How to Build a RAG Workflow for Agentic AI without Code
October 27, 2025
What is RAG and Why Should I Care?
YugabyteDB offers the familiarity and extensibility of PostgreSQL, while also delivering extraordinary scale and resilience. Thanks to the pgvector PostgreSQL extension, it also functions as a highly performant vector database. Its scalability allows it to store and search billions of vectors.
This two-part series starts by explaining why a vector database is essential to agentic AI and how YugabyteDB meets key requirements for global organizations, including data sovereignty and zero-downtime.
In the second part of this series, we will demonstrate how you can easily leverage this technology to provide AI with your organization’s information using n8n, a no-code orchestration tool.
Artificial Intelligence
AI agents are reasoning Large Language Models (LLMs), like OpenAI’s ChatGPT 5 or Google’s Gemini 2.5 Pro, with access to tools.
Reasoning models are successors to first-generation LLMs, and they can iterate, or “think harder” about the problem, to provide higher-quality responses. Their tools allow them to act as well as ‘speak’ to fulfil complex tasks. For example, they could retrieve additional information, make purchases, or send emails.
AI agents differ from automation because they don’t need to be pre-programmed with precise, repetitive steps. Imagine an AI employee who can create a presentation, manage your calendar, or review product designs with just a short brief.
The standard mechanism that allows an AI agent to use tools, such as a database, email account, or your calendar, is called Model Context Protocol (MCP). We’ll look at MCP in a future blog post.
AI Agents
So, this sounds great – an AI employee can carry out tasks typically associated with knowledge workers. In contrast to a new hire, they’ll likely be quicker and create a more polished output. Human employees, however, still have cards up their sleeve… they can refer to manuals, order forms, meeting minutes, and the wealth of historical documents that every business has. While an AI agent’s LLM is trained on this sort of material from the public domain, it doesn’t have any insight into an organization’s private information.
Another benefit a human employee has is their ability to learn over time to do a better job. Long-term memory for AI is the subject of academic research, and given the pace of development, it is probably not far away.
Retrieval Augmented Generation
To help level the playing field for the AI agent, we can use Retrieval Augmented Generation (RAG). This allows the agent to access private, organizational information in the form of unstructured data when forming its response. Imagine your AI agent is starting its first day with your organization’s own reference material at its fingertips.
RAG works by:
- Pre-processing non-public data by
- Extracting text from documents
- Splitting the text into chunks
- Converting each chunk into vectors (numbers) with an embedding model
- Storing the vectors in a database
- When a user’s prompt arrives the LLM can generate a query for the vector database, which is
- Converted into vectors
- Which are used for a similarity search of the database
- Resulting chunks of similar text are passed back to the LLM
- The LLM now processes an augmented, richer prompt
Vector Databases
A vector database enables semantic search, which allows you to find content with a similar meaning even if it doesn’t include the same text. It also avoids finding information with the same text but a different meaning.
| Role | Needs information related to | Semantic search result |
|---|---|---|
| Health assistant | “Drinking more and going to the toilet often” | May find “symptoms of hyperglycemia include frequent urination and increased thirst” |
| Developer | “Create Python list” | Would not find lists of animals, as the request relates to a programming language |
| Lawyer | “Contest will” | May find “challenging probate document validity” but not a sporting competition with someone called Will |
The AI agent can use the vector database as a tool to help it retrieve relevant context for its task. It can quickly access relevant documentation, meeting minutes, emails etc. This allows it to determine whether a party in a civil law case had mentioned a particular purchase, or recall the details of a contract signed many years before.
YugabyteDB is a vector database with enterprise scale and resilience. It supports critical RAG workloads, providing AI agents with knowledge of your unstructured data.
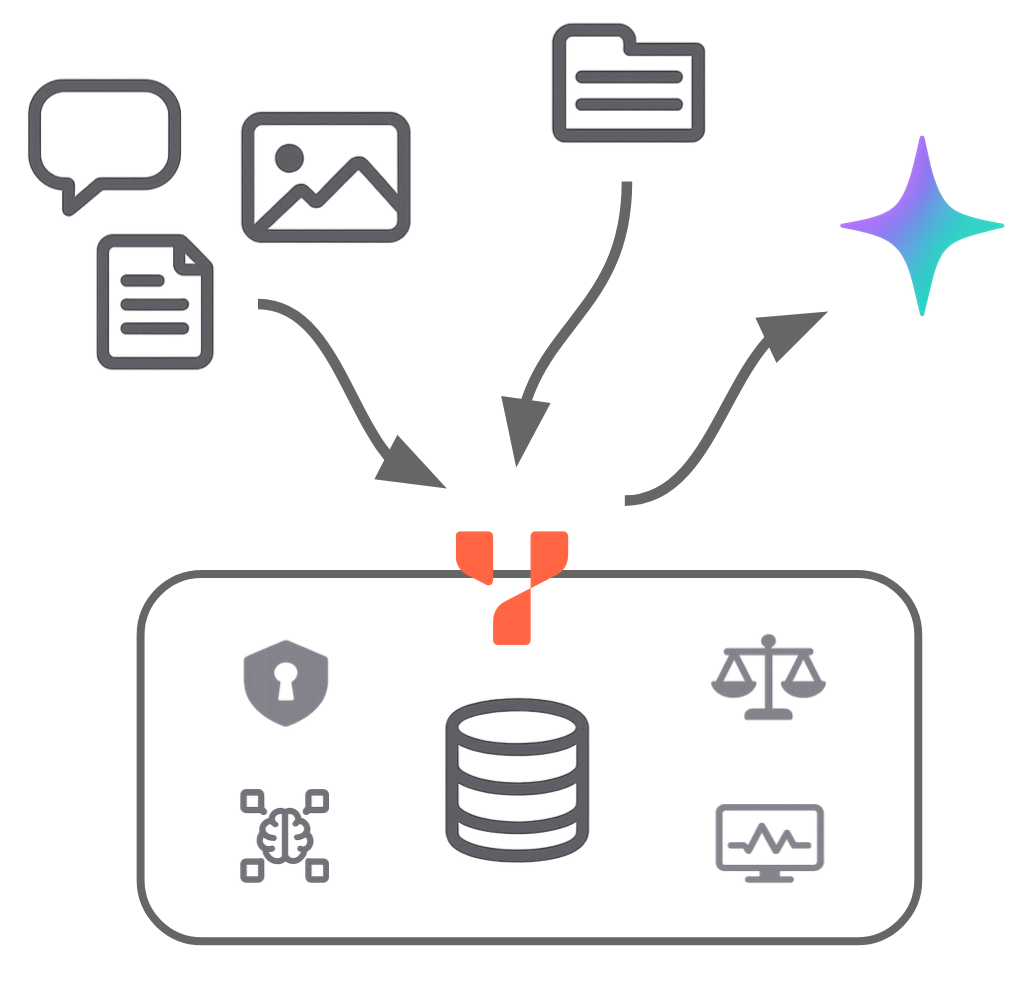
YugabyteDB’s familiar PostgreSQL interface accelerates development and enables access to a wide ecosystem. It manages structured, relational data alongside unstructured, vectorised data in a unified platform.
Using YugabyteDB for a RAG Application
To help demonstrate the benefits of using YugabyteDB to search vectors at scale, we’ll use n8n, a popular visual workflow tool, to create an ingestion pipeline. Our workflow will feature an on-demand trigger to vectorize unstructured data and a chat trigger to interact with AI agents that have access to that data.
Scenario
Yuga Readers is US-based reading group, formed to share a love of good literature. However, reading takes time, so we decide to create an AI agent to help answer readers’ questions. To give the agent greater insight, we’ll use RAG to give it access to the text of the books. This also allows the agent to provide specific references to the text when answering questions.
We’ll use Project Gutenberg to obtain public domain reading material. We start with Arthur Conan Doyle’s classic Sherlock Holmes novels.
Over time, Yuga Readers takes off, and we open a second chapter in Europe (pun intended). The European readers, however, are behind on our reading list. To avoid spoilers, we need to ensure that the Yuga Readers AI agent only has access to the stories that have been read by the group in each location.
Geo-placement
As a distributed database, YugabyteDB can host a single logical database while placing data in specific geographical locations. This can help meet data sovereignty requirements or provide location-specific context to some AI agents, while allowing others to access all context.
To do this, YugabyteDB leverages standard PostgreSQL constructs. The table of vectors is partitioned into two child tables, one per location, which are allocated to tablespaces which are in turn allocated to nodes in those locations. You can read more about this here.
AI agents using one of the child tables (also known as partitions) can access only the vectors permitted for that location; agents using the parent table can access all vectors across both locations.
The n8n workflow will create the required tablespaces, tables, and partitions in advance.
Setup
The following steps are explained in detail with a live demonstration in our video here.

n8n and a two-node YugabyteDB universe (cluster) can be installed in Docker/podman with Compose. You can retrieve the files you’ll need from our GitHub repository here. Clone or download them to your local machine.
There are a few prerequisites for this demonstration:
- An LLM compatible with the OpenAI API standard/n8n. We will use Anthropic, which requires an API key. There are many other providers, or you can use Ollama to run an open source API model locally on your machine.
- Ollama to run an embedding model to convert chunks of text into vectors. You can get it here. It’s possible to run Ollama in Docker, but if you have AI acceleration hardware you should run it locally (outside of a container) for best performance. It’s also possible to use an online, commercial AI provider for embedding, such as OpenAI or Anthropic.
- Podman or Docker (and
podman-composeordocker-compose)
It’s worth remembering that this is intended as a demonstration only. Here, YugabyteDB is deployed without resilience to reduce the required resources. A universe with a Replication Factor of 1 (RF1) is not suitable for a production environment.
Installation
To deploy the n8n and YugabyteDB containers, run the following commands:
# Retrieve the embedding model with Ollama, which is installed locally ollama pull mxbai-embed-large:latest # Deploy the containers (may need to use docker in place of podman) podman-compose up --detach
Then, visit n8n in a browser at http://localhost:5678 and create your user account. You don’t need to request a license key.
Credentials
On the n8n home page, select the drop-down next to Create Workflow and click Create Credential.

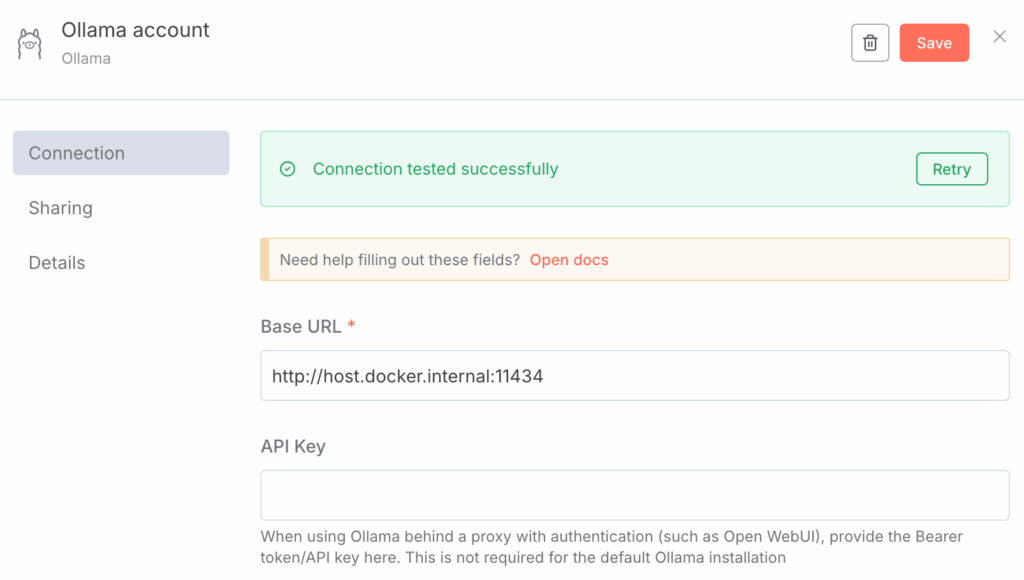
Select Ollama as the Credential Type and enter http://host.docker.internal:11434 as the URL to direct n8n (in a container) to Ollama on the host machine.
When saving, you should see a successful connection:
Create another credential for Postgres (actually YugabyteDB, which is compatible):
- Host:
rag-yugabytedb-1 - Database:
yugabyte - User:
yugabyte - Password:
yugabyte - Port: 5433
And finally, add a credential for Anthropic, or whichever AI provider you’d like to use for your LLM.
Creating the Workflow
Click Create Workflow to generate a new workflow. Select My workflow to rename and save the new workflow.
Next, click the three dots in the top right corner and then Import from File…
Import the rag_demo.json file from the GitHub repository.
Many nodes (steps) in the workflow will show red crosses to indicate problems. These are missing accounts/credentials. Simply double-click each node and return to the workflow each time to rectify this.
Creating Vectors
By default, running the workflow will start it from the When clicking Execute workflow trigger.
![]()
The workflow downloads two novels from Project Gutenberg, splits them into chunks, uses an Ollama-hosted embedding model to convert them into vectors, and stores the vectors in YugabyteDB.
YugabyteDB transparently assigns each novel’s vectors to its own tablespace to help ensure that the different chapters of Yuga Readers have access only to the books they’ve read. The USA chapter of Yuga Readers has read The Adventures of Sherlock Holmes, and the European chapter has read The Return of Sherlock Holmes.
The workflow deletes and recreates the public schema in YugabyteDB each time it runs, allowing it to be safely re-run. It then creates a vectors table in which n8n can store vectors. Each vector is assigned to a collection by n8n, which is simply a label denoting the location to which the vector belongs.
The workflow also pre-configures tablespaces and partitions of the vectors table for each location. It instructs YugabyteDB to transparently place new vectors into the correct partition based on its collection.
You can see the allocation of tables to nodes (and therefore collections/locations) in the master UI.
| YugabyteDB node | Location | Novel vectors |
|---|---|---|
| yugabytedb-1 | US East | The Adventures of Sherlock Holmes |
| yugabytedb-2 | EU Central | The Return of Sherlock Holmes |
Leveraging Semantic Search
The workflow has three AI agents, each of which is connected to the same YugabyteDB database, but uses a different geo-restricted table. The When chat message received trigger can be connected to any of the AI agents for testing.
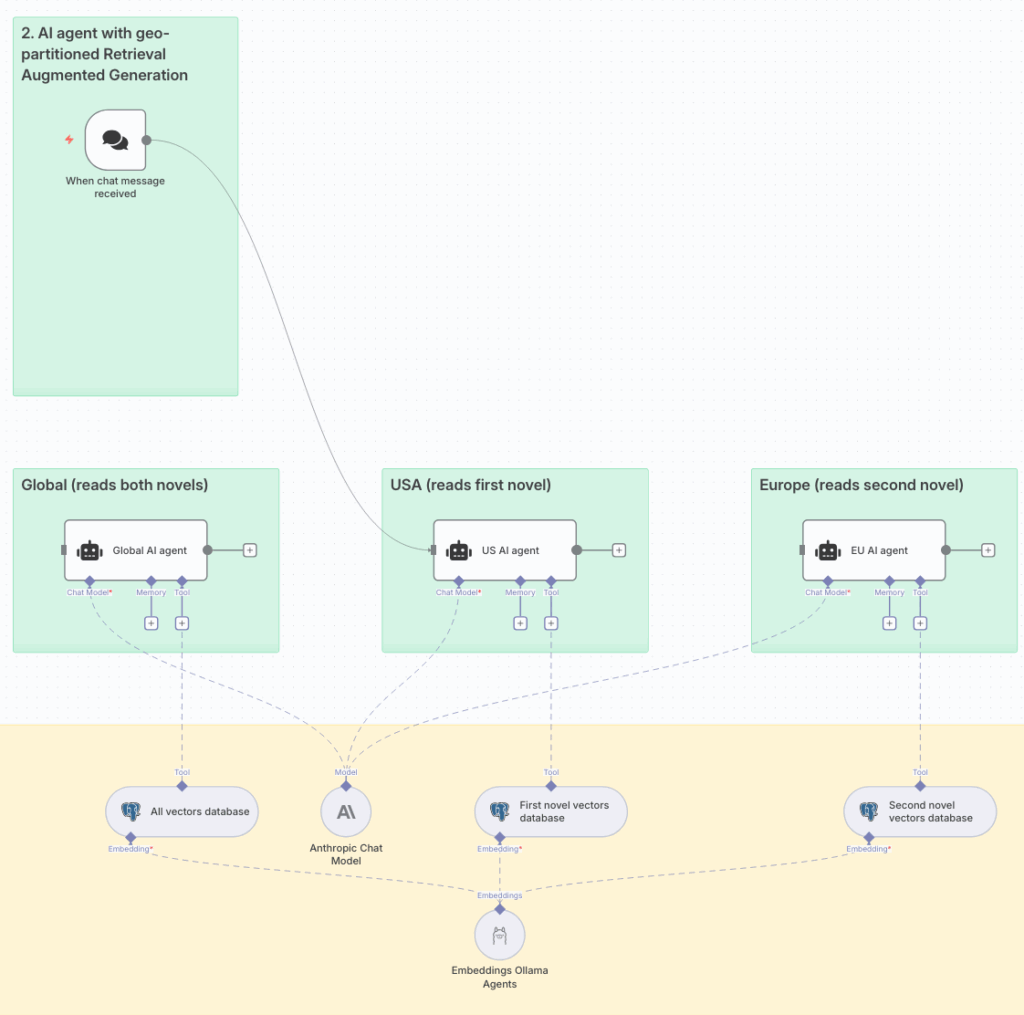
USA Chapter
With the chat trigger connected to the USA AI agent, a question related to the first novel, The Adventures of Sherlock Holmes, is asked:
Where does Mr St Clair live?
The AI agent uses its assigned tool, access to the YugabyteDB vector database, to help add context. It composes the query St Clair residence address and asks YugabyteDB to carry out a semantic search.
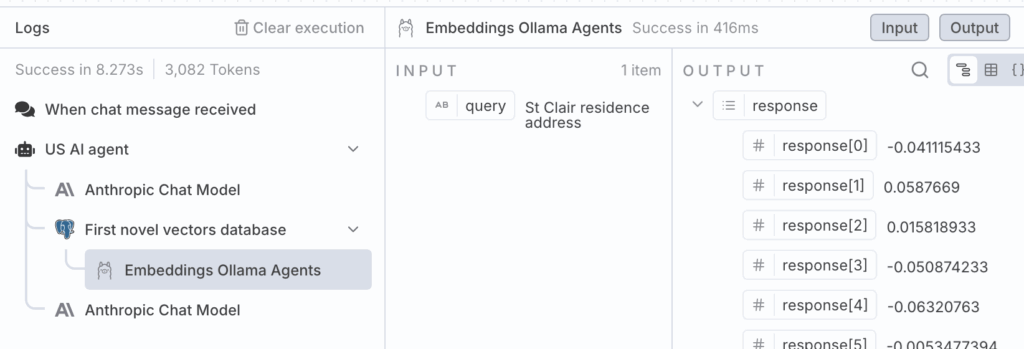
The agent’s response with this augmented context is extremely accurate. Notably, it has identified text from the novel despite the text not including the words address or residence from the query.
Based on the search results, I found that Mr. Neville St. Clair lived in Lee. Specifically, the text mentions that “Some years ago—to be definite, in May, 1884—there came to Lee a gentleman, Neville St. Clair by name, who appeared to have plenty of money. He took a large villa, laid out the grounds very nicely, and lived generally in good style.”
The details indicate that he:
- Moved to Lee in May 1884
- Purchased a large villa
- Was married to the daughter of a local brewer by 1887
- Had two children
- Commuted daily to town, returning by the 5:14 train from Cannon Street
So his primary residence was a large villa in the area of Lee, which is a district in south-east London.
Europe Chapter
When the chat trigger is connected to the Europe AI agent, it only has access to vectors from the second novel, The Return of Sherlock Holmes, and not the first.
The AI agent’s LLM may have access to broader information from the novel as part of its wide training corpus, but not a complete copy of the text that it can interrogate:
I apologize, but after multiple searches, I cannot find the specific address of Mr. St. Clair’s residence in the novel. The story “The Man with the Twisted Lip” mentions Neville St. Clair, but the exact details of his home address are not provided in the search results. What I can recall from the story is that he lived in a respectable suburban area with his wife and children, but the precise location is not specified in these vector database results. If you’d like more specific information, you might want to refer to the full text of the story directly.
Conclusion
Retrieval Augmented Generation (RAG) gives AI agents access to your organization’s private knowledge, delivering faster, more accurate, and context-rich outputs.
YugabyteDB provides enterprise-grade scalability, resilience, and data sovereignty, all while managing both structured and vector data on a single, PostgreSQL-compatible platform.
The result? AI that can instantly produce critical insights, improve decision-making, and boost productivity across your business.
Want to know how to build GenAI apps on a PostgreSQL-compatible database? Download our solution brief to discover basic AI concepts, architectural considerations, plus access to hands-on tutorials that demonstrate how to build your first GenAI application on various platforms.


