Database Connection Management: Exploring Pools and Performance
February 23, 2022
There are many secrets to creating a high-performing database application. One such secret is proper database connection management. However, this secret is not specific to YugabyteDB or PostgreSQL, but applies to any database.
In this post, we examine database connection management through the lens of YugabyteDB. We explore pools and performance, and run tests to measure the results. By the end of this post, you’ll have a clear sense of how to make efficient use of database connection management.
Obtaining a fixed number of connections
For any application that uses a database, it’s important to get a fixed number of connections to the database. You can then keep these connections connected and use prepared statements via the same connection whenever possible. This eliminates the overhead of (re)creating new connections. It also allows the connection to build up cached metadata to reduce query overhead and build up cached data, all to help with query execution.
But sadly, this is not always possible. Sometimes an application reconnects for performing repeated database transactions, which cannot be changed. This causes increased execution latencies, because the latency of creating a connection is an integral part of each execution.
The YugabyteDB master process obtains a minimal set of catalog data when a new connection is created with YugabyteDB YSQL. This adds to the connection creation latency. We even created a GitHub issue to better understand this behavior.
External connection pooler: PgBouncer
Luckily, there is a way to relieve the connection latency for repeated created connections: PgBouncer. PgBouncer is a middleware product that can create a pool of connections to the database, and also keep a pool of connections from applications. Because it can keep the connections to the database alive when an application connection ends, it can overcome the latency of creating a new database connection.
In order to assess if PgBouncer would be beneficial for your specific use case, investigate if your application closes and opens connections frequently, and specifically if opening connections adds to user latency. If it does, PgBouncer is likely to lower these latencies by reusing database connections.
An example of the latency differences
For the sake of simplicity and reproducibility, we’ll use YugabyteDB’s ysql_bench, which is a Yugabyte recompilation of PostgreSQL’s standard benchmark tool pg_bench. This executes against a YugabyteDB database.
Setup the benchmark schema
$ ysql_bench --initialize --scale=5 --host=$(hostname) dropping old tables... creating tables (with primary keys)... generating data... 100000 of 500000 tuples (20%) done (elapsed 5.64 s, remaining 22.55 s) 200000 of 500000 tuples (40%) done (elapsed 11.26 s, remaining 16.90 s) 300000 of 500000 tuples (60%) done (elapsed 16.97 s, remaining 11.32 s) 400000 of 500000 tuples (80%) done (elapsed 25.64 s, remaining 6.41 s) 500000 of 500000 tuples (100%) done (elapsed 33.17 s, remaining 0.00 s) done.
Run 1: Every transaction creates a new connection
$ ysql_bench --connect --client=1 --time=60 --no-vacuum --select-only --host=$(hostname) transaction type: <builtin: select only> scaling factor: 5 query mode: simple number of clients: 1 number of threads: 1 batch size: 1024 duration: 60 s number of transactions actually processed: 313 maximum number of tries: 1 latency average = 191.734 ms tps = 5.215567 (including connections establishing) tps = 14.817343 (excluding connections establishing)
Run 2: All transactions reuse the connection
$ ysql_bench --client=1 --time=60 --no-vacuum --select-only --host=$(hostname) transaction type: <builtin: select only> scaling factor: 5 query mode: simple number of clients: 1 number of threads: 1 batch size: 1024 duration: 60 s number of transactions actually processed: 87683 maximum number of tries: 1 latency average = 0.684 ms tps = 1461.368235 (including connections establishing) tps = 1464.336935 (excluding connections establishing)
This perfectly outlines the benefits of doing proper database connection management. By reusing the connection instead of reconnecting, the average time of a transaction went from 191ms to 0.7ms. More specifically, that’s a 250x improvement!
Installing PgBouncer on Centos 7
For starters, install the PgBouncer RPM. PgBouncer is available in the EPEL repository. To add the EPEL repository, execute:
$ sudo yum install epel-release
Then install PgBouncer:
$ sudo yum install pgbouncer
Set secrets in userlist.txt
For PgBouncer to be able to log on to a database before a user has connected and provided its password, it needs to be able to authenticate. This is done via a file that hosts the username and the encrypted password:
yugabyte=# select rolpassword from pg_authid where rolname = 'yugabyte'; rolpassword ------------------------------------- md52c2dc7d65d3e364f08b8addff5a54bf5 $ sudo vi /etc/pgbouncer/userlist.txt "yugabyte" "md52c2dc7d65d3e364f08b8addff5a54bf5"
Configure the PgBouncer configuration files
Now PgBouncer must be configured. First, copy the original pgbouncer.ini file to save it:
[centos@ip-172-158-33-218 ~]$ sudo cp /etc/pgbouncer/pgbouncer.ini /etc/pgbouncer/pgbouncer.ini.orig
Next, create a pgbouncer.ini file for our database:
$ sudo vi /etc/pgbouncer/pgbouncer.ini [databases] yugabyte = host=ip-172-158-33-218.eu-central-1.compute.internal port=5433 [pgbouncer] listen_port = 6432 listen_addr = * # admin users can use the pgbouncer special database admin_users = yugabyte stats_users = yugabyte auth_type = md5 auth_file = /etc/pgbouncer/userlist.txt logfile = /var/log/pgbouncer/pgbouncer.log pidfile = /var/run/pgbouncer/pgbouncer.pid pool_mode = transaction # max number of client side connections max_client_conn = 1000 # default pool size. this limits db connections below default_pool_size = 4 # min pool size. size to reduce pool to when idle. # keep this high so connection bursts can be serviced. min_pool_size = 4 # max number of connection per database max_db_connections = 100 # pools are administered per user - database pair. #min_pool_size = 100 # maximum idle time for server (database connection) server_idle_timeout = 600 # how long is a client willing to wait for its query to be executed # if you want activity to be queued and not killed! query_wait_timeout = 600 # verbosity. increase (5?) for debugging verbose = 0
Please keep in mind that this file contains settings specific to our test instance, such as the hostname in the databases section. You might want to adjust these in addition to settings like connections and application pool sizes.
Enable and start the PgBouncer via systemd
Now that everything is configured, let’s enable autostart for PgBouncer:
$ sudo systemctl enable pgbouncer Created symlink from /etc/systemd/system/multi-user.target.wants/pgbouncer.service to /usr/lib/systemd/system/pgbouncer.service.
And start the systemd unit:
$ sudo systemctl start pgbouncer
And validate it started successfully:
$ sudo systemctl status pgbouncer ● pgbouncer.service - A lightweight connection pooler for PostgreSQL Loaded: loaded (/usr/lib/systemd/system/pgbouncer.service; enabled; vendor preset: disabled) Active: active (running) since Mon 2021-05-24 10:30:01 UTC; 25s ago Docs: man:pgbouncer(1) Main PID: 28400 (pgbouncer) CGroup: /system.slice/pgbouncer.service └─28400 /usr/bin/pgbouncer -q /etc/pgbouncer/pgbouncer.ini May 24 10:30:01 ip-172-158-33-218.eu-central-1.compute.internal systemd[1]: Started A lightweight connection pooler for PostgreSQL. May 24 10:30:01 ip-172-158-33-218.eu-central-1.compute.internal systemd[1]: Starting A lightweight connection pooler for PostgreSQL...
Retest ysql_bench latency with PgBouncer
ysql_bench must be configured in order to use PgBouncer. This is achieved by pointing it to port 6432 (listen_port in pgbouncer.ini).
$ ysql_bench --connect --client=1 --time=60 --no-vacuum --select-only --host=$(hostname) --port=6432 Password: transaction type: <builtin: select only> scaling factor: 5 query mode: simple number of clients: 1 number of threads: 1 batch size: 1024 duration: 60 s number of transactions actually processed: 12657 maximum number of tries: 1 latency average = 5.116 ms tps = 195.473238 (including connections establishing) tps = 1356.775499 (excluding connections establishing)
Conclusion
Let’s look at the differences between the runs:
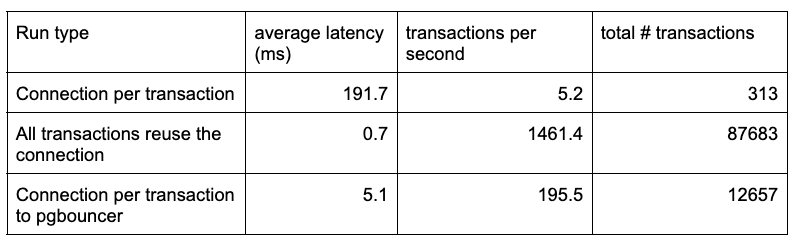
As you can see, single transaction connections are bad for performance. The best way to make efficient use of database connection management is to use a dedicated number of connections, which do not terminate and reconnect dynamically. If your application performs a lot of connection creation and termination, and it cannot be changed, then you can overcome the latency of creating a YSQL backend with PgBouncer. But using PgBouncer still adds overhead since a connection still has to be established.
Finally, since YugabyteDB is a distributed SQL database, the most obvious use of PgBouncer as a connection pool would be on each YSQL node. PgBouncer creates a pool of connections to a single username-database combination. If you want PgBouncer to connect to multiple hosts serving the same database, the HAProxy tool should be added. However, then it makes more sense to move PgBouncer to the application layer. PgBouncer can then connect to HAProxy, which will connect to multiple hosts in a round-robin fashion. There are many possible options—pick one that serves your needs in the best way possible.
Take YugabyteDB for a spin by downloading the latest version of the open source. Any questions? Ask them in the YugabyteDB community Slack channel.


