensure that YugabyteDB consistently delivers high performance across various workloads.
Broadly divided into macro and micro benchmarks, these tests are run nightly to verify the basic operational capabilities of YugabyteDB. This dual approach helps us maintain a robust and scalable distributed PostgreSQL database that meets the demands of diverse applications.
TPCC – 1000 Warehouse Test
- Objective: Basic sanity test.
- Frequency: Daily
- Configuration: 8 vCPU x 3 Node cluster.
- Details: This test runs a TPCC benchmark with 1000 warehouses to ensure the fundamental operational capabilities of the database.
- Reference: Yugabyte TPCC GitHub Repository
The TPCC benchmark simulates a typical retail transactional workload. Running this test nightly helps us ensure that YugabyteDB maintains its performance in the face of complex, real-world transactional workloads.
Sysbench Tests
- Objective: Sanity tests to ensure basic workloads run smoothly.
- Frequency: Daily
- Configuration: 8 vCPU X 3 Node cluster, 20 tables, 5,000,000 rows each
- Details: We run various Sysbench workloads, including:
- Read
- Write
- Read Write
- Update Index
- Bulk Write
- Reference: Yugabyte Sysbench GitHub Repository
Sysbench is used to evaluate the performance of various database operations. These nightly tests cover a range of operations, ensuring that YugabyteDB handles reads, writes, updates, and bulk operations efficiently.
Microbenchmarks
- Objective: Test specific database operations in isolation.
- Frequency: Daily
- Configuration: 283 queries
- Details: The queries fall into several categories:
- Scan
- Write
- Aggregates
- Bulk Load
- Index Scan
- Joins
- Order By
- Locking Semantics
- Reference: Yugabyte BenchBase GitHub Repository
Microbenchmarks are crucial for identifying and optimizing performance bottlenecks.
By testing 283 queries across various categories, we ensure that each database operation performs optimally. By isolating these individual operations, microbenchmarks allow us to test specific query paths within the database, ensuring that each performs correctly.
This granular level of testing is particularly useful during the development process, enabling us to catch bugs early and fine-tune performance for targeted query types.
Scalability Testing
To ensure YugabyteDB scales linearly and performs well under high load, we conduct comprehensive scalability tests. These tests help us verify that the database can handle increasing workloads without compromising performance.
Multi-Region Tests
- Objective: Validate performance across different geographical regions.
- Configuration: 8 vCPU X 3 Node cluster, 20 tables, 5,000,000 rows each.
- Details: Sysbench workloads are tested in a multi-region setup:
- Sysbench Read
- Sysbench Write
- Sysbench Read Write
- Sysbench Update Index
Multi-region tests simulate a global deployment of YugabyteDB. By running Sysbench workloads across geographically distributed nodes, we ensure that the database provides consistent performance worldwide.
Scale-In and Scale-Out Performance
- Objective: Measure performance before, during, and after scaling.
- Frequency: Daily
- Scenarios:
- Scale-in: Start off with 6 nodes, RF3 setup. Run Sysbench oltp_read_only workload (performing only read queries) before, during and after the scale-in operation where nodes are reduced to 3 (half the original count). The expectation is that latencies may increase during and after scale-in operation, but the database remains operational.

X-axis: YugabyteDB builds, Y-axis: latency in milliseconds. - Scale-out: This is the inverse scenario of above, where we start with a 3 node setup and scale out to 6 nodes (doubling the original count). The expectation is that latencies should improve as we added more nodes to handle the application load.
X-axis: YugabyteDB builds, Y-axis: latency in milliseconds.
- Scale-in: Start off with 6 nodes, RF3 setup. Run Sysbench oltp_read_only workload (performing only read queries) before, during and after the scale-in operation where nodes are reduced to 3 (half the original count). The expectation is that latencies may increase during and after scale-in operation, but the database remains operational.


Scaling operations are essential for adapting to changing workloads. We measure the performance of YugabyteDB before, during, and after scaling in (reducing nodes) and scaling out (adding nodes) to ensure seamless scalability.
Large Scale 100,000 Warehouse TPCC Runs
- Objective: Stress test with a large-scale TPCC benchmark.
- Frequency: Fortnightly
- Configuration: 59 instances of c5d.9xlarge type, RF3 YugabyteDB cluster having 7TB unreplicated (21TB replicated rf3) data. 40 TPCC application instances making 150 DB connections each (6000 connections in total) making ~1.2 million transactions per second (Tpmc)
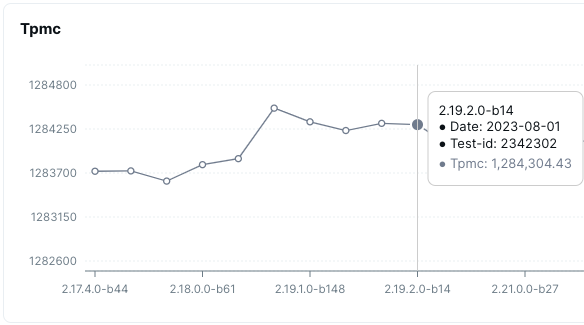
To simulate extremely high-load scenarios, we run a TPCC benchmark with 100,000 warehouses using 59 instances of c5d.9xlarge type. This stress test validates the database’s performance under the most demanding conditions.
Cluster Operations Testing
Ensuring that YugabyteDB maintains high performance during cluster operations is crucial for operational reliability. These tests evaluate the impact of various maintenance and management operations on database performance.
Backup and Restore Performance
- Objective: Evaluate the impact of backup and restore operations on performance.
- Frequency: Daily
- Scenario: Load the data into YugabyteDB using Sysbench and run the oltp_read_only workload before, during and after the backup operations. We also measure the time taken for backup.
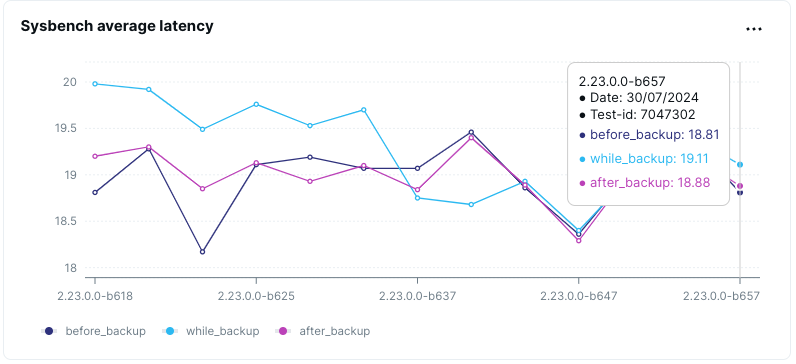
Regular backups are vital for data protection. We test the impact of backup and restore operations to ensure they can be performed without significantly affecting ongoing workloads.
Incremental Backup Performance
- Objective: Test the efficiency and impact of incremental backups.
- Scenario: Run Sysbench oltp_read_write workload (performing a mix of read, write and update queries) before, during and after incremental backup operation.
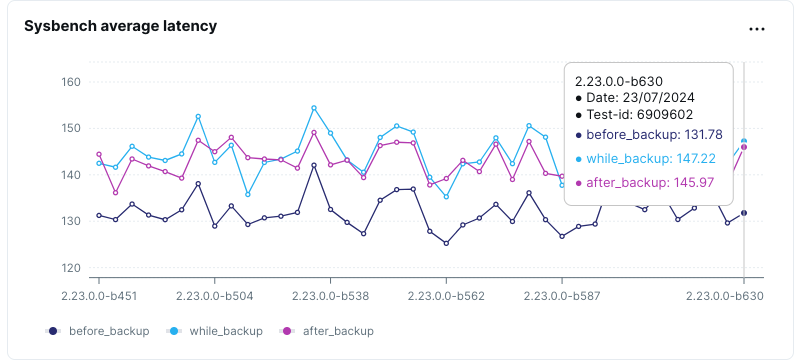
Incremental backups are more efficient than full backups, but it’s essential to ensure they do not compromise performance. We evaluate the performance impact of incremental backups to validate their efficiency.
Rolling Upgrade Performance
- Objective: Measure performance before and after upgrades.
- Scenario: Start off with a lower version (say 2.20.0.0) of YugabyteDB and upgrade it to a higher version (say 2024.0.0.0) while a complex workload like TPCC is running on the database.
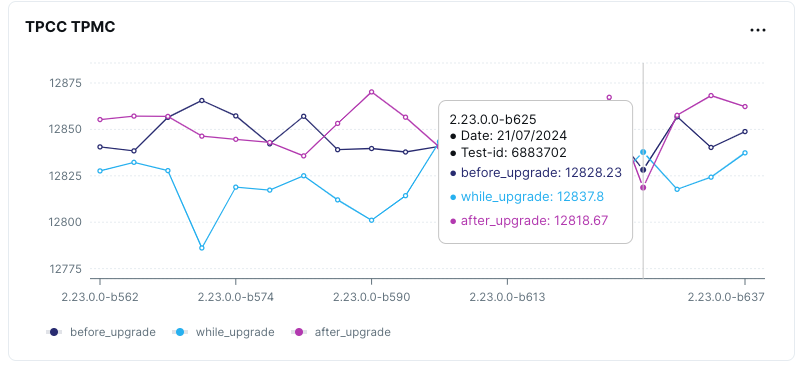
Database upgrades are necessary for introducing new features and improvements. We measure the performance of YugabyteDB before, during, and after upgrades. This ensures upgrades do not introduce regressions, and the database continues to be operational during rolling upgrades.
CDC Performance
- Objective: Analyze performance with and without Change Data Capture (CDC)
- Scenario: Run workloads like Sysbench before, during and after setting up the CDC setup.
- CDC reference
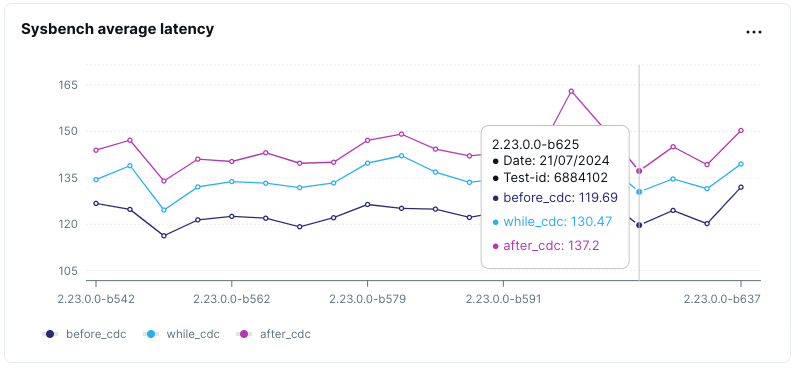
YugabyteDB’s native gRPC Replication Protocol for Change Data Capture(CDC) enables efficient and reliable streaming of data changes using gRPC. This provides high-performance, low-latency, communication across distributed nodes, maintaining consistency and enabling scalable replication.
We test the performance impact of enabling and disabling CDC to ensure that real-time data tracking does not degrade overall performance.
Conclusion
Conducting this extensive and diverse performance and scalability testing ensures that YugabyteDB remains a reliable and high-performance distributed PostgreSQL database, ideal for handling mission-critical, global-scale, applications.
Our commitment to thorough testing and continuous improvement allows us to provide our users with a robust and scalable database solution.
Want to Learn More?
- This recent YugabyteDB Friday Tech Talk discusses how High Availability and Continuous Availability is implemented in YugabyteDB
- This YugabyteDB Friday Tech Talk offers a Deep Dive on Using YugabyteDB’s Change Data Capture Connector
- Download today to experience the built-in resilience, seamless scalability, and flexible geo-distribution of PostgreSQL-compatible YugabyteDB.


